CVPR顶会论文爬取存入MySQL数据库(标题、摘要、作者、PDF链接和原地址)
main.py
import pymysql
import re
import requests # 连接数据库函数
from bs4 import BeautifulSoup def insertCvpr(value): try:
db = pymysql.connect(host="localhost", user="root", password="password", database="article",charset="utf8")
print("数据库连接成功!")
cur = db.cursor()
sql = 'INSERT INTO cvpr(title,ab,author,hotword,pdf,path) VALUE (%s,%s,%s,%s,%s,%s)'
cur.execute(sql, value)
db.commit()
print("增加数据成功!")
except pymysql.Error as e:
print("增加数据失败: " + str(e))
db.rollback() db.close() #主函数
print("1")
url = "https://openaccess.thecvf.com/CVPR2020.py?day=2020-06-16"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36"}
res = requests.get(url,headers=headers)
res.encoding = "utf-8"
# 先爬取每个论文的网址
web = re.findall("""<dt class="ptitle"><br><a href="(.*?)">.*?</a></dt>""", res.text, re.S)
print("2")
for each in web:
try:
each = "http://openaccess.thecvf.com/" + each
print("3")
print(each)
res = requests.get(each, headers=headers, timeout=(3, 7))
paper = BeautifulSoup(res.text)
res.encoding = "utf-8"
# 在各各论文网站中爬取详细信息
title = re.findall("""<div id="papertitle">(.*?)</div>""", res.text, re.S)#标题
ab = re.findall("""<div id="abstract" >(.*?)</div>""", res.text, re.S)#摘要
author = paper.find("div", {"id": "authors"}).find("b").find("i").text#作者
pdf = re.findall("""\[<a href="\.\./\.\./(.*?)">pdf</a>\]""", res.text, re.S)#pdf下载地址
path = each#论文简述页面
if (len(title) > 0):
title = title[0].replace("\n", "")
ab = ab[0].replace("\n", "")
pdf = "http://openaccess.thecvf.com/" + pdf[0]
print(title)
print(author)
value = (title, ab, author, "", pdf, path)
insertCvpr(value)
except:
print("异常")
2.数据库
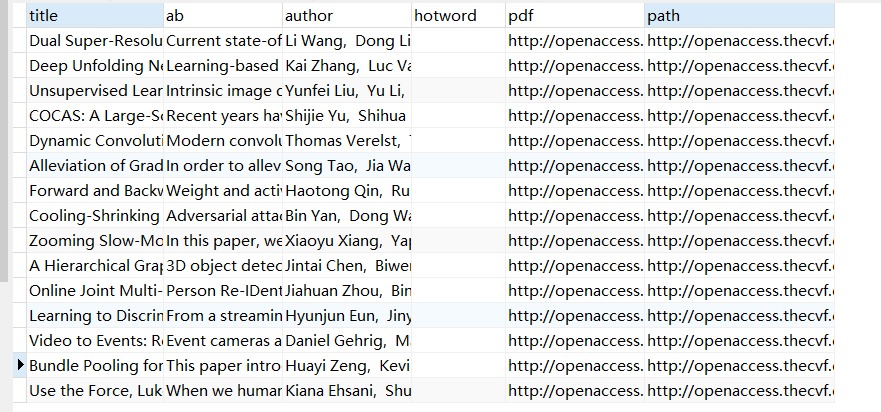
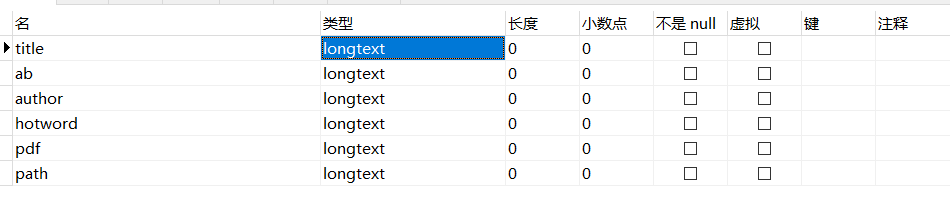
遇到的问题:
注意varchar最大长度为255,数据长度可能不够,使用longtext类型存储。
MySQL中tinytext、text、mediumtext和longtext等各个类型详解
CVPR顶会论文爬取存入MySQL数据库(标题、摘要、作者、PDF链接和原地址)的更多相关文章
- 个人作业——CVPR顶会论文爬取
main.py #保存单个界面数据 def getInfo(url): # url='https://openaccess.thecvf.com/WACV2021' header={ 'User-Ag ...
