The Expressive Power of Neural Networks: A View from the Width
@article{lu2017the,
title={The expressive power of neural networks: a view from the width},
author={Lu, Zhou and Pu, Hongming and Wang, Feicheng and Hu, Zhiqiang and Wang, Liwei},
pages={6232--6240},
year={2017}}
概
Universal approximation theorem-wiki, 这个定理分成俩个部分, 第一个部分是Unbounded Width Case, 这篇文章是Bounded Width Case (ReLu网络).
主要内容
定理1

另外, 定理1中的网络由若干个(视\(\epsilon\)而定) blocks排列而成, 每个block具有以下性质:
- depth: 4n+1, width: n+4 的神经网络
- 在一个范围外其“函数值”为0
- 它能够存储样本信息
- 它会加总自身的信息和前面的逼近信息
定理2

定理3
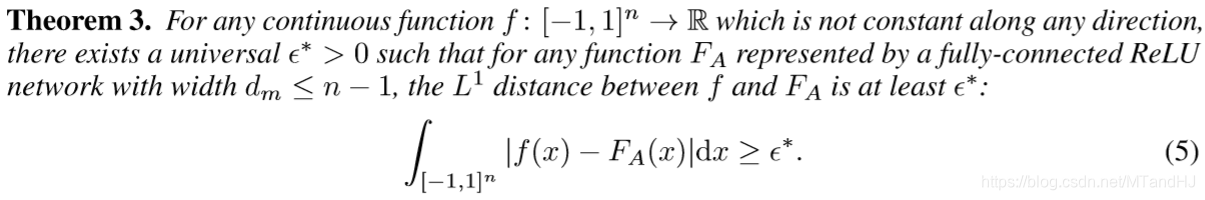
定理4

定理1的证明
因为主要关注定理1, 所以讲下这个部分的证明(实际上是因为其它懒得看了).
假设\(x = (x_1, x_2,\ldots, x_n)\)为输入, \(f\)是\(L^1\)可积的, 对于任意的\(\epsilon > 0\), 存在\(N > 0\)满足
\]
定义下列符号:
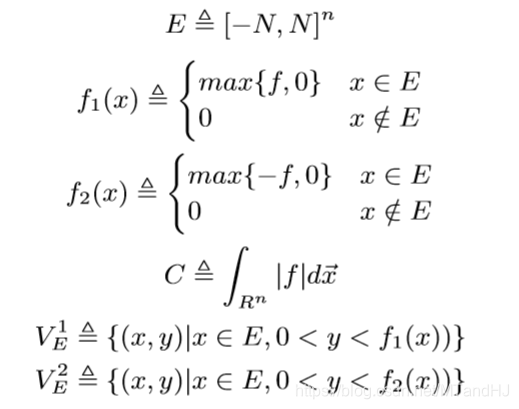
则我们有:
\]
对于\(i=1, 2\), 既然\(V_E^i\)是可测的(且测度小于\(+\infty\)), 则我们能找到有限个\(n+1\)维的矩体去逼近(原文用了cover, 但是我感觉这里用互不相交的矩体才合理), 并有
\]
不出意外\(\Delta\)应该就是\.
假设\(J_{j,i}\)有\(n_i\)个, 且
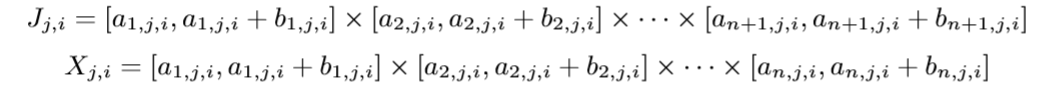
每一个\(J_{j, i}\)对应一个指示函数:
\begin{array}{ll}
1 & x \in X_{j,i} \\
0 & x \not \in X_{j,i}.
\end{array} \right.
\]
则
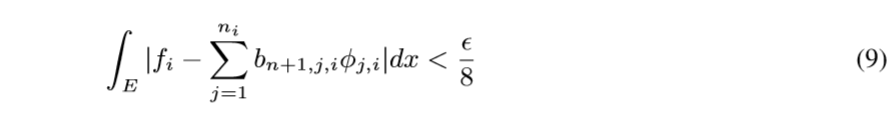
这个在实变函数将多重积分, 提到的下方图形集有讲到.
