结合sklearn的可视化工具Yellowbrick:超参与行为的可视化带来更优秀的实现
https://blog.csdn.net/qq_34739497/article/details/80508262
Yellowbrick 是一套名为「Visualizers」的视觉诊断工具,它扩展了 Scikit-Learn API 以允许我们监督模型的选择过程。简而言之,Yellowbrick 将 Scikit-Learn 与 Matplotlib 结合在一起,并以传统 Scikit-Learn 的方式对模型进行可视化。
可视化器
可视化器(Visualizers)是一种从数据中学习的估计器,其主要目标是创建可理解模型选择过程的可视化。在 Scikit-Learn 的术语中,它们类似于转换器(transformer),其在可视化数据空间或包装模型估计器上类似「ModelCV」(例如 RidgeCV 和 LassoCV)方法的过程。Yellowbrick 的主要目标是创建一个类似于 Scikit-Learn 的 API,其中一些流行的可视化器包括:特征可视化
- Rank Features:单个或成对特征排序以检测关系
- Radial Visualization:围绕圆形图分离实例
- PCA Projection:基于主成分分析映射实例
- Manifold Visualization:通过流形学习实现高维可视化
- Feature Importances:基于模型性能对特征进行排序
- Recursive Feature Elimination:按重要性搜索最佳特征子集
- Scatter and Joint Plots:通过特征选择直接进行数据可视化
分类可视化
- Class Balance:了解类别分布如何影响模型
- Class Prediction Error:展示分类的误差与主要来源
- Classification Report:可视化精度、召回率和 F1 分数的表征
- ROC/AUC Curves:受试者工作曲线和曲线下面积
- Confusion Matrices:类别决策制定的视觉描述
- Discrimination Threshold:搜索最佳分离二元类别的阈值
回归可视化
- Prediction Error Plots:沿着目标域寻找模型崩溃的原因
- Residuals Plot:以残差的方式展示训练和测试数据中的差异
- Alpha Selection:展示 alpha 的选择如何影响正则化
聚类可视化
- K-Elbow Plot:使用肘法(elbow method)和多个指标来选择 k
- Silhouette Plot:通过可视化轮廓系数值来选择 k
模型选择可视化
- Validation Curve:对模型的单个超参数进行调整
- Learning Curve:展示模型是否能从更多的数据或更低的复杂性中受益
文本可视化
- Term Frequency:可视化语料库中词项的频率分布
- t-SNE Corpus Visualization:使用随机近邻嵌入来投影文档
实例
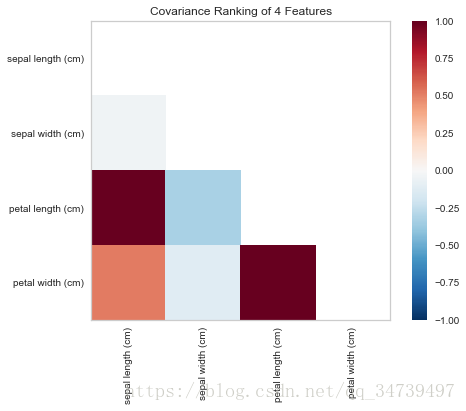
#特征之间协方差可视化
from yellowbrick.features import Rank2D
from sklearn.datasets import load_iris
data=load_iris()
visualizer = Rank2D(features=data['feature_names'], algorithm='covariance')
visualizer.fit(data['data'], data['target']) # Fit the data to the visualizer
visualizer.transform(data['data']) # Transform the data
visualizer.poof() # Draw/show/poof the data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
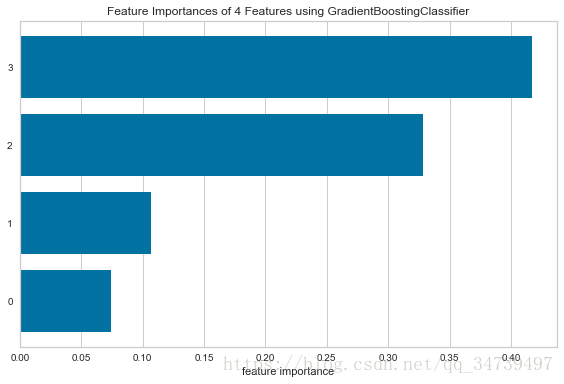
#梯度提升树中特征重要性可视化
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingClassifier
from yellowbrick.features import FeatureImportances
from sklearn.datasets import load_iris
data=load_iris()
fig = plt.figure()
ax = fig.add_subplot()
viz = FeatureImportances(GradientBoostingClassifier(), relative=False)
viz.fit(data['data'],data['target']) # Fit the data to the visualizer
viz.poof() # Draw/show/poof the data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
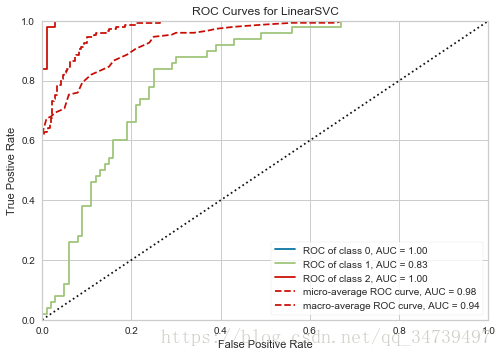
#线性支持向量机ROC曲线可视化
from sklearn.svm import LinearSVC
from yellowbrick.classifier import ROCAUC
model = LinearSVC()
model.fit(data['data'],data['target'])
visualizer = ROCAUC(model)
visualizer.score(data['data'],data['target'])
visualizer.poof()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
