RNA-seq 生物学重复相关性验证
根据拿到的表达矩阵设为exprSet
1、用scale 进行标准化
数据中心化:数据集中的各个数字减去数据集的均值
数据标准化:中心化之后的数据在除以数据集的标准差。
在R中利用scale方法来对数据进行中心化和标准化
1 scale(data, center=T, scale=F)
2
3 其中,center为T,表示数据中心化
4
5 scale为T,表示数据标准化
6
7 对一个data frame的每一列进行计算
并不是表达矩阵里面的所有基因都可以进行相关性分析,首先去除reads count >1 小于5个的基因(测试样品共有6个)
1 ##过滤reads count >1 小于5
2 exprSet <- exprSet[apply(exprSet,1, function(x) sum(x>1) >5,]
3 ##reads count 差距较大,用log以及scale 缩小差距
4 M <- scale(cor(llog2(exprSet+1)))
5 ##热图
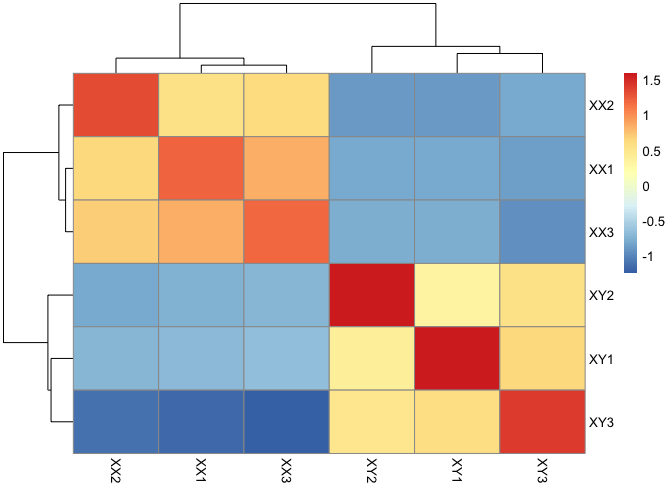
6 pheatmap(M)
2、另一种标准化
1 exprSet <- exprSet[apply(exprSet,1, function(x) sum(x>1) >5,]
2
3 ##去除文库大小差异
4 exprSet <- log(edgeR::cpm(exprSet)+1)
5
6 ##取mad(绝对中位差)(类似sd)的前50%
7 exprSet <- exprSet[names(sort(apply(exprSet,1,mad),decreasing = T)[1:500]),] ##取前500
8 M <-cor(log2(exprSet+1))
9
10 ##添加group_list
11 tem = data.frame(g=group_list)
12 rownames(tem) <- colnames(M)
13 pheatmap::pheatmap(M, annotation_col = tem,filename = 'cor.png')
3、hclust 聚类分析
欧式距离(Euclidean Distance)
欧式距离是最易于理解的一种距离计算方法,源自欧式空间中两点间的距离公式。
用R语言计算距离主要是dist函数。若X是一个M×N的矩阵,则dist(X)将X矩阵M行的每一行作为一个N维向量,然后计算这M个向量两两间的距离。
表达矩阵是每一行为基因,列为样品名称,所以要进行转至才能计算每个样品之间基因表达量的距离
为了得到更好的聚类分析,也可以将表达矩阵标准化,譬如,log,或者 scale等
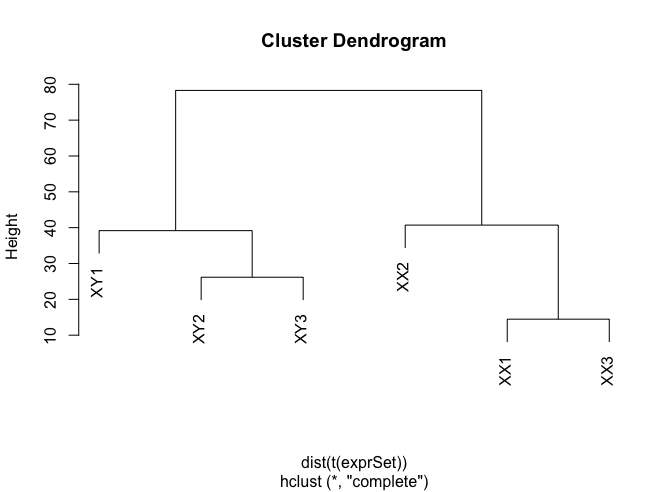
1 hc <- hclust(dist(t(exprSet)))
2 plot(hc)
参考:生信技能树
RNA-seq 生物学重复相关性验证的更多相关文章
- 无生物学重复RNA-seq分析 CORNAS: coverage-dependent RNA-Seq analysis of gene expression data without biological replicates
无生物学重复RNA-seq分析 CORNAS: coverage-dependent RNA-Seq analysis of gene expression data without biologic ...
