[Spark内核] 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解
本课主题
- CacheManager 运行原理图
- CacheManager 源码解析
CacheManager 运行原理图
[下图是CacheManager的运行原理图]
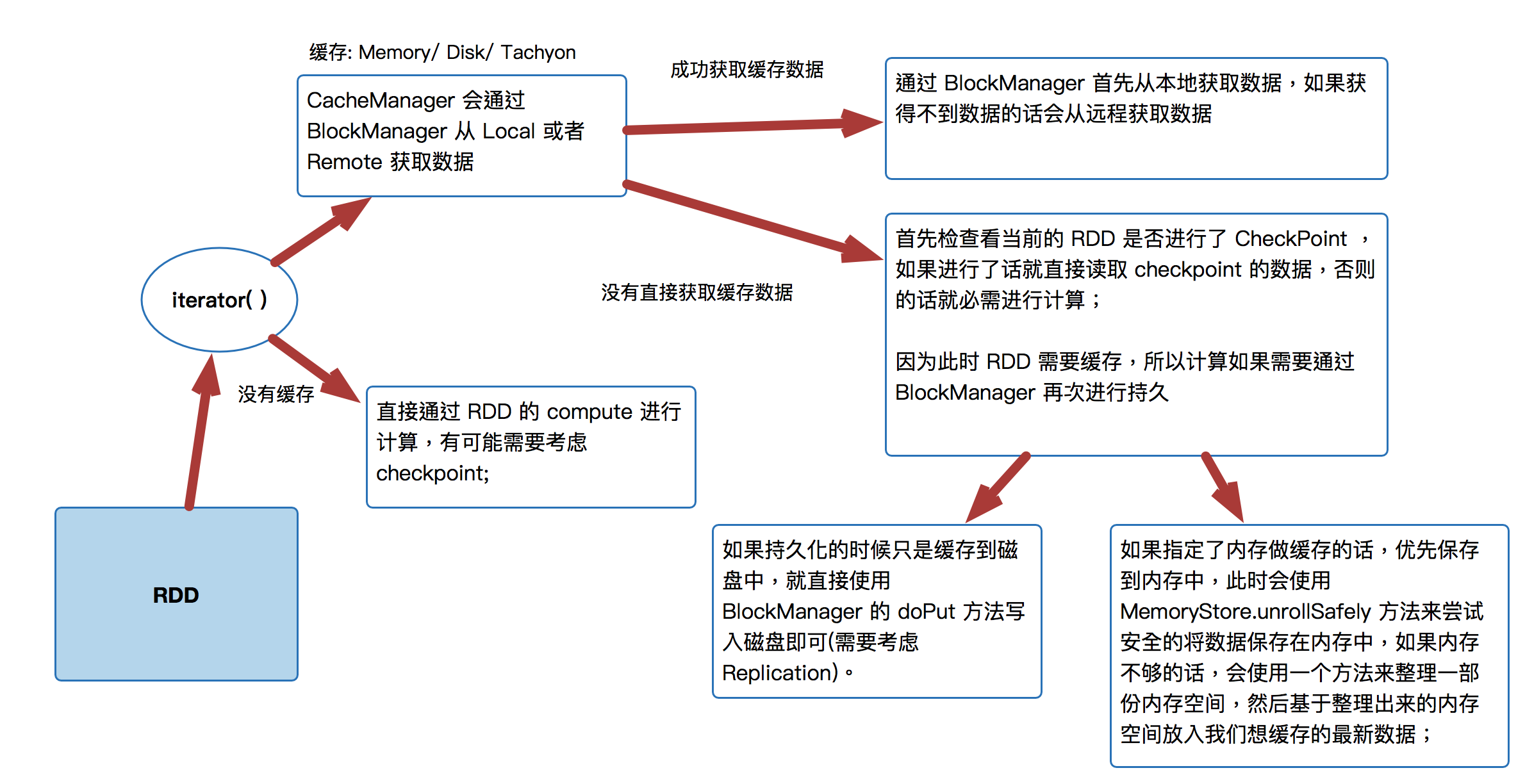
首先 RDD 是通过 iterator 来进行计算:
- CacheManager 会通过 BlockManager 从 Local 或者 Remote 获取数据直接通过 RDD 的 compute 进行计算,有可能需要考虑 checkpoint;
- 通过 BlockManager 首先从本地获取数据,如果获得不到数据的话会从远程获取数据
- 首先检查看当前的 RDD 是否进行了 CheckPoint ,如果进行了话就直接读取 checkpoint 的数据,否则的话就必需进行计算;因为此时 RDD 需要缓存,所以计算如果需要通过 BlockManager 再次进行持久
- 如果持久化的时候只是缓存到磁盘中,就直接使用 BlockManager 的 doPut 方法写入磁盘即可(需要考虑 Replication)。
- 如果指定了内存做缓存的话,优先保存到内存中,此时会使用MemoryStore.unrollSafely 方法来尝试安全的将数据保存在内存中,如果内存不够的话,会使用一个方法来整理一部份内存空间,然后基于整理出来的内存空间放入我们想缓存的最新数据;
- 直接通过 RDD 的 compute 进行计算,有可能需要考虑 checkpoint;
CacheManager 源码解析
- CacheManager 管理的是缓存中的数据,缓存可以是基于内存的缓存,也可以是基于磁盘的缓存;
- CacheManager 需要通过 BlockManager 来操作数据;
- 每当 Task 运行的时候会调用 RDD 的 Compute 方法进行计算,而 Compute 方法会调用 iterator 方法;
[下图是 MapPartitionRDD.scala 的 compute 方法]
这个方法是 final 级别不能覆写但可以被子类去使用,可以看见 RDD 是优先使用内存的,这个方法很关键!!如果存储级别不等于 NONE 的情况下,程序会先找 CacheManager 获得数据,否则的话会看有没有进行 Checkpoint