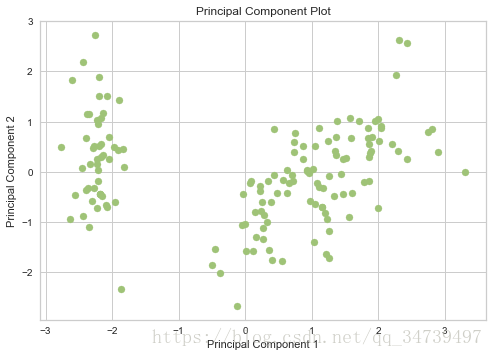
#主成分分析二维降维可视化
from yellowbrick.features.pca import PCADecomposition
visualizer = PCADecomposition(scale=True, center=False, color="g", proj_dim=2)
visualizer.fit_transform(data['data'],data['target'])
visualizer.poof()- 1
- 2
- 3
- 4
- 5
- 6
#线性支持向量机准确率、召回率、f1-score可视化
from sklearn.svm import LinearSVC
from yellowbrick.classifier import ClassificationReport
from sklearn.model_selection import train_test_split
model = LinearSVC()
X_train, X_test, y_train, y_test = train_test_split(data['data'],data['target'], test_size=0.2)
visualizer = ClassificationReport(model, classes=data['target_names'])
visualizer.fit(X_train, y_train) # Fit the visualizer and the model
visualizer.score(X_test, y_test) # Evaluate the model on the test data
g = visualizer.poof() # Draw/show/poof the data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
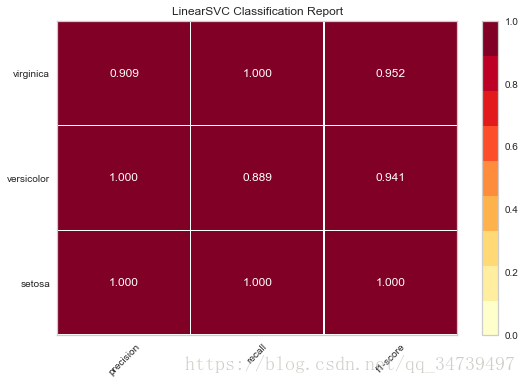
#alpha 的选择如何影响正则化可视化
import numpy as np
from sklearn.linear_model import LassoCV
from yellowbrick.regressor import AlphaSelection
# Create a list of alphas to cross-validate against
alphas = np.logspace(-10, 1, 400)#以10为底对数,-10到1分成400份
# Instantiate the linear model and visualizer
model = LassoCV(alphas=alphas)
visualizer = AlphaSelection(model)
visualizer.fit(data['data'],data['target'])
g = visualizer.poof()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
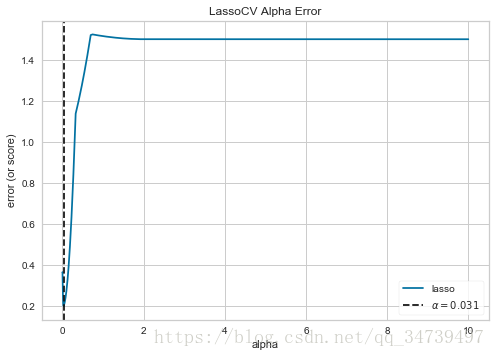
#肘部法则选择最佳聚类的k
from sklearn.cluster import MiniBatchKMeans
from yellowbrick.cluster import KElbowVisualizer
# Instantiate the clustering model and visualizer
visualizer = KElbowVisualizer(MiniBatchKMeans(), k=(4,12))
visualizer.fit(data["data"]) # Fit the training data to the visualizer
visualizer.poof() # Draw/show/poof the data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
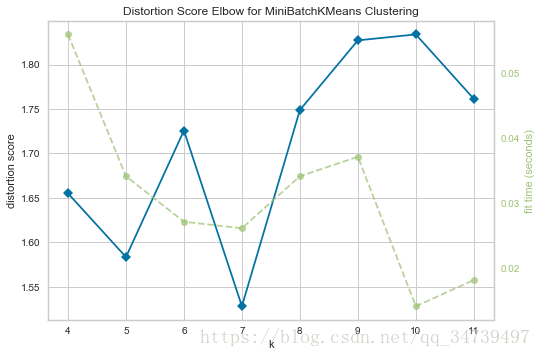
#训练集数量对模型表现可视化
import numpy as np
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import StratifiedKFold
from yellowbrick.model_selection import LearningCurve
# Create the learning curve visualizer
cv = StratifiedKFold(12)#k折交叉切分
sizes = np.linspace(0.3, 1.0, 10)
viz = LearningCurve(
MultinomialNB(), cv=cv, train_sizes=sizes,
scoring='f1_weighted', n_jobs=4
)
# Fit and poof the visualizer
viz.fit(data['data'],data['target'])
viz.poof()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
结合sklearn的可视化工具Yellowbrick:超参与行为的可视化带来更优秀的实现的更多相关文章
- 如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化展示
大前天我们通过Python网络爬虫对朋友圈的数据进行了抓取,感兴趣的朋友可以点击进行查看,如何利用Python网络爬虫抓取微信朋友圈的动态(上)和如何利用Python网络爬虫爬取微信朋友圈动态——附代 ...
