Hadoop2的FN安装(federated namespace)
尝试了简单的安装hadoop2后,我们再来尝试一下hdfs的一项新功能:FN。这项技术可以解决namenode容量不足的问题。它采用多个namenode来共享datanode的方式,每个namenode属于不同的namespace。
下面是我们的安装信息
Hadoop 版本:2.2.0
OS 版本: Centos6.4
Jdk 版本: jdk1.6.0_32
机器配置
|
机器名 |
Ip地址 |
功能 |
|
Hadoop1 |
192.168.124.135 |
NameNode, DataNode, ResourceManager, NodeManager |
|
Hadoop2 |
192.168.124.136 |
NameNode DataNode, NodeManager |
|
Hadoop3 |
192.168.124.137 |
DataNode, NodeManager |
配置
vi etc/hadoop/hadoop-env.sh 修改jdk位置
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi etc/hadoop/mapred-env.sh修改jdk位置
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi etc/hadoop/yarn-env.sh修改jdk位置
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/repo2/tmp</value>
<description>A base for other temporary
directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
</configuration>
vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/repo2/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/repo2/data</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>hadoop1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>hadoop1:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>hadoop1:50090</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>hadoop2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>hadoop2:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>hadoop2:50090</value>
</property>
</configuration>
vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<description>the valid service name</description>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
</configuration>
vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi etc/hadoop/slaves
hadoop1
hadoop2
hadoop3
格式化namenode
在hadoop1和hadoop2上运行:bin/hdfs namenode -format -clusterid mycluster
启动hadoop集群
cd /home/hadoop/hadoop-2.2.0
sbin/start-all.sh
从图上可以看出,先启动namenode,再启动datanode, 再启动secondarynamenode, 再启动resourcemanger, 最后启动nodemanager。
使用jps查看启动的进程
在hadoop1上运行jps
在hadoop2上运行jps
在hadoop3上运行jps

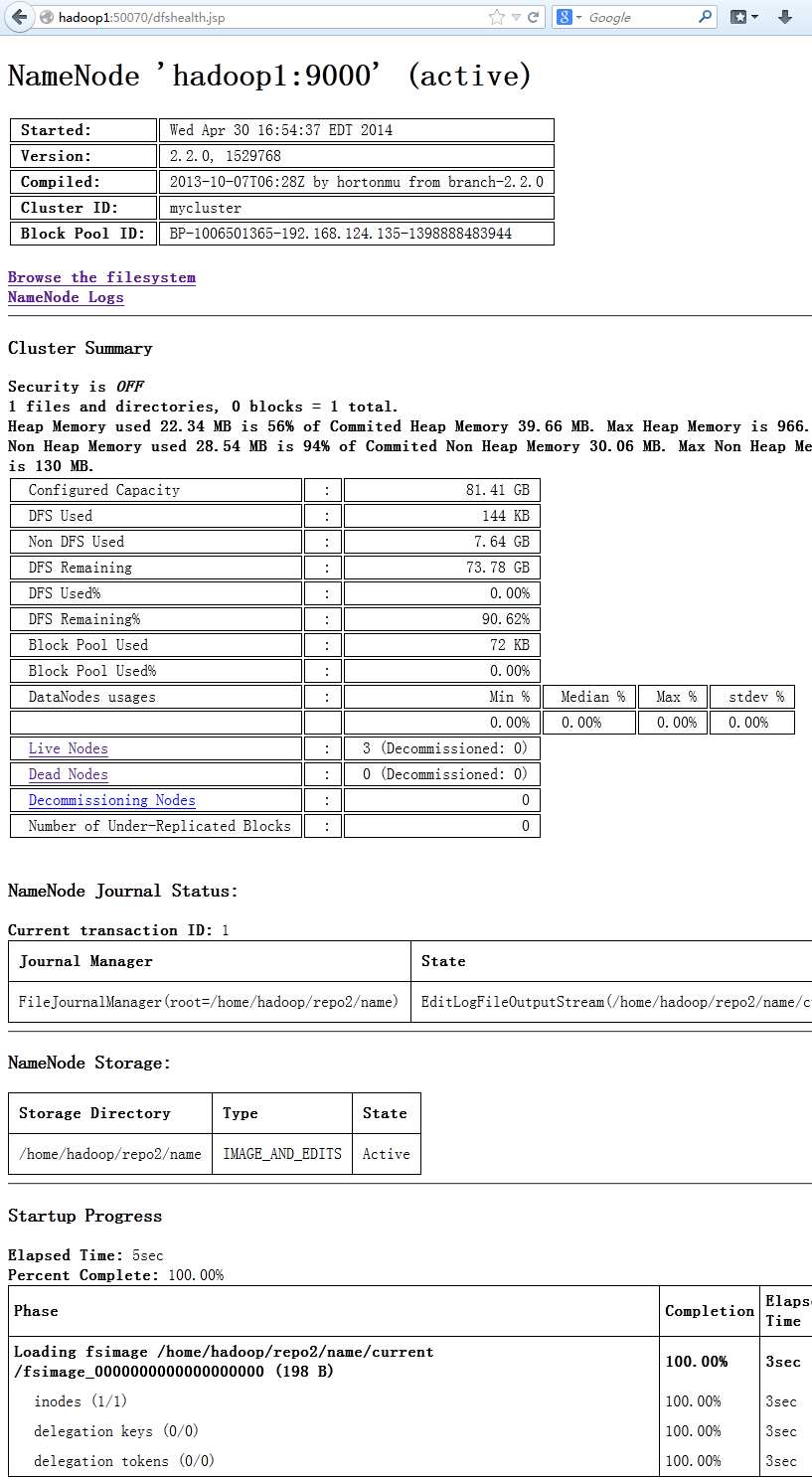