[下图是 RDD.scala 的 iterator 方法]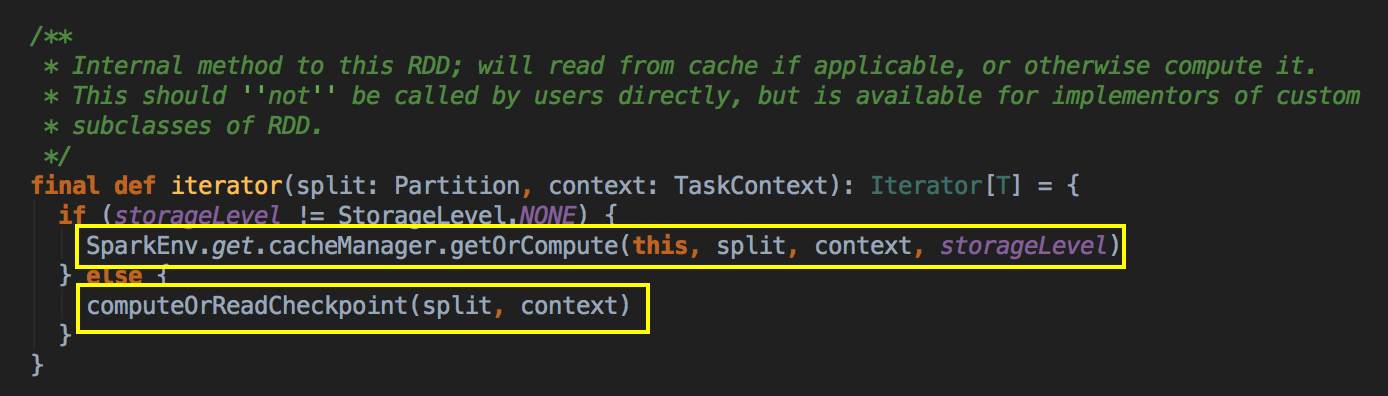
以下是 Spark 中的 StorageLevel
[下图是 StorageLevel.scala 的 StorageLevel 对象]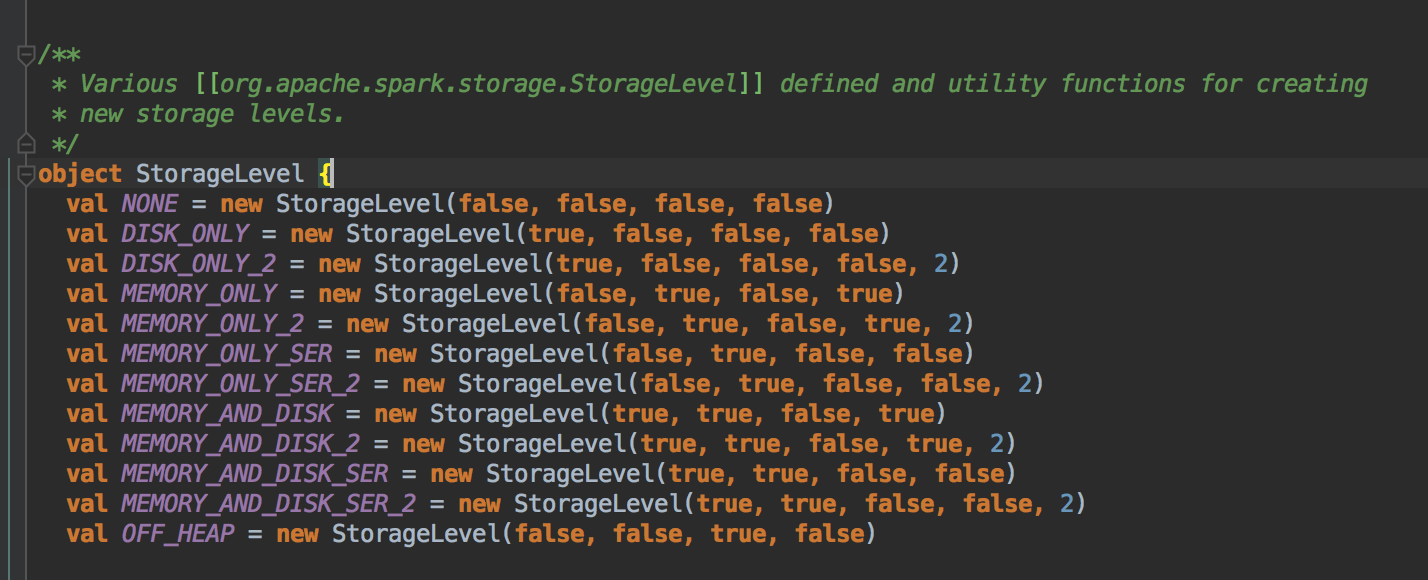
- Cache 在工作的时候会最大化的保留数据,但是数据不一定绝对完整,因为当前的计算如果需要内存空间的话,那么内存中的数据必需让出空间,这是因为执行比缓存重要!此时如何在RDD 持久化的时候同时指定了可以把数据放左Disk 上,那么部份 Cache 的数据可以从内存转入磁盘,否则的话,数据就会丢失!
假设现在 Cache 了一百万个数据分片,但是我下一个步骤计算的时候,我需要内存,思考题:你觉得是我现在需要的内存重要呢,还是你曾经 Cache 占用的空间重要呢?亳无疑问,肯定是现在计算重要。所以 Cache 占用的空间需要从内存中除掉,如果你程序的 StorageLevel 是 MEMEORY_AND_DISK 的话,这时候在内存可能是 Drop 到磁盘上,如果你程序的 StorageLevel 是 MEMEORY_ONLY 的话,那就会出去数据丢失的情况。
你进行Cache时,BlockManager 会帮你进行管理,我们可以通过 Key 到 BlockManager 中找出曾经缓存的数据。
[下图是 CacheManager.scala 的 getOrCompute 方法]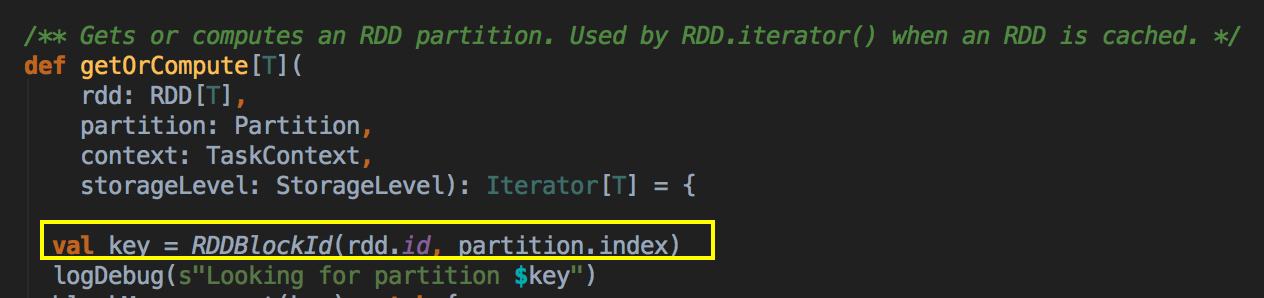
[下图是 CacheManager.scala 的 getOrCompute 方法内部具体的实现]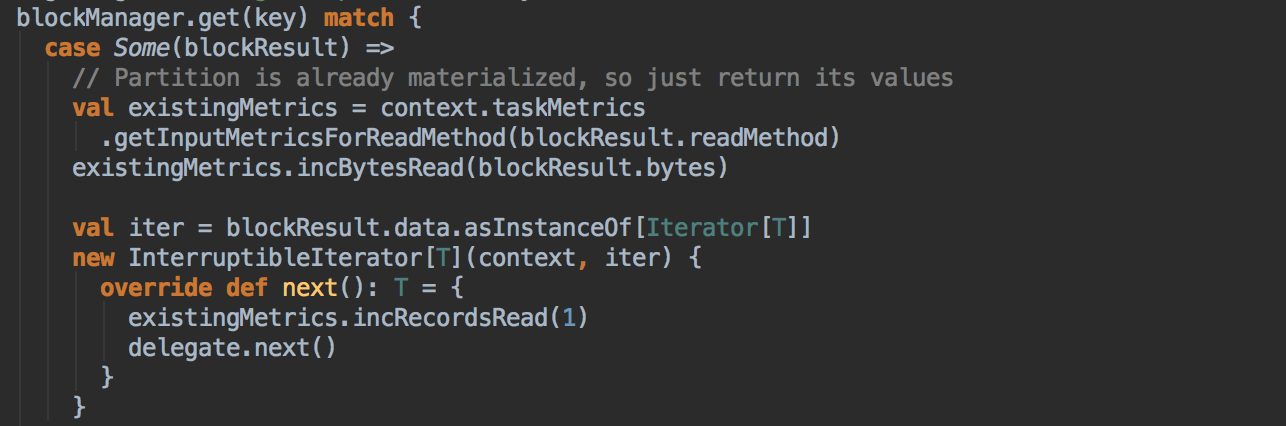
如果有 BlockManager.get() 方法没有返回任何数据,就调用 acquireLockForPartition 方法,因为会有可能多条线程在操作数据,Spark 有一个东西叫慢任务StraggleTask 推迟,StraggleTask 推迟的时候一般都会运行两个任务在两台机器上,你可能在你当前机器上没有发现这个内容,同时有远程也没有发现这个内容,只不过在你返回的那一刻,别人已经算完啦!