- RNA-seq要做几次生物学重复?找出来的100%都是真正的应答基因
尹师妹:“哈师兄,做验证实验好辛苦,老板让我提高筛选差异基因的条件,尽量降低假阳性,我该怎么筛?” 小哈打开Evernote,给尹师妹看张表: “瞧见那个100%了吗?30 million mappe ...
- RNA seq 两种计算基因表达量方法
两种RNA seq的基因表达量计算方法: 1. RPKM:http://www.plob.org/2011/10/24/294.html 2. RSEM:这个是TCGAdata中使用的.RSEM据说比 ...
- RNA -seq
RNA -seq RNA-seq目的.用处::可以帮助我们了解,各种比较条件下,所有基因的表达情况的差异. 比如:正常组织和肿瘤组织的之间的差异:检测药物治疗前后,基因表达的差异:检测发育过程中,不同 ...
- 使用RDCMan管理SharePoint虚拟机的重复要求验证的问题
首先,这个软件可以从这里下载: Remote Desktop Connection Manager 同类型的软件还有很多,我没有很多复杂功能的要求,就选择了这款微软官方的,虽然很久都没有更新过了. 为 ...
- easy UI的密码长度以及重复输入验证
自己些项目的时候找的时候也找了一会,所以存下来下次用的时候可以直接用了. 话不多说,直接上代码 <tr> <td>密码:</td> <td><in ...
- seq去除重复数据
DELETE FROM temp_fjh_2 a WHERE a.rowid!=(SELECT MAX(b.rowid) FROM temp_fjh_2 b WHERE a.a=b.a); 表名和列名 ...
- 知乎Live总结-重复nature文章笔记Single-cell
来自知乎Live-孟浩巍 1.文章重要技术及图讲解 首先在转录组RNA-seq中,有基因表达差异.基因融合.可变剪切.RNA单点突变. 在基因组中,单点变异.结构变异,CNV变异(拷贝数变异) 三类基 ...
- Circular RNA的产生机制、功能及RNA-seq数据鉴定方法
推荐关注微信公众号:AIPuFuBio,和使用免费生物信息学资源和工具AIPuFu:http://www.aipufu.com. [Circular RNA的产生机制] Circular RNA,缩写 ...
随机推荐
- 如何接入 K8s 持久化存储?K8s CSI 实现机制浅析
作者 王成,腾讯云研发工程师,Kubernetes contributor,从事数据库产品容器化.资源管控等工作,关注 Kubernetes.Go.云原生领域. 概述 进入 K8s 的世界,会发现有很 ...
- Hadoop集群的配置(一)
摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问题.但是网上一些文档大多互相抄 ...
- [Beta]the Agiles Scrum Meeting 7
会议时间:2020.5.21 20:00 1.每个人的工作 今天已完成的工作 成员 已完成的工作 issue yjy 暂无 tq 新增功能:添加.选择.展示多个评测机,对新增功能进行测试 评测部分增加 ...
- js--数组的 fill() 填充方法详解
前言 我们知道了很多了初始化数组的方法,但是初始化数组之后,数组中的每一项元素默认为 empty 空位占位,如何对数组这些空位添加默认的元素,ES6提供了 fill() 方法实现这一操作.本文总结数组 ...
- Mac 系统如何利用软链接在根目录创建文件夹?
作者:泥瓦匠 出处:https://www.bysocket.com/2021-10-26/mac-create-files-from-the-root-directory.html Mac 操作系统 ...
- android tcp通讯
Andoird TCP通讯 前言 最近在写一个即时通讯的项目,有一些心得,写出来给大家分享指正一下. 简单描述一下这个项目: 实时查询车辆运行状态的项目,走TCP通迅. 接口采用GZIP压缩. 后台是 ...
- 零基础玩转C语言单链表
下图为最一简单链表的示意图: 第 0 个结点称为头结点,它存放有第一个结点的首地址,它没有数据,只是一个指针变量.以下的每个结点都分为两个域,一个是数据域,存放各种实际的数据,如学号 num,姓名 n ...
- 《基于SIRS模型的行人过街违章传播研究》
My Focus: 行人违章过街 这一行为的传播与控制 Behavior definition in this paper: 人在生活中表现出来的生活态度及具体的生活方式 Title: Researc ...
- 因为一个小小的Integer问题导致阿里一面没过,遗憾!
面试题:new Integer(112)和Integer.valueOf(112)的区别 面试官考察点猜想 这道题,考察的是对Integer这个对象原理的理解,关于这道题的变体有很多,我们会一一进行分 ...
- AtCoder Beginner Contest 220部分题(G,H)题解
刚开始的时候被E题卡住了,不过发现是个数学题后就开始使劲推式子,幸运的是推出来了,之后的F题更是树形DP换根的模板吧,就草草的过了,看了一眼G,随便口胡了一下,赶紧打代码,毕竟时间不多了,最后也没打完 ...