CVPR顶会论文爬取存入MySQL数据库(标题、摘要、作者、PDF链接和原地址)
main.py
import pymysql
import re
import requests # 连接数据库函数
from bs4 import BeautifulSoup def insertCvpr(value): try:
db = pymysql.connect(host="localhost", user="root", password="password", database="article",charset="utf8")
print("数据库连接成功!")
cur = db.cursor()
sql = 'INSERT INTO cvpr(title,ab,author,hotword,pdf,path) VALUE (%s,%s,%s,%s,%s,%s)'
cur.execute(sql, value)
db.commit()
print("增加数据成功!")
except pymysql.Error as e:
print("增加数据失败: " + str(e))
db.rollback() db.close() #主函数
print("1")
url = "https://openaccess.thecvf.com/CVPR2020.py?day=2020-06-16"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36"}
res = requests.get(url,headers=headers)
res.encoding = "utf-8"
# 先爬取每个论文的网址
web = re.findall("""<dt class="ptitle"><br><a href="(.*?)">.*?</a></dt>""", res.text, re.S)
print("2")
for each in web:
try:
each = "http://openaccess.thecvf.com/" + each
print("3")
print(each)
res = requests.get(each, headers=headers, timeout=(3, 7))
paper = BeautifulSoup(res.text)
res.encoding = "utf-8"
# 在各各论文网站中爬取详细信息
title = re.findall("""<div id="papertitle">(.*?)</div>""", res.text, re.S)#标题
ab = re.findall("""<div id="abstract" >(.*?)</div>""", res.text, re.S)#摘要
author = paper.find("div", {"id": "authors"}).find("b").find("i").text#作者
pdf = re.findall("""\[<a href="\.\./\.\./(.*?)">pdf</a>\]""", res.text, re.S)#pdf下载地址
path = each#论文简述页面
if (len(title) > 0):
title = title[0].replace("\n", "")
ab = ab[0].replace("\n", "")
pdf = "http://openaccess.thecvf.com/" + pdf[0]
print(title)
print(author)
value = (title, ab, author, "", pdf, path)
insertCvpr(value)
except:
print("异常")
2.数据库
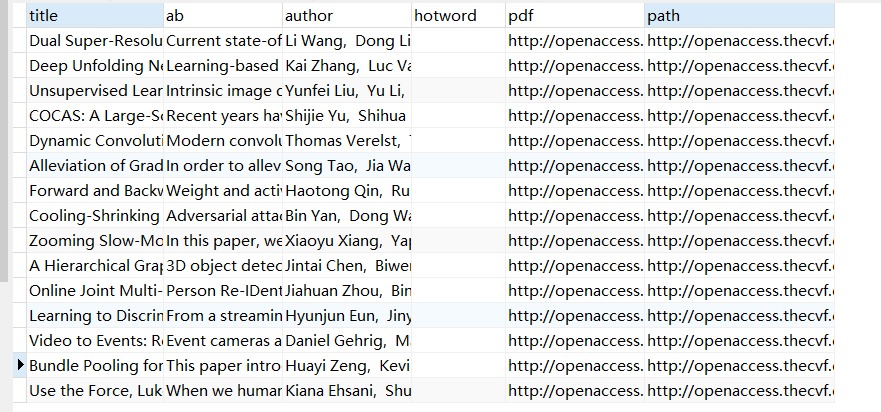
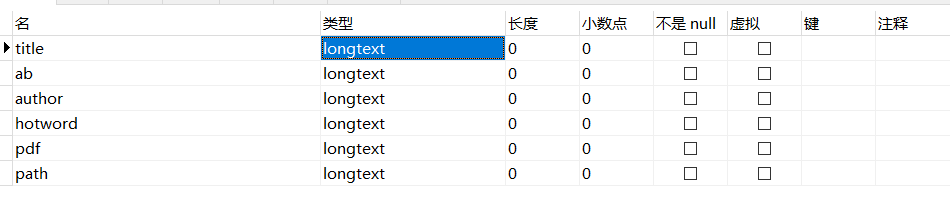
遇到的问题:
注意varchar最大长度为255,数据长度可能不够,使用longtext类型存储。
MySQL中tinytext、text、mediumtext和longtext等各个类型详解
CVPR顶会论文爬取存入MySQL数据库(标题、摘要、作者、PDF链接和原地址)的更多相关文章
- 个人作业——CVPR顶会论文爬取
main.py #保存单个界面数据 def getInfo(url): # url='https://openaccess.thecvf.com/WACV2021' header={ 'User-Ag ...
- 论文爬取 & 词频统计2.0
一.Github地址 课程项目要求 队友博客 二.具体分工 031602225 林煌伟 :负责C++部分主要功能函数的编写,算法的设计以及改进优化 031602230 卢恺翔 : 爬虫 ...
- 用Python获取沪深两市上市公