[下图是 CacheManager.scala 的 getOrCompute 方法内部具体的实现]
[下图是 CacheManager.scala 的 getOrCompute 方法内部具体的实现]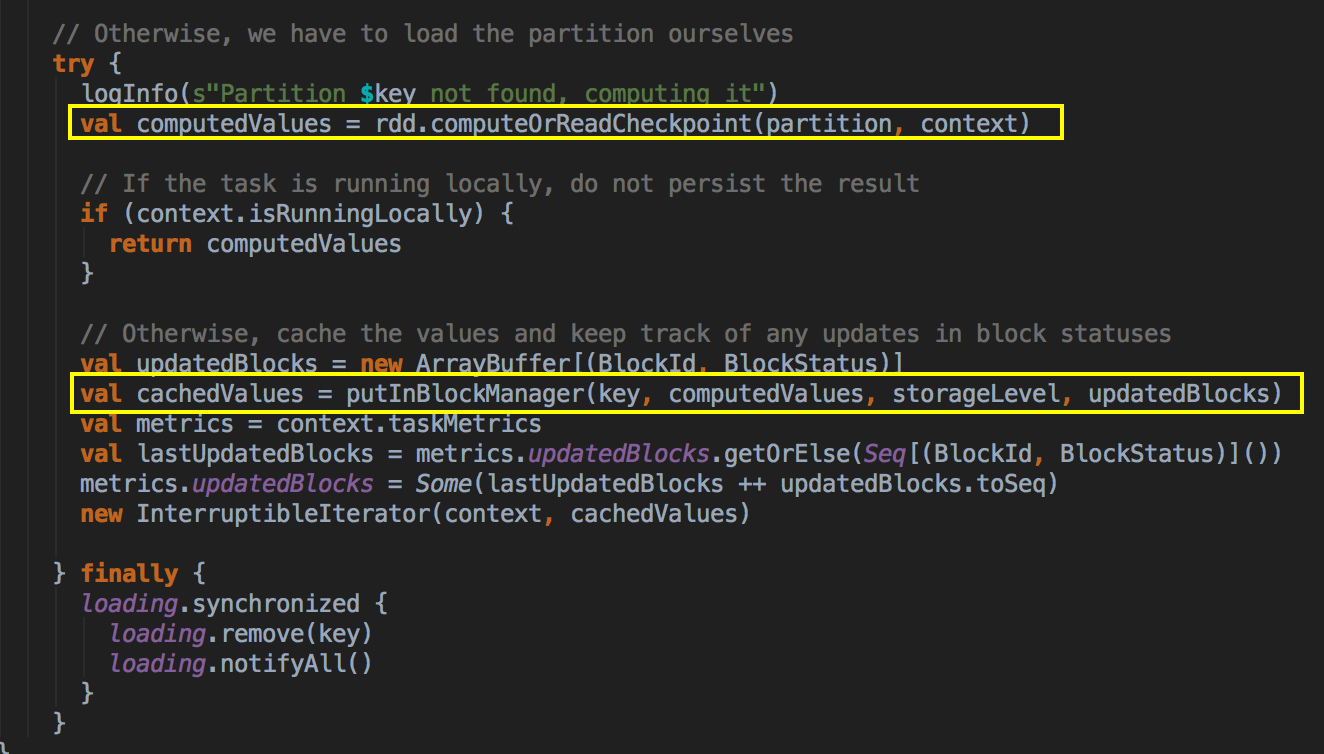
最后还是通过 BlockManager.get 来获得数据
[下图是 CacheManager.scala 的 acquireLockForPartition 方法]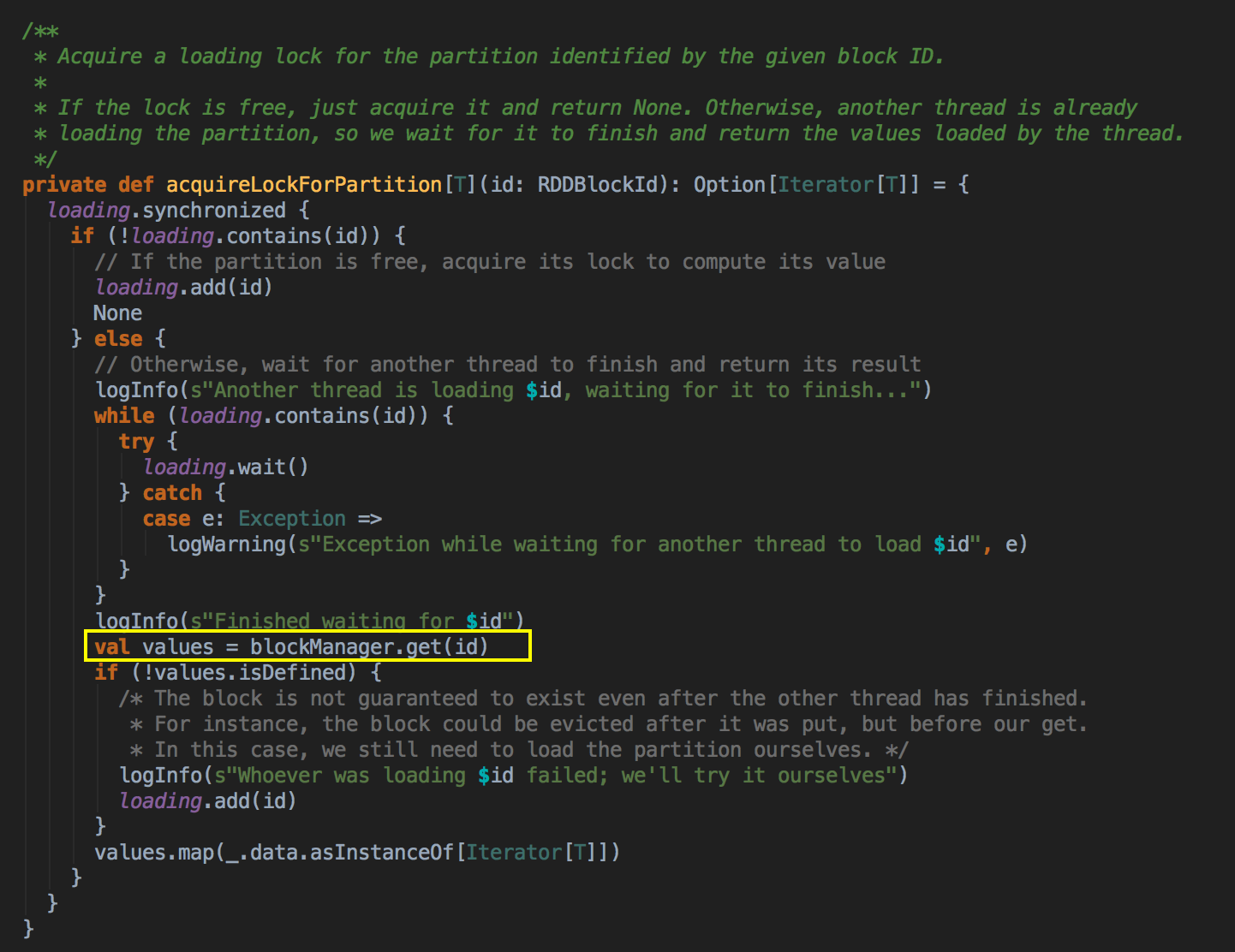
- 具体 CacheManager 在获得缓存数据的时候会通过 BlockManager 来抓到数据,优先在本地找数据或者的话就远程抓取数据。
[下图是 BlockManager.scala 的 get 方法]
BlockManger.getLocal 然后转过来调用 doGetLocal 方法,在 doGetLocal 的实现中看到缓存其实不竟竟在内存中,可以在内存、磁盘、也可以在 OffHeap (Tachyon) 中
[下图是 BlockManager.scala 的 getLocal 方法]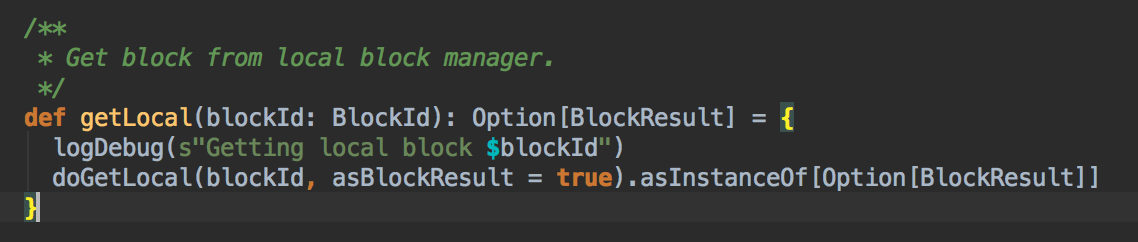
- 在第5步调用了 getLocal 方法后转过调用了 doGetLocal
[下图是 BlockManager.scala 的 doGetLocal 方法]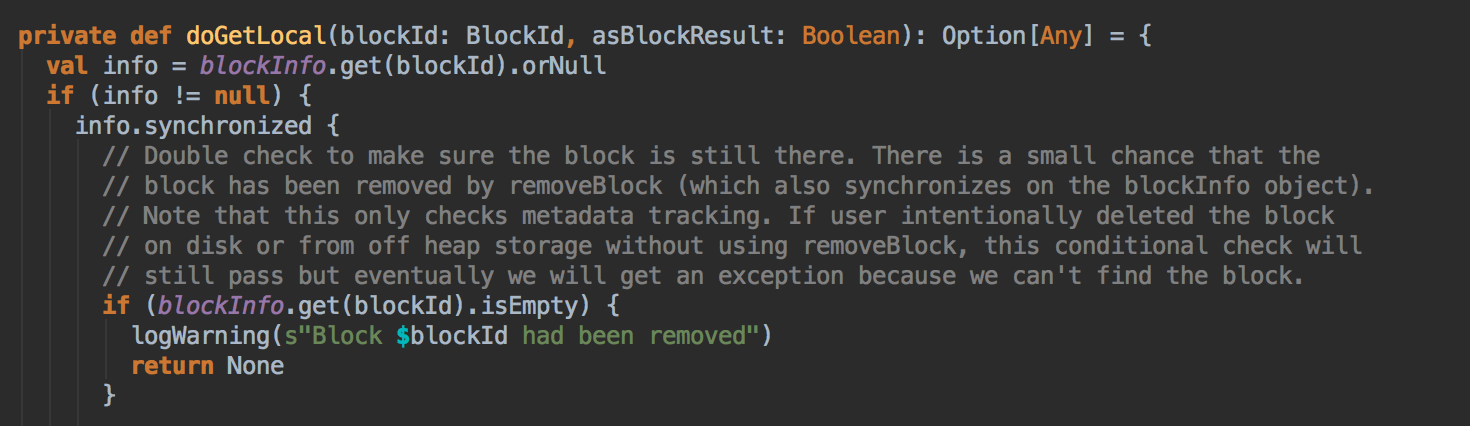
