Hadoop之HDFS介绍
1. 概述
- HDFS是一种分布式文件管理系统。
- HDFS的使用场景:
- 适合一次写入,多次读出的场景,且不支持文件的修改;
- 适合用来做数据分析,并不适合用来做网盘应用;
1.2 优缺点
- 优点:
- 高容错性
- 适合处理大数据
- 缺点:
- 不适合**低延时*数据访问;
- 无法高效的对大量小文件进行存储;
- 不支持并发写入,文件随机修改:
- 一个文件只能有一个写,不允许多个线程同时写;
- 仅支持数据append(追加),不支持文件的随机修改。
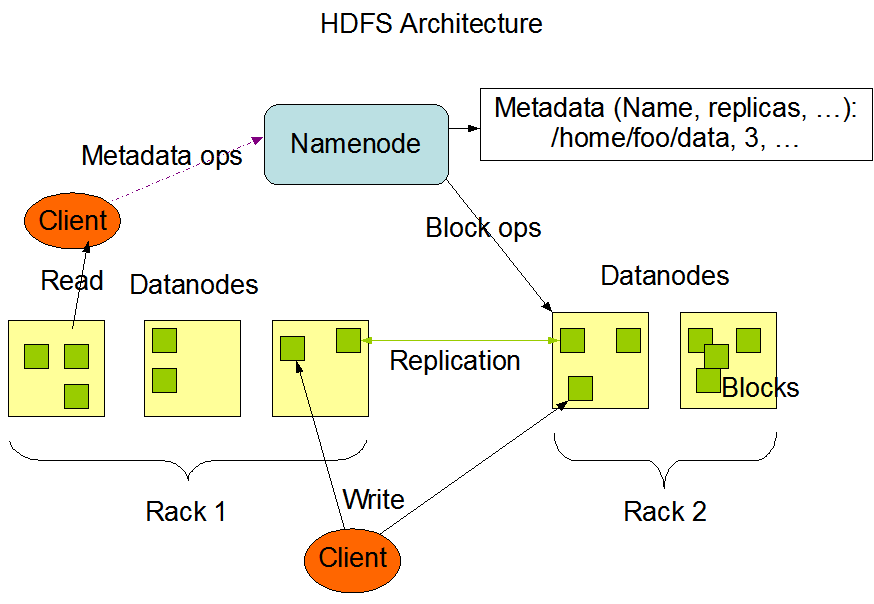
1.3 HDFS 组成架构
- NameNode(nn):
- 管理HDFS的名称空间;
- 配置副本策略;
- 管理数据块(Block)映射信息;
- 处理客户端读写请求;
- DataNode:NameNode下达命令,DataNode执行实际操作;
- 存储实际的数据块;
- 执行数据块的读/写操作;
- Client: 客户端
- 文件切分:文件上传到HDFS时,Client将文件切分成一个一个的Block,然后进行上传;
- 与NameNode交互,获取文件的位置信息;
- 与DataNode交互,读取或者写入数据;
- Client提供一些命令来管理HDFS,比如NameNode格式化;
- Client可以通过一些命令来访问HDFS,例如对HDFS进行增删改查操作;
- Secondary NameNode:并非NameNode的热备。当NameNode挂掉后,它并不能马上替换NameNode并提供服务;
- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
- 在紧急情况下,可辅助恢复NameNode;
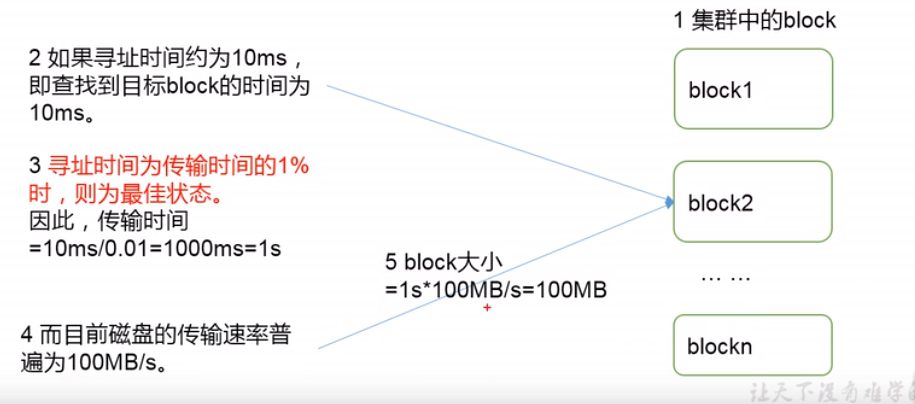
1.4 HDFS 文件块大小
- HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定
- 默认大小在Hadoop2.x版本是128M,老版本是64M;
- HDFS块的大小设置主要取决于磁盘传输速率。
2. HDFS的 Shell 操作
2.1 基本语法
bin/hadoop fs 基本命令bin/hadoop fs -getmerge /测试目录/* ./本地目录指定文件名.txt: 合并下载多个文件bin/hadoop fs -du -s -h /测试目录: 统计当前文件夹总的大小;bin/hadoop fs -du -h /测试目录: 统计当前文件夹各项的大小;
bin/hdfs dfs 基本命令: “dfs”是“fs”的实现类。
参考资料:
Hadoop之HDFS介绍的更多相关文章
- hadoop(一HDFS)
hadoop(一HDFS) 介绍 狭义上来说: hadoop指的是以下的三大系统: HDFS :分布式文件系统(高吞吐,没有延时要求,容错性,扩展能力) MapReduce : 分布式计算系统 Yar ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop介绍-3.HDFS介绍和YARN原理介绍
一. HDFS介绍: Hadoop2介绍 HDFS概述 HDFS读写流程 1. Hadoop2介绍 Hadoop是Apache软件基金会旗下的一个分布式系统基础架构.Hadoop2的框架最核心的 ...
- 介绍hadoop中的hadoop和hdfs命令