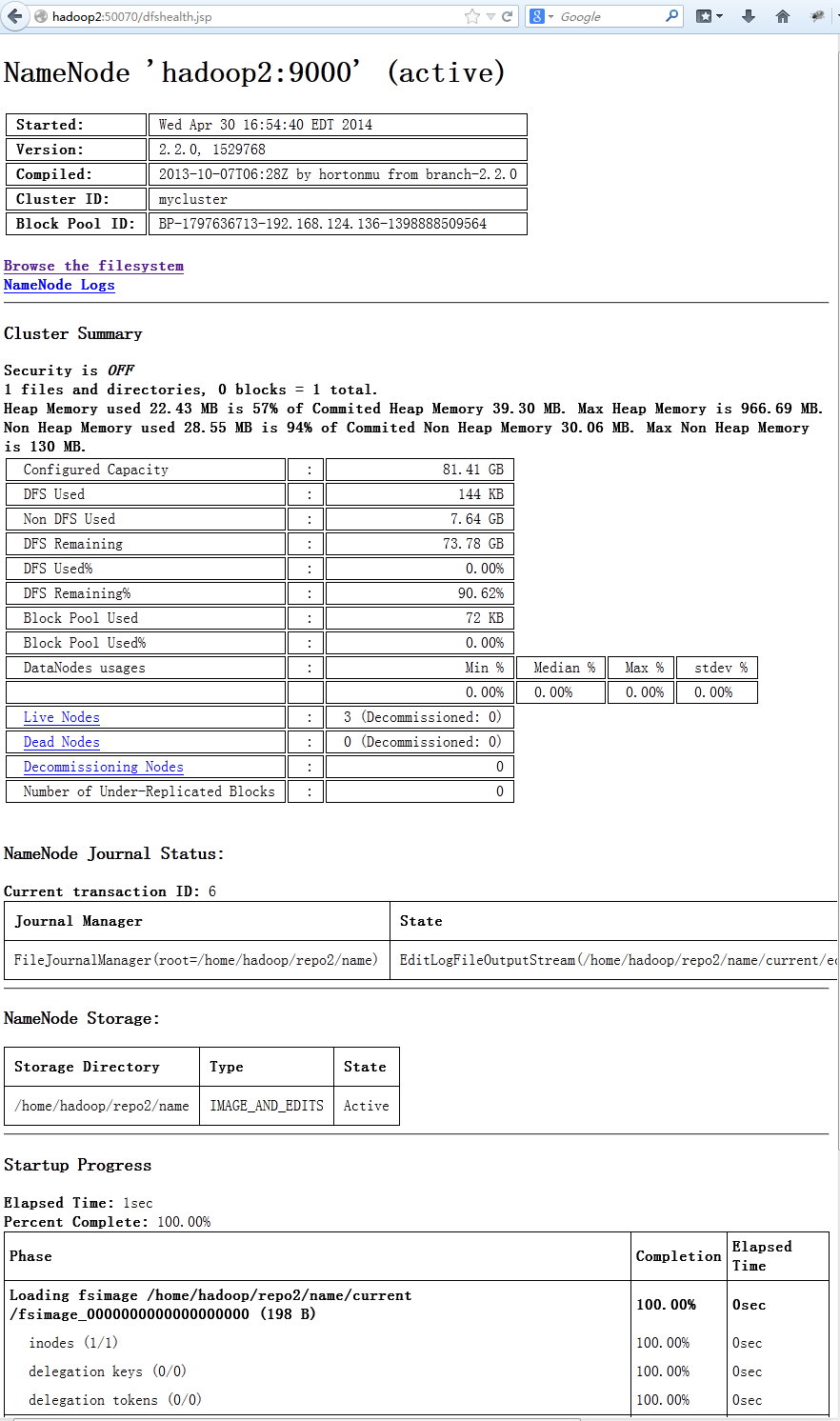
从图上可以看出hadoop2和hadoop1上的namenode都处于active状态,他们两个同时在线工作。
通过Hadoop的web界面可以看到,hadoop1和hadoop2都处于active状态,他们当前都是可以工作的,只是hadoop1工作在命名ns1,hadoop2工作在ns2上
在浏览器里输入http://hadoop1:50070
在浏览器里输入http://hadoop2:50070
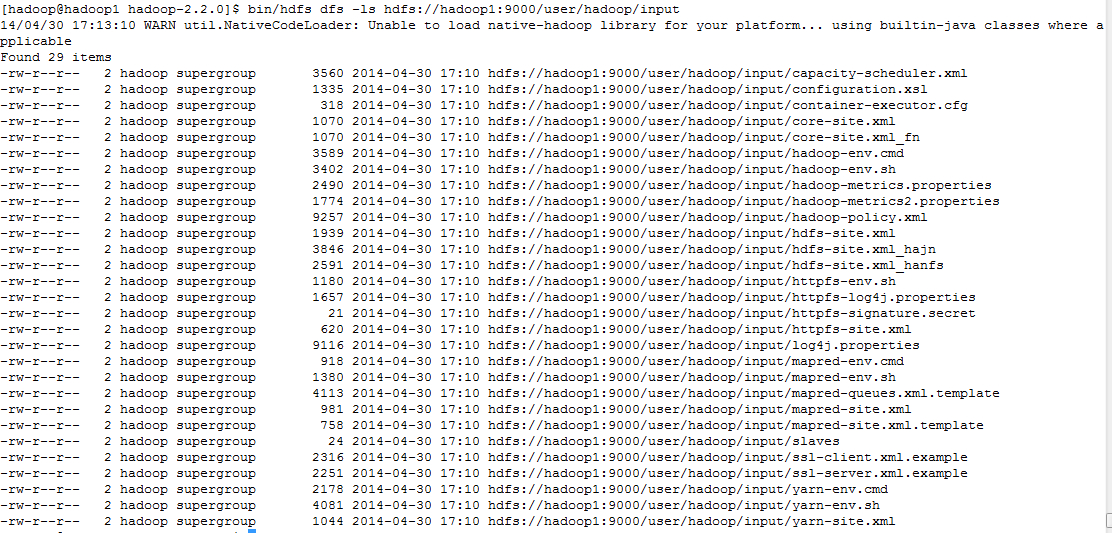
通过命令行看这两个namenode数据
bin/hdfs dfs -mkdir hdfs://hadoop1:9000/user/hadoop/input
bin/hdfs dfs -copyFromLocal etc/hadoop/* hdfs://hadoop1:9000/user/hadoop/input
bin/hdfs dfs -ls hdfs://hadoop1:9000/user/hadoop/input
bin/hdfs dfs -ls hdfs://hadoop2:9000/user/hadoop/input

从上面可以看出对hadoop1上的namenode操作,不会影响到hadoop2上的namenode,因此采用federated namespace可以存储两倍或者更多的metadata信息。当发现namespace空间成瓶颈时,可以再添加一台来扩展namespace空间。目前有一个小的问题,当添加一个namespace节点时,需要重启整个集群。通常工作中hadoop集群是不能重启的,这有可能将是一个问题。我认为解决这个问题不存在技术上的问题,可能在后面的版本中解决这个问题。
Hadoop2的FN安装(federated namespace)的更多相关文章
- Linux Hadoop2.7.3 安装(单机模式) 一
Linux Hadoop2.7.3 安装(单机模式) 一 Linux Hadoop2.7.3 安装(单机模式) 二 java环境安装 http://www.cnblogs.com/zeze/p/590 ...