于是我们有(\(-f_1-f_2+f_1+f_2-f+f\)然后拆开来就可以得到不等式)
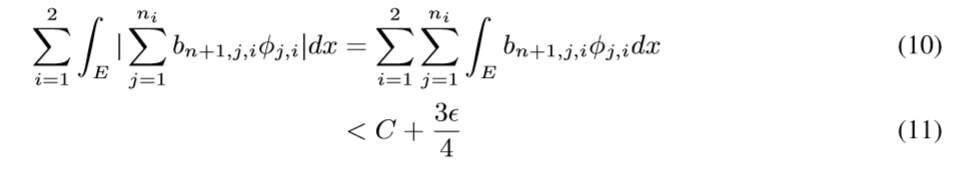
现在我们要做的就是通过神经网络拟合\(\varphi_{j,i}\)去逼近\(\phi_{j,i}\), 使得
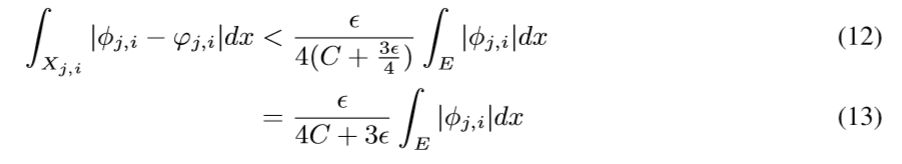
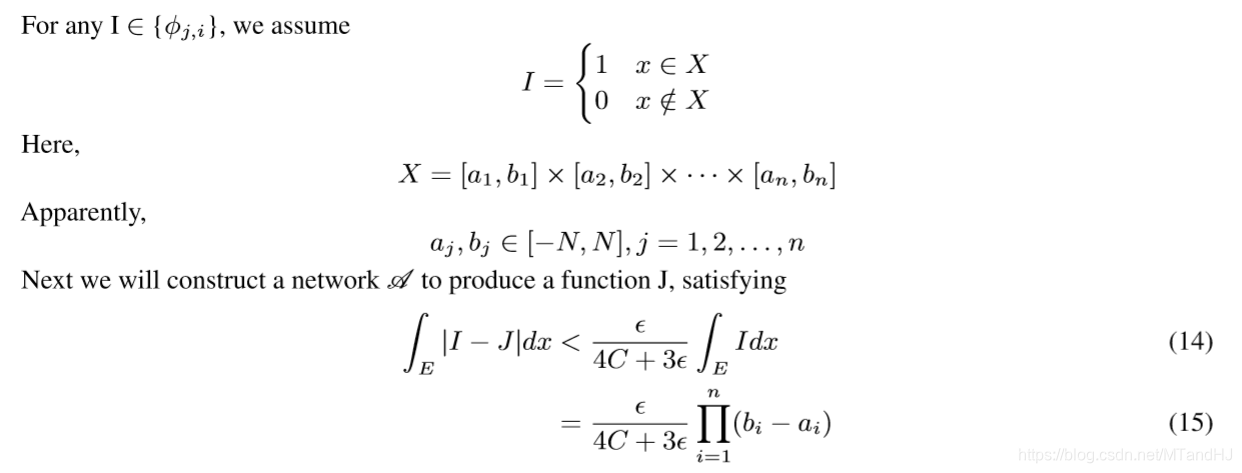
现在来讲, 如果构造这个神经网络:
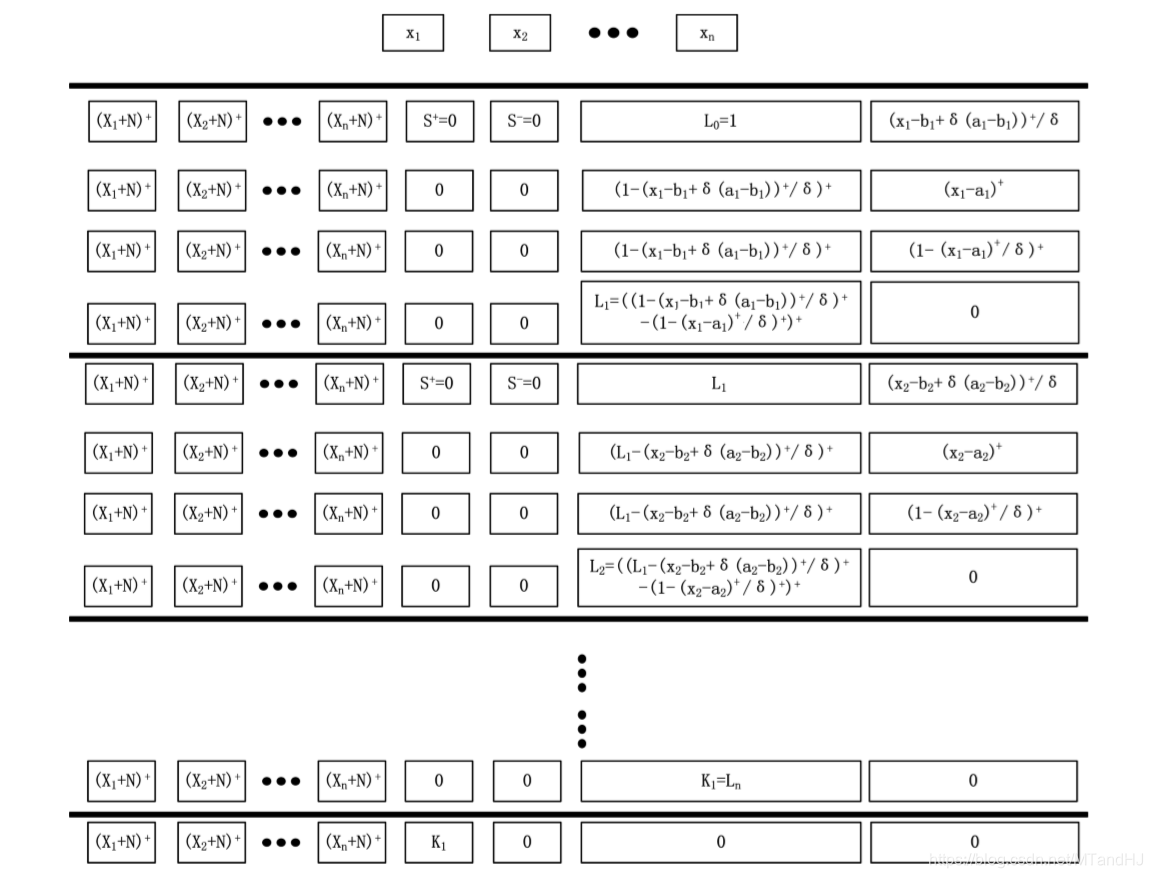
一个block有4n+1层, 每层的width是n+4, 注意到所有层的前n个Node都是一样的用来保存样本信息. 