- 论文爬取 & 词频统计2.0
一.Github地址 课程项目要求 队友博客 二.具体分工 031602225 林煌伟 :负责C++部分主要功能函数的编写,算法的设计以及改进优化 031602230 卢恺翔 : 爬虫 ...
- 用Python获取沪深两市上市公司股票信息,提取创近10天股价新高的、停牌的、复牌不超过一天或者新发行的股票,并存入mysql数据库
#该脚本可以提取沪深两市上市公司股票信息,并按以下信息分类:(1)当天股价创近10个交易日新高的股票:(2)停牌的股票:(3)复牌不超过一个交易日或者新发行的股票 #将分类后的股票及其信息(股价新高. ...
- JSON文件存入MySQL数据库
目标:将不同格式的JSON文件存入MySQL数据库 涉及的点有: 1. java处理JSON对象,直接见源码. 2. java.sql.SQLException: Incorrect string v ...
- tensorflow利用预训练模型进行目标检测(三):将检测结果存入mysql数据库
mysql版本:5.7 : 数据库:rdshare:表captain_america3_sd用来记录某帧是否被检测.表captain_america3_d用来记录检测到的数据. python模块,包部 ...
- mysql数据库可以远程连接或者说用IP地址可以访问
mysql数据库可以远程连接或者说用IP地址可以访问 一般情况不建议直接修改root的权限, 先看下,自己mysql数据库的用户级权限 mysql -u root -p----->用root登陆 ...
- 操作服务器及MySQL数据库可以使其远程链接
转自原文操作服务器及MySQL数据库可以使其远程链接 一般情况分三个地方准备,MySQL数据库,防火墙,还有你的服务器主机的准备 操作系统为centos6.5.其他系统大致差不多. 1:在服务器中安装 ...
- <爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库
网页情况: 代码: import requests from requests.exceptions import RequestException from bs4 import Beautiful ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
随机推荐
- Java中解决多线程数据安全问题
同步代码块 基本语句 synchronized (任意对象) { 操作共享代码 } 代码示例 public class SellTicket implements Runnable { private ...
- Use Emacs as Personal Knowledge Base
http://stackoverflow.com/questions/2014636/how-to-maintain-an-emacs-based-knowledge-base
- Fluid + GooseFS 助力云原生数据编排与加速快速落地
前言 Fluid 作为基于 Kubernetes 开发的面向云原生存算分离场景下的数据调度和编排加速框架,已于近期完成了 v0.6.0 版本的正式发布.腾讯云容器 TKE 团队一直致力于参与 Flui ...
- WPF自定义控件二:Border控件与TextBlock控件轮播动画
需求:实现Border轮播动画与TextBlock动画 XAML代码如下: <Window.Resources> <Storyboard x:Key="OnLoaded1& ...
- Redis-01-基础
基本概念 1 基本概念 redis是一个开源的.使用C语言编写的.支持网络交互的.可基于内存也可持久化的Key-Value数据库(非关系性数据库) redis运维的责任 1.保证服务不挂 2.备份数据 ...
- 【原创】oracle提权执行命令工具oracleShell v0.1
帮一个兄弟渗透的过程中在内网搜集到了不少oracle连接密码,oracle这么一款强大的数据库,找了一圈发现没有一个方便的工具可以直接通过用户名密码来提权的.想起来自己之前写过一个oracle的连接工 ...
- msfvenom简介
写此文是因为网上资料杂乱,不方便查阅,辣眼睛 测试免杀的时候刚好用到这个功能,顺便写一下(0202年靠msfvenom生成的纯原生payload可以宣告死亡了,如果有查不出来的杀软可以退群了,这也叫杀 ...
- STP规则
1)每个网络的有且只有一个桥根 2)每个非桥根有且只有一个根端口: 3)每条链路有且只有一个指定端口: 4)根桥的所有端口均为指定端口: 5)根端口和指定端口都是forwading: 6)阻塞端口为B ...
- Windows下安装RocketMQ
目录 前言 环境 具体操作 下载 环境变量配置 启动 关闭 生产.消费实例 RocketMQ Console 前言 项目中用到了延迟消息队列,记录下一win10下rocketmq的安装 环境 win1 ...
- Thread类中yield方法
Yield方法可以暂停当前正在执行的线程对象,让其他有相同优先级的线程执行.它是一个静态方法而且只保证当前线程放弃CPU占用而不能保证其它线程一定能占用CPU,执行yield()的线程有可能在进入到暂 ...