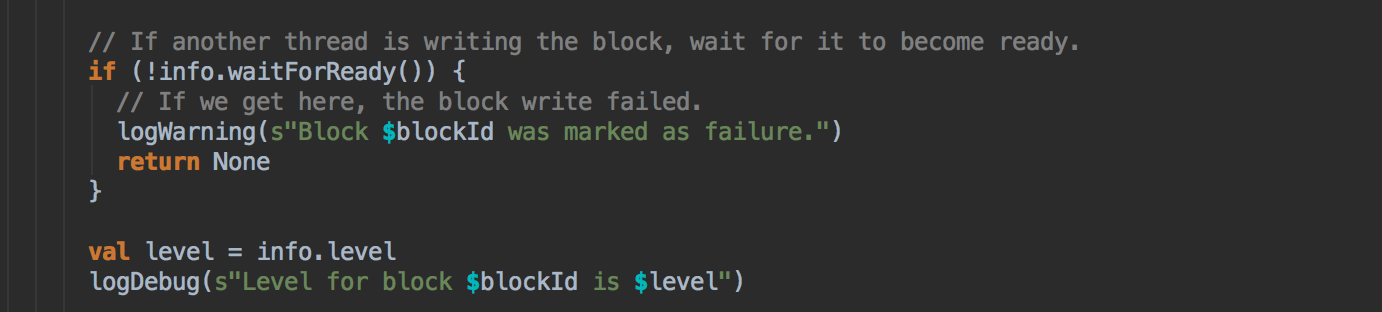

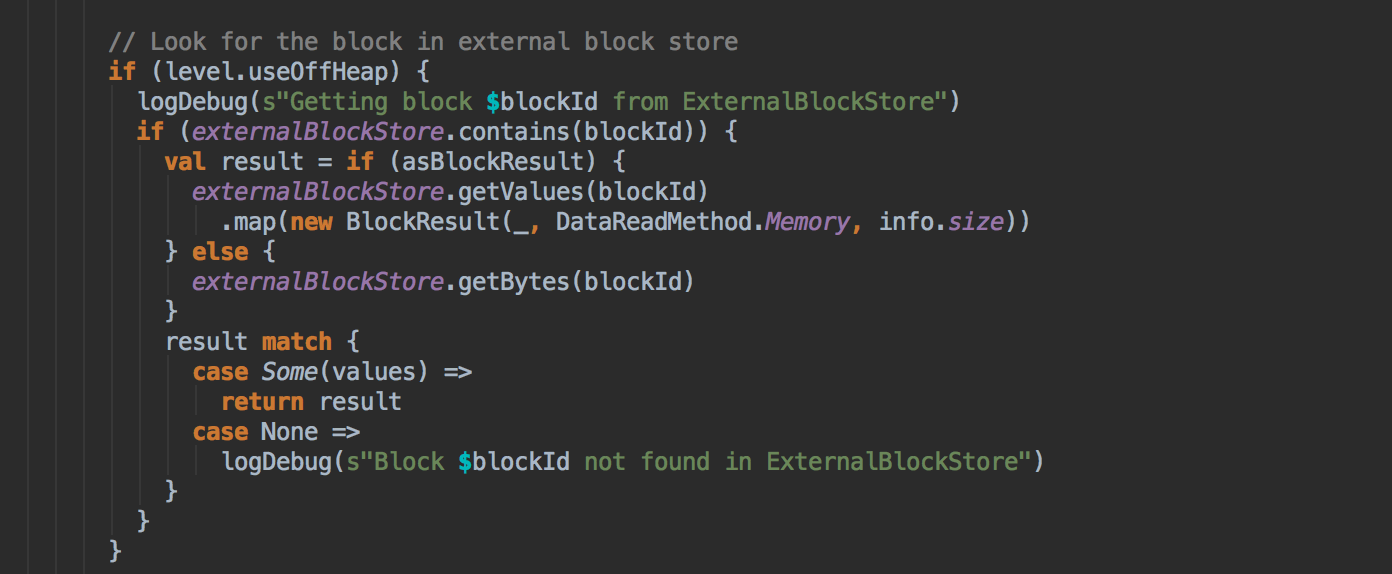
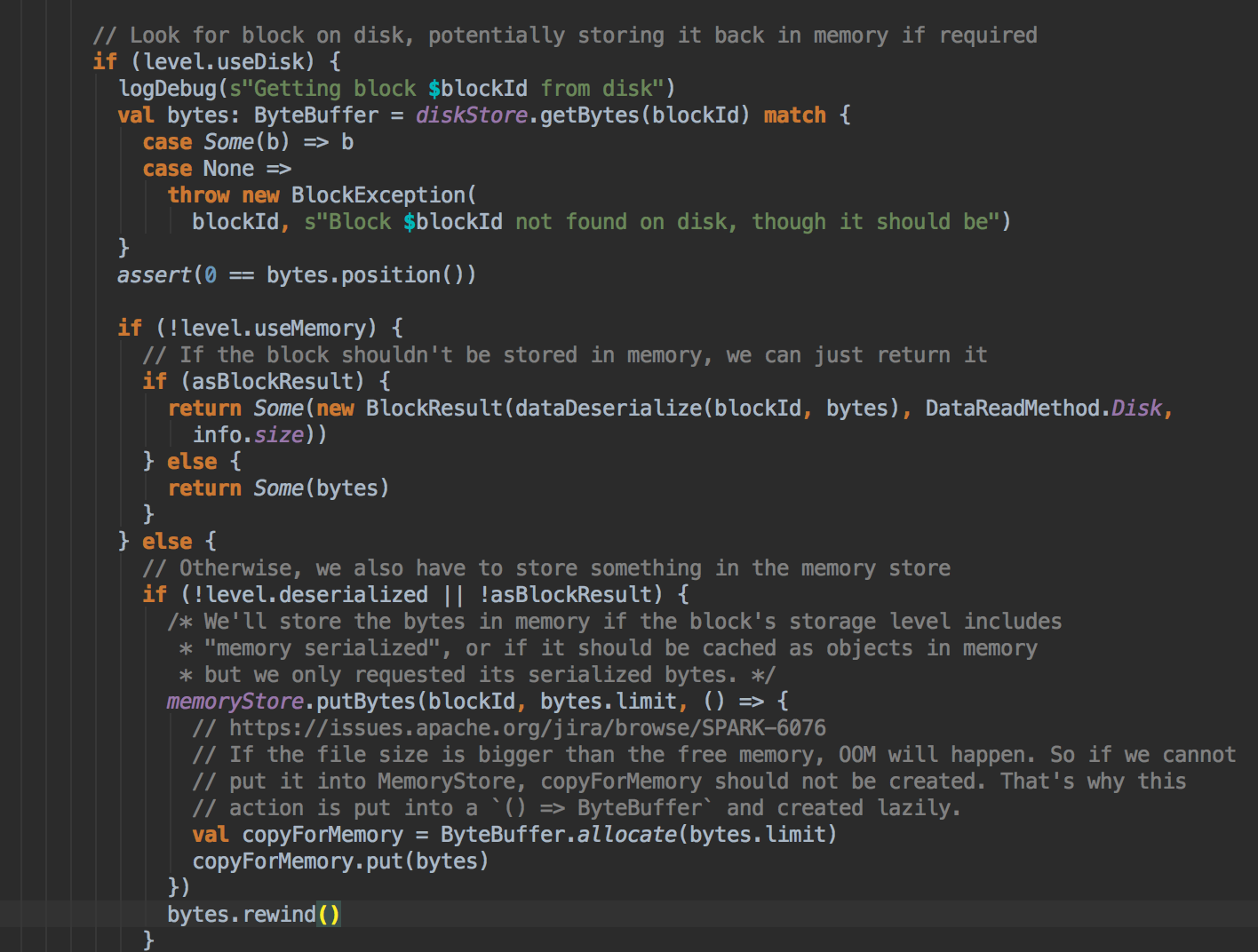
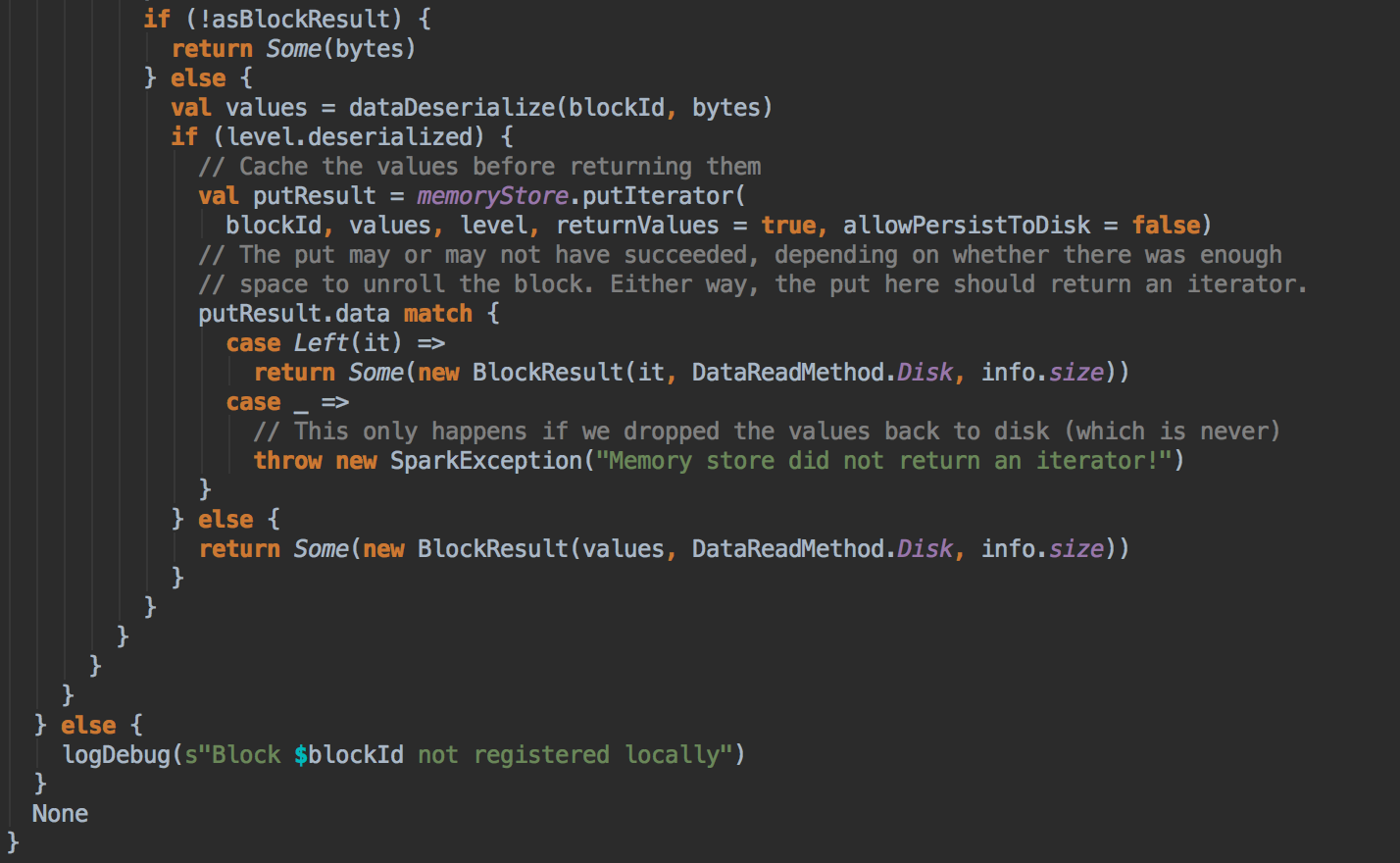
- 在第5步中如果本地没有缓存的话就调用 getRemote 方法从远程抓取数据
[下图是 BlockManager.scala 的 getRemote 方法]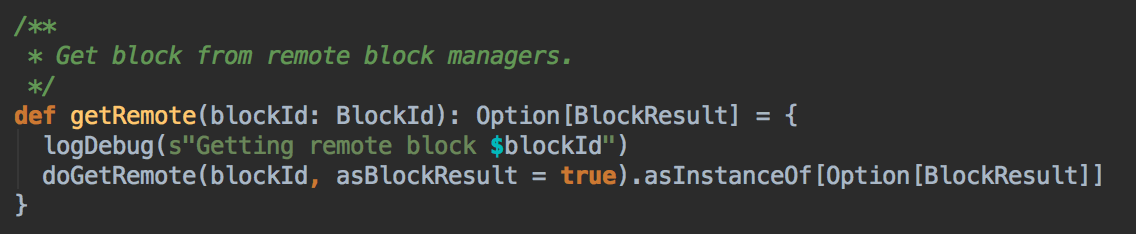
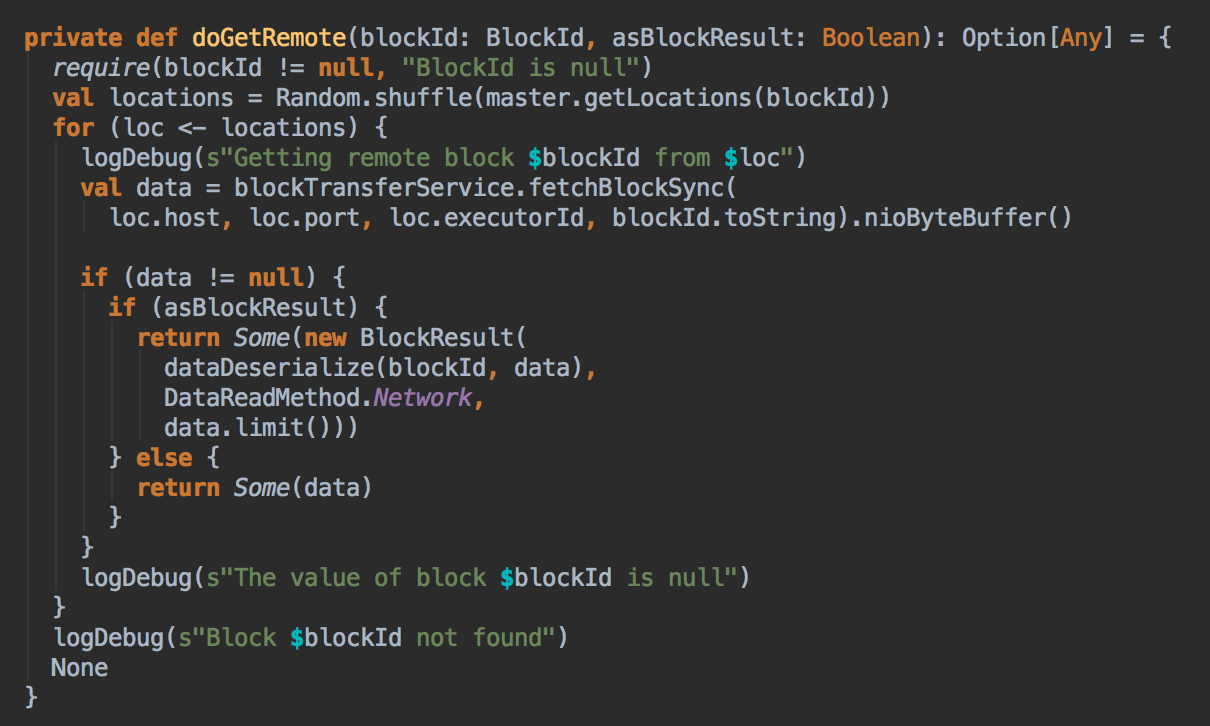
- 如果 CacheManager 没有通过 BlockManager 获得缓存内容的话,其实会通过 RDD 的 computeOrReadCheckpoint 方法来获得数据。
[下图是 RDD.scala 的 computeOrReadChcekpoint 方法]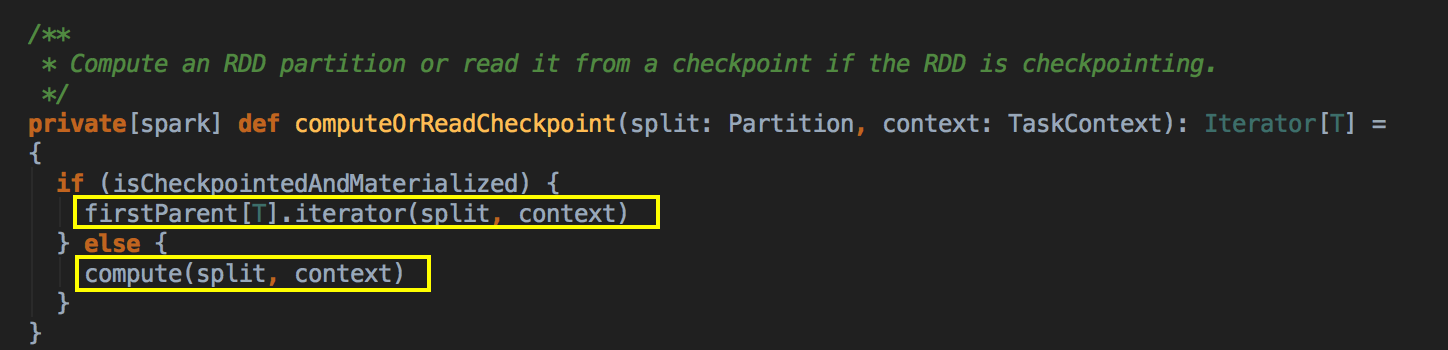
上述首先检查看当前的 RDD 是否进行了 Checkpoint ,如果进行了话就直接读取 checkpoint 的数据,否则的话就必需进行计算; Checkpoint 本身很重要;计算之后通过 putInBlockManager 会把数据按照 StorageLevel 重新缓存起来。