- Linux 上的数据可视化工具
Linux 上的数据可视化工具 5 种开放源码图形化工具简介 Linux® 上用来实现数据的图形可视化的应用程序有很多,从简单的 2-D 绘图到 3-D 制图,再到科学图形编程和图形模拟.幸运的是,这 ...
- 数据库——可视化工具Navicat、pymysql模块、sql注入问题
数据库--可视化工具Navicat.pymysql模块.sql注入问题 Navicat可视化工具 Navicat是数据库的一个可视化工具,可直接在百度搜索下载安装,它可以通过鼠标"点点点&q ...
- Windows下Redis安装+可视化工具Redis Desktop Manager使用
Redis是有名的NoSql数据库,一般Linux都会默认支持.但在Windows环境中,可能需要手动安装设置才能有效使用.这里就简单介绍一下Windows下Redis服务的安装方法,希望能够帮到你. ...
- 开源来自百度商业前端数据可视化团队的超漂亮动态图表--ECharts
开源来自百度商业前端数据可视化团队的超漂亮动态图表--ECharts 本人项目中最近有需要图表的地方,偶然发现一款超级漂亮的动态图标js图表控件,分享给大家,觉得好用的就看一下.更多更漂亮的演示大家可 ...
- redis_学习_02_redis 可视化工具 Redis Desktop Manager
二.参考资料 1.Redis可视化工具Redis Desktop Manager使用 2.超好用的Redis管理及监控工具,使用后可大大提高你的工作效率!
- 【Python代码】TSNE高维数据降维可视化工具 + python实现
目录 1.概述 1.1 什么是TSNE 1.2 TSNE原理 1.2.1入门的原理介绍 1.2.2进阶的原理介绍 1.2.2.1 高维距离表示 1.2.2.2 低维相似度表示 1.2.2.3 惩罚函数 ...
- 可能这是Redis可视化工具最全的横向评测
1 命令行 不知道大家在日常操作redis时用什么可视化工具呢? 以前总觉得没有什么太好的可视化工具,于是问了一个业内朋友.对方回:你还用可视化工具?直接命令行呀,redis提供了这么多命令,操作起来 ...
- 企业必读:BI数据可视化工具选型
伴随着大数据时代的到来,企业对数据的需求从"IT主导的报表模式"转向"业务主导的自助分析模式",可视化BI工具也随之应运而生.面对如此众多的可视化BI工具,我们 ...
随机推荐
- jode反编译软件
1.下载 http://jode.sourceforge.net/(官网) https://sourceforge.net/projects/jode/files/(下载地址) 2.使用 下载的jod ...
- 请求&注解
@RequestMapping("/{page}") //获取路径中的page参数值 public String showPage(@PathVariable String pag ...
- CLR总览
Contents 第1章CLR的执行模型... 4 1.1将源代码编译成托管代码模块... 4 1.2 将托管模块合并成程序集... 6 1.3加载公共语言运行时... 7 1.4执行程序集的代码.. ...
- Dockerfile详解(一)
Dockerfile 用于自动化构建一个docker镜像.Dockerfile里有 CMD 与 ENTRYPOINT 两个功能咋看起来很相似的指令,开始的时候觉得两个互用没什么所谓,但其实并非如此: ...
- ROSETTA使用技巧随笔--蛋白蛋白对接
先写简略版,以后再详细写. 1. 对输入结构进行预处理(refine) $> relax.default.linuxgccrelease -in:file:s input_files/from_ ...
- redhat6.5 linux 安装mysql5.6.27
1.yum安装mysql(root身份),适用于红帽6.5 yum install mysql-server mysql-devel mysql -y 如没有配置yum,请参见博客:http://ww ...
- Spring @Value注解 and Spring Boot @ConfigurationProperties注解
一.Spring的@Value Spring EL表达式语言,支持在XML和注解中表达式,类是于JSP的EL表达式语言. 在Spring开发中经常涉及调用各种资源的情况,包含普通文件.网址.配置文件. ...
- Lepus(天兔)监控MySQL部署
http://www.dbarun.com/docs/lepus/install/lnmp/ 注意:xampp mysqldb-python版本太高会导致lepus白屏 apache版本最好选择2.2 ...
- ES6class
类的方法都定义在prototype对象上面,所以类的新方法可以添加在prototype对象上面.Object.assign方法可以很方便地一次向类添加多个方法. 类的内部所有定义的方法,都是不可枚举的 ...
- LeetCode28.实现strStr()
实现 strStr() 函数. 给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始).如果不存在,则返 ...