- Apache Hadoop2.x 边安装边入门
完整PDF版本:<Apache Hadoop2.x边安装边入门> 目录 第一部分:Linux环境安装 第一步.配置Vmware NAT网络 一. Vmware网络模式介绍 二. NAT模式 ...
- Linux Hadoop2.7.3 安装(单机模式) 二
Linux Hadoop2.7.3 安装(单机模式) 一 Linux Hadoop2.7.3 安装(单机模式) 二 YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的Jo ...
- Hadoop2.6.0安装 — 集群
文 / vincentzh 原文连接:http://www.cnblogs.com/vincentzh/p/6034187.html 这里写点 Hadoop2.6.0集群的安装和简单配置,一方面是为自 ...
- Hadoop第3周练习--Hadoop2.X编译安装和实验
作业题目 位系统下进行本地编译的安装方式 选2 (1) 能否给web监控界面加上安全机制,怎样实现?抓图过程 (2)模拟namenode崩溃,例如将name目录的内容全部删除,然后通过secondar ...
- hadoop2.7.1安装
Hadoop2.7.1安装与配置 http://www.oschina.net/question/117352_247251 http://www.cnblogs.com/wayne1017/arch ...
- Hadoop-2.4.0安装和wordcount执行验证
Hadoop-2.4.0安装和wordcount执行验证 下面描写叙述了64位centos6.5机器下,安装32位hadoop-2.4.0,并通过执行 系统自带的WordCount样例来验证服务正确性 ...
- hadoop2.5.2安装部署
0x00 说明 此处已经省略基本配置步骤参考Hadoop1.0.3环境搭建流程,省略主要步骤有: 建立一般用户 关闭防火墙和SELinux 网络配置 0x01 配置master免密钥登录slave 生 ...
- Hadoop2.2.0安装过程记录
1 安装环境1.1 客户端1.2 服务端1.3 安装准备 2 操作系统安装2.1.1 BIOS打开虚拟化支持2.1.2 关闭防火墙2.1.3 安装 ...
随机推荐
- for in 与 Object.keys 与 hasOwnProperty区别
1.结论 for in遍历对象所有可枚举属性 包括原型链上的属性 Object.keys遍历对象所有可枚举属性 不包括原型链上的属性 hasOwnProperty 检查对象是否包含属性名,无法检查原型 ...
- RGB和HSL色彩的相互转换
转自: http://blog.csdn.net/aniven/article/details/2205851 RGB和HSL(也叫HSB/HSV)是两种色彩空间,即:红,绿,蓝(Red,Green, ...
- java 学习总结
1 cobertura-maven-plugin maven的测试覆盖率插件集成cobertura-maven-plugin2 intelli J 配置VM参数 3 配置显示行号 mvn clean ...
- redis可视化工具的安装和调试
Redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set ...
- Linux-进程、进程组、作业、会话、控制终端详解
一.进程 传统上,Unix操作系统下运行的应用程序. 服务器以及其他程序都被称为进程,而Linux也继承了来自unix进程的概念.必须要理解下,程序是指的存储在存储设备上(如磁盘)包含了可执行机器指 ...
- input text 去掉标签下拉提示autocomplete
autocomplete 属性 autocomplete 属性规定输入字段是否应该启用自动完成功能. 自动完成允许浏览器预测对字段的输入.当用户在字段开始键入时,浏览器基于之前键入过的值,应该显示出在 ...
- 深入理解linux系统的目录结构
对于每一个Linux学习者来说,了解Linux文件系统的目录结构,是学好Linux的至关重要的一步.,深入了解linux文件目录结构的标准和每个目录的详细功能,对于我们用好linux系统只管重要,下面 ...
- easyui 动态加载语言包
解决办法是:把语言包中的语言类型写到cookie,动态修改cookie中的语言名称,修改完后重新渲染一下页面. 在页面加载完成后,先判断cookie存不存在,如果不存在就写入默认语言,存在就给easy ...
- Android面试常问到的知识点
一.算法,数据结构 1.排序算法 2.查找算法 3.二叉树 4.广度,深度算法: 二.java基础 1.集合Collection,List,Map等常用方法,特点,关系: 2.线程的同步,中断方式有几 ...
- 各种MQTT server功能比較
this page attempts to document the features that various MQTT servers (brokers) support. This is spe ...