[下图是 CacheManager.scala 的 putInBlockManager 方法]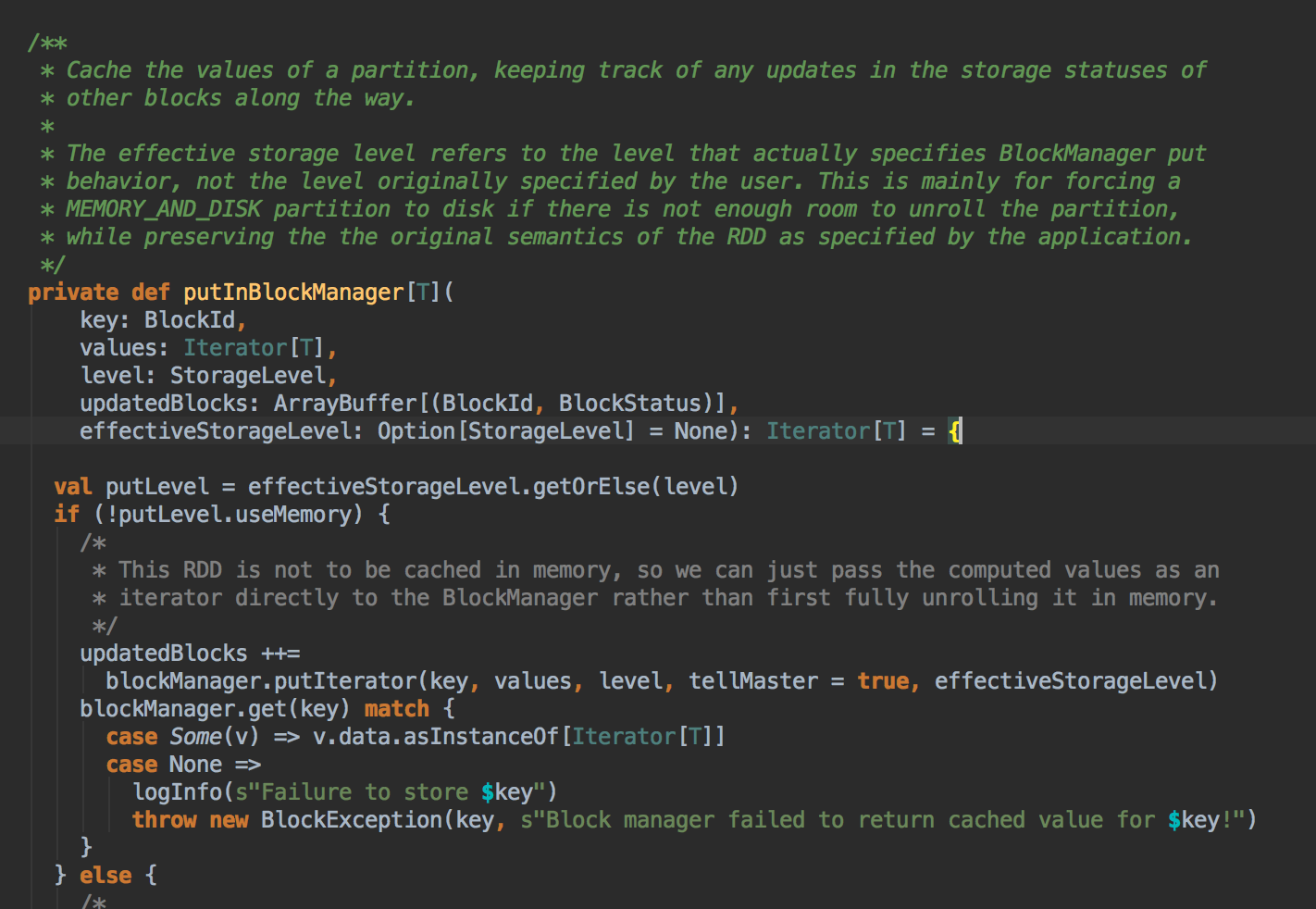

- 你如果把数据缓存在内存中,你需要注意的是内存空间够不够,此时会调用 memoryStore 中的 unrollSafety 方法,里面有一个循环在内存中放数据。
[下图是 MemoryStore.scala 中的 unrollSafely 方法]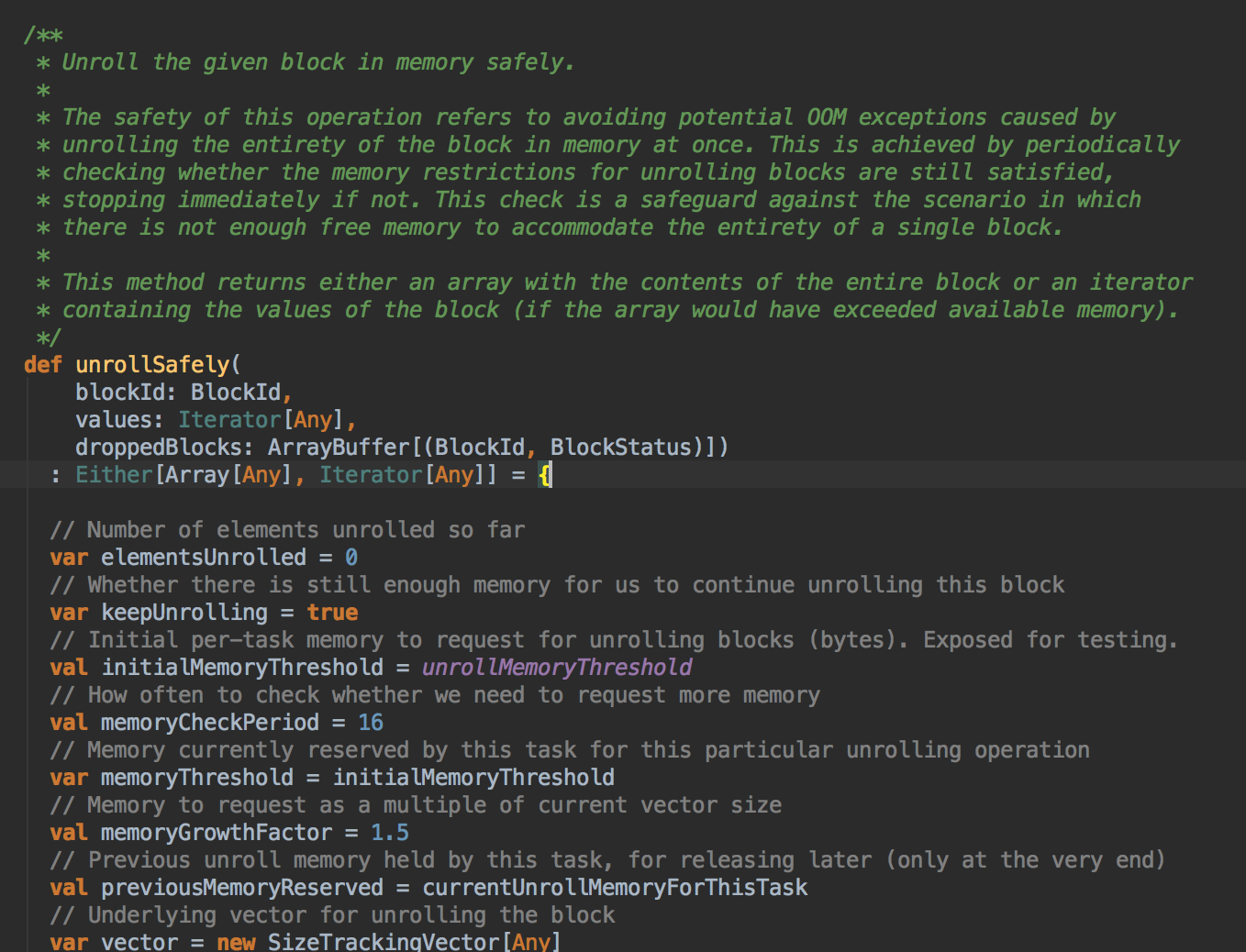
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解
Spark源码图片取自于 Spark 1.6.0版本
[Spark内核] 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解的更多相关文章
- Spark Sort-Based Shuffle具体实现内幕和源码详解
为什么讲解Sorted-Based shuffle?2方面的原因:一,可能有些朋友看到Sorted-Based Shuffle的时候,会有一个误解,认为Spark基于Sorted-Based Shuf ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
