Python爬虫【一】爬虫的基本原理
一、爬虫基本原理
1.获取网络数据
用户方式:浏览器提交请求->下载网页代码->解析/渲染成页面
爬虫方式:模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中
2.爬虫的基本原理
向网站发起请求,获取资源后分析并提取有用数据的程序
3.爬虫的基本流程
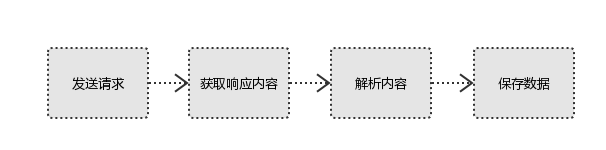
#1、发起请求
使用http库向目标站点发起请求,即发送一个Request,Request包含:请求头、请求体等
#2、获取响应内容
如果服务器能正常响应,则会得到一个Response,Response包含:html,json,图片,视频等
#3、解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以b的方式写入文件
#4、保存数据
数据库,文件
4.request和response
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
5.Request
#1、请求方式:
常用的请求方式:GET,POST
其他请求方式:HEAD,PUT,DELETE,OPTHONS ps:用浏览器演示get与post的区别,(用登录演示post) post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
post请求的参数放在请求体内:
可用浏览器查看,存放于form data内
get请求的参数直接放在url后 #2、请求url
url全称统一资源定位符,如一个网页文档,一张图片
一个视频等都可以用url唯一来确定 url编码
https://www.baidu.com/s?wd=图片
图片会被编码(看示例代码) 网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求 #3、请求头
User-agent:请求头中如果没有user-agent客户端配置,
服务端可能将你当做一个非法用户
host
cookies:cookie用来保存登录信息 一般做爬虫都会加上请求头 #4、请求体
如果是get方式,请求体没有内容
如果是post方式,请求体是format data ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
6.Response
#1、响应状态
200:代表成功
301:代表跳转
404:文件不存在
403:权限
502:服务器错误 #2、Respone header
set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来 #3、preview就是网页源代码
最主要的部分,包含了请求资源的内容
如网页html,图片
二进制数据等
Python爬虫【一】爬虫的基本原理的更多相关文章
- python应用之爬虫实战1 爬虫基本原理
知识内容: 1.爬虫是什么 2.爬虫的基本流程 3.request和response 4.python爬虫工具 参考:http://www.cnblogs.com/linhaifeng/article ...
- 【网络爬虫】【python】网络爬虫(四):scrapy爬虫框架(架构、win/linux安装、文件结构)
scrapy框架的学习,目前个人觉得比较详尽的资料主要有两个: 1.官方教程文档.scrapy的github wiki: 2.一个很好的scrapy中文文档:http://scrapy-chs.rea ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python 开发轻量级爬虫04
Python 开发轻量级爬虫 (imooc总结04--url管理器) 介绍抓取URL管理器 url管理器用来管理待抓取url集合和已抓取url集合. 这里有一个问题,遇到一个url,我们就抓取它的内容 ...
- Python 开发轻量级爬虫03
Python 开发轻量级爬虫 (imooc总结03--简单的爬虫架构) 现在来看一下一个简单的爬虫架构. 要实现一个简单的爬虫,有哪些方面需要考虑呢? 首先需要一个爬虫调度端,来启动爬虫.停止爬虫.监 ...
- Python 开发轻量级爬虫02
Python 开发轻量级爬虫 (imooc总结02--爬虫简介) 爬虫简介 首先爬虫是什么?它是一段自动抓取互联网信息的程序. 什么意思呢? 互联网由各种各样的的网页组成,每一个网页都有对应的url, ...
随机推荐
- IDEA与Elicpse
IDEA的项目 = Elicpse的工作区 Elicpse的项目 = IDEA的模块 修改信息提示 Alt+/ 关闭当前窗口 Ctrl+W
- css中 ~的作用
这是 CSS3 element1~element2 选择器 定义和用法 element1~element2 选择器 element1 之后出现的所有 element2. 两种元素必须拥有相同的父元素, ...
- Django-分页、中间件和请求的声明周期
一.分页 相关连接:https://www.cnblogs.com/kongzhagen/p/6640975.html 一.Django的分页器(paginator) 1.view.py 视图 fro ...
- Linux简单版重要安装步骤
1.稍后安装操作系统 2.自定义硬件 3.选择镜像(mini) 4.开机选择第一个 5.skip(跳过检测) 6.是,忽略所有数据 7.配置网络 8.设置root用户密码 9.使用所有空间 10.写入 ...
- openshift 调度命令
oc adm manage-node oc-node07 --schedulable=true #可调度 oc adm manage-node oc-node07 --schedulable=fal ...
- 【LeetCode每天一题】Substring with Concatenation of All Words(具备列表中所有单词的字串)
You are given a string, s, and a list of words, words, that are all of the same length. Find all sta ...
- [LeetCode] 613. Shortest Distance in a Line_Easy tag: SQL
Table point holds the x coordinate of some points on x-axis in a plane, which are all integers. Writ ...
- vue的图片路径,和背景图片路径打包后错误解决
最近在研究vue,老实的按照官网提供的,搭建的了 webpack+vue+vuex+vue-router,,因为是自己搭建的,所以踩了不少坑,一般问题百度都有,这个背景图片的问题,查了很久才解决. 1 ...
- vue中把table导出表格excel
1.首先下载2个js,我的百度网盘有 2.安装依赖 npm install -S file-saver xlsx(这里其实安装了2个依赖) npm install -D script-loader 3 ...
- 从零开始一起学习SLAM | 不推公式,如何真正理解对极约束?
自从小白向师兄学习了李群李代数和相机成像模型的基本原理后,感觉书上的内容没那么难了,公式推导也能推得动了,感觉进步神速,不过最近小白在学习对极几何,貌似又遇到了麻烦... 小白:师兄,对极几何这块你觉 ...