我们用\(R_{i, j, \mathscr{B_k}}, i=1, 2, 3, 4, j=1,\ldots,n+4, k=1,\ldots, n,\) 表示第\(k\)个Unit(每个Unit有4层)的第\(i\)层的第\(j\)个Node.
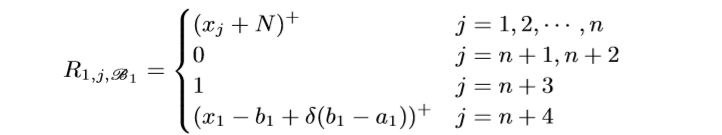
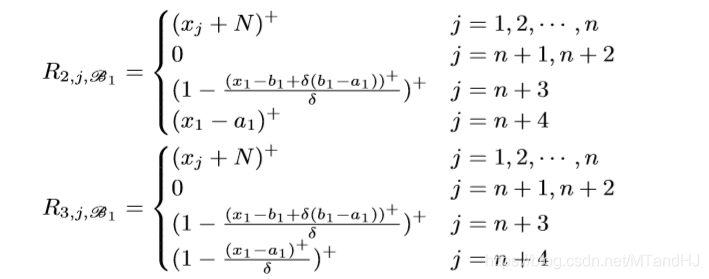

注意: \(R_{2, n+3, \mathscr{B_1}}\)应该是\((x_1-a_1)^+/\delta\), 最开始的结构图中的对的. 我们来看一下, 什么样的\(x=(x_1, \ldots, x_n)\), 会使得\(L_1\)不为0.