本课主题 BlockManager 运行實例 BlockManager 原理流程图 BlockManager 源码解析 引言 BlockManager 是管理整个Spark运行时的数据读写的,当然也包 ...
- Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解
Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解 今天主要理一下StreamingContext的启动过程,其中最为重要的就是Jo ...
- [转]Linux内核源码详解--iostat
Linux内核源码详解——命令篇之iostat 转自:http://www.cnblogs.com/york-hust/p/4846497.html 本文主要分析了Linux的iostat命令的源码, ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
- [Spark内核] 第29课:Master HA彻底解密
本课主题 Master HA 解析 Master HA 解析源码分享 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... Master HA 解析 生产环境下一般 ...
- [Spark内核] 第37课:Task执行内幕与结果处理解密
本课主题 Task执行内幕与结果处理解密 引言 这一章我们主要关心的是 Task 是怎样被计算的以及结果是怎么被处理的 了解 Task 是怎样被计算的以及结果是怎么被处理的 Task 执行原理流程图 ...
- Linux内核源码详解——命令篇之iostat[zz]
本文主要分析了Linux的iostat命令的源码,iostat的主要功能见博客:性能测试进阶指南——基础篇之磁盘IO iostat源码共563行,应该算是Linux系统命令代码比较少的了.源代码中主要 ...
随机推荐
- Linux定义变量的脚本
现有两段基本一样的代码,只是变量进行改变,其他都没有变化,但是执行过程中出现了不一样的结果 代码一: vi back.sh #backup import file,such as /etc/rc.lo ...
- 报表开发之扩展GROUP BY
在实际运用中.比方在数据仓库中,常常须要对数据进行多维分析.不仅须要标准分组的结果(相当于 GROUP BY),还须要不同维度的小计(简单 GROUP BY 中取部分列分组)和合计(不分组).从而 提 ...
- Oracle自动备份数据
一. Oracle自动备份单表一个月数据 方式一:三步处理(建批处理文件,写sql文件,设置任务计划) 1. 第一步:建立一个批处理文件 @echo off Set OrclSid=orcl Set ...
- anaconda不能安装python的包问题
在点了n次,重启应用多次之后,安装包(apply)之后还是没有反应,依然心平气和的我突然想到用管理员模式打开,结果就可以愉快的装包了,估计创建新的环境也是要管理员打开的.
- angularf封装echarts
前言:angular中快速使用echarts 在html使用ehart很简单,你只需要引入文件和按照官方例子按照对应参数配置和数据填充就Ok了,那么在angular中怎么使用eharts(可以使用ec ...
- make工程管理器
1.概述 大型程序中,人们希望工具自动识别修改的文件,而且不需要输入冗长的命令,就可以进行编译链接等操作,于是make工程管理器应运而生. make可以自动识别文件时间戳,只处理修改的文件: make ...
- 后台返回数据事null时怎么进行判断
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px "Helvetica Neue"; color: #454545 } p. ...
- 使用puppet
首先配置一个默认文件 只是首次创建的时候才需要重启,后期不需要重启! [root@master manifests]# vim /etc/puppet/manifests/site.pp node d ...
- IntelliJ IDEA如何设置头注释,自定义author和date
下面这张图,保证你一看就会: 下面这个模板,你拿去改一改就行了. /** * @Author: Gosin * @Date: ${DATE} ${TIME} */ 如果觉得上面名字下面的波浪线碍眼,可 ...
- P神的SDFZ考试题 C题
探险[问题描述] 探险家小 T 好高兴! X 国要 ...