有些hive安装文档提到了hdfs dfs -mkdir ,也就是说hdfs也是可以用的,但在2.8.0中已经不那么处理了,之所以还可以使用,是为了向下兼容. 本文简要介绍一下有关的命令,以便对had ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- Hadoop之HDFS及NameNode单点故障解决方案
Hadoop之HDFS 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/QQ技术交流群:299142667 H ...
- Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdf ...
- Hadoop日记Day5---HDFS介绍
一.HDFS介绍 1.1 背景 随着数据量越来越大,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式 ...
随机推荐
- 【基础算法-树状数组】入门-C++
目录 基本定义 如何理解树状数组 主要操作 @ 基本定义 树状数组(Binary Indexed Tree(B.I.T), Fenwick Tree)是一个查询和修改复杂度都为log(n)的数据结构. ...
- kill函数
kill函数/命令产生信号 kill命令产生信号:kill -SIGKILL pid kill函数:给指定进程发送指定信号(不一定杀死) int kill(pid_t pid, int sig); ...
- mysql报错码code=exited,status=2的解决方案
由于电脑死机,导致MySQL无法重启. 解决方案看官方文档,设置完后重启失败,再把innodb_force_recovery = 1去掉就可以了 https://dev.mysql.com/doc/r ...
- redis之redis-cluster配置
为什么要用redis-cluster 并发问题 redis官方生成可以达到 10万/每秒,每秒执行10万条命令 假如业务需要每秒100万的命令执行呢? 数据量太大 一台服务器内存正常是16~256G, ...
- python 进程池和任务量变化测试
今天闲,测试了下concurrent.futures 模块中的ThreadPoolExecutor,ProcessPoolExecutor. 对开不同的数量的进程池和任务量时,所耗时间. from c ...
- 【java中的final关键字】
转自:https://www.cnblogs.com/xiaoxi/p/6392154.html 一.final关键字的基本用法 在Java中,final关键字可以用来修饰类.方法和变量(包括成员变量 ...
- Java实现单例的5种方式
1. 什么是单例模式 单例模式指的是在应用整个生命周期内只能存在一个实例.单例模式是一种被广泛使用的设计模式.他有很多好处,能够避免实例对象的重复创建,减少创建实例的系统开销,节省内存. 2. 单例模 ...
- Python 自学笔记(一)
1.打印函数 1-1.print()函数 1-1-1.引号的用法 一.单引号与双引号:直接输出 二.三引号:保留原来的格式 1-2.转义字符 转义字符是一种特殊的字符常量,在编程语言中,我们用转义字符 ...
- 【Java/JDBC】借助ResultSetMetaData,从数据库表中抽取字段信息存成Excel文件
本例工程下载:https://files.cnblogs.com/files/xiandedanteng/FindNotnullColumns20191102-3.rar 工作中曾有个为42张表建立测 ...
- C++ unique
#include <iostream>#include <algorithm>#include <list>#include <iterator>#in ...