如果\(x_1=a_1+\delta(b_1-a_1)+\epsilon\), 这里\(\epsilon>0\)是一个任意小量, 和上文中的\(\epsilon\)没有关系. 此时(当\(\delta<1/2\))
\]
当\(\delta\)足够小的时候
\]
此时\(L_1=1\), 类似地, 可以证明, 当\(\delta \rightarrow 0\)的时候, \(x_1 \in (a_1+\delta(b_1-a_1),b_1-\delta(b_1-a_1))\)时, \(L_1=1\), 否则为0.
\(R_{i, j, \mathscr{B_k}}\)的定义是类似的, 只是
\]
可以证明, 当\(\delta\rightarrow 0\), 且\(x_t \in (a_t + \delta(b_t-a_t),b_t-\delta(b_t-a_t)), t=1,2,\ldots, k\)的时候, \(L_k=1.\), 这样我们就构造了一个指示函数, 如果这个这函数对应的\(i\)为1则将\(L_n\)存入n+1 Node, 否则 n+2 Node (实际上, 我感觉应该存的是\(b_{n+1,j,i}L_n\)), 则

这里\(\mu\)相当于\(L_n\). 所以多个blocks串联起来后, 我们就得到了一个函数, 且这个函数是我们想要的.
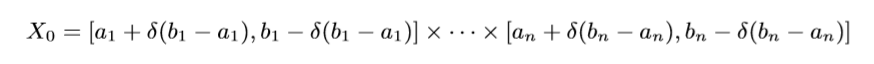
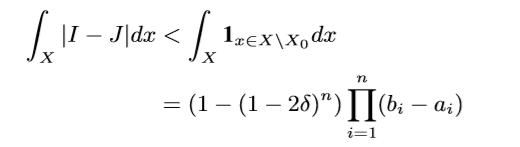
这个直接通过超距体体积计算得来的, 我们只需要取:

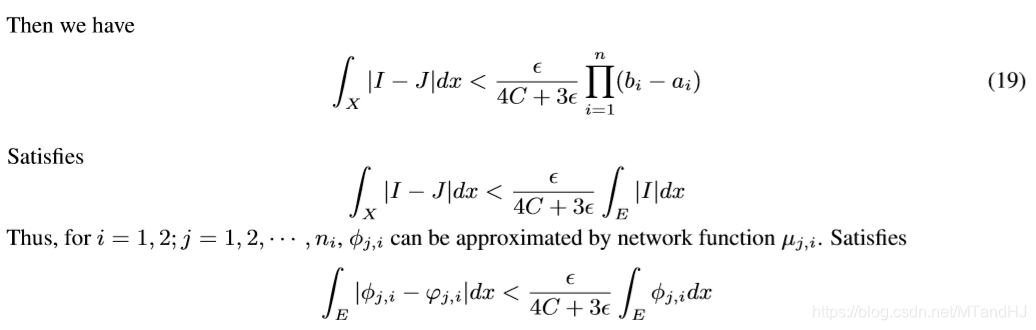
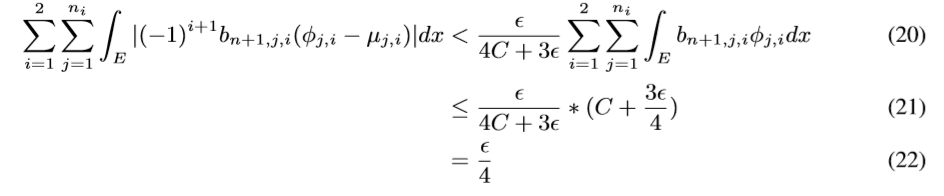
最后
令\(g:=\sum_{i=1}^2\sum_{j=1}^{n_i}(-1)^{i+1}b_{n+1,j,i}\mu_{j,i}\),便有

此即定理1的证明.
The Expressive Power of Neural Networks: A View from the Width的更多相关文章
- Deep learning_CNN_Review:A Survey of the Recent Architectures of Deep Convolutional Neural Networks——2019
CNN综述文章 的翻译 [2019 CVPR] A Survey of the Recent Architectures of Deep Convolutional Neural Networks 翻 ...
- 课程一(Neural Networks and Deep Learning),第一周(Introduction to Deep Learning)—— 2、10个测验题
1.What does the analogy “AI is the new electricity” refer to? (B) A. Through the “smart grid”, AI i ...
- Non-local Neural Networks
1. 摘要 卷积和循环神经网络中的操作都是一次处理一个局部邻域,在这篇文章中,作者提出了一个非局部的操作来作为捕获远程依赖的通用模块. 受计算机视觉中经典的非局部均值方法启发,我们的非局部操作计算某一 ...
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
- [C3] Andrew Ng - Neural Networks and Deep Learning
About this Course If you want to break into cutting-edge AI, this course will help you do so. Deep l ...
- 提高神经网络的学习方式Improving the way neural networks learn
When a golf player is first learning to play golf, they usually spend most of their time developing ...
- 深度卷积神经网络用于图像缩放Image Scaling using Deep Convolutional Neural Networks
This past summer I interned at Flipboard in Palo Alto, California. I worked on machine learning base ...
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
- Image Scaling using Deep Convolutional Neural Networks
Image Scaling using Deep Convolutional Neural Networks This past summer I interned at Flipboard in P ...
随机推荐
- 日常Java 2021/9/29
StringBuffer方法 public StringBuffer append(String s) 将指定的字符串追加到此字符序列. public StringBuffer reverse() 将 ...
- 云原生时代,为什么基础设施即代码(IaC)是开发者体验的核心?
作者 | 林俊(万念) 来源 |尔达 Erda 公众号 从一个小故事开始 你是一个高级开发工程师. 某天,你自信地写好了自动煮咖啡功能的代码,并在本地调试通过.代码合并入主干分支后,你准备把服务发布到 ...
- accessory, accident
accessory 1. belt, scarf, handbag, Penny用rhinestone做的小首饰(Penny Blossom)都是accessory2. With default se ...
- js正则表达式之密码强度验证
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Can we access global variable if there is a local variable with same name?
In C, we cannot access a global variable if we have a local variable with same name, but it is possi ...
- spring生成EntityManagerFactory的三种方式
spring生成EntityManagerFactory的三种方式 1.LocalEntityManagerFactoryBean只是简单环境中使用.它使用JPA PersistenceProvide ...
- entfrm开源免费模块化无代码开发平台,开放生态为您创造更多的价值
entfrm开发平台6大特性,赋能快速开发,为您创造更多的价值: 1. 模块化 丰富的模块稳定的框架 后台极易上手 目前已包括系统管理.任务调度.运维监控.开发工具.消息系统.工作流引擎.内容管理等模 ...
- 为什么企业全面云化需要IT战略支撑和驱动?
引子:为什么传统企业全面云化一直磨磨唧唧举步维艰? 笔者将企业上云大体上分为几个阶段: 第一个阶段是基础设施虚拟化.即将应用从物理机搬到(lift and shift migration)虚拟机上.基 ...
- Hadoop期末复习
Hadoop期末复习 选择题 以下选项中,哪个程序负责HDFS数据存储. B A.NameNode B.DataNode C.Secondary NameNode D.ResourceManager ...
- 软件开发生命周期(SDLC)
一.简介 软件开发生命周期又叫做 SDLC(Software Development Life Cycle),它是集合了计划.开发.测试和部署过程的集合.如下图所示 : 二.五个阶段 1.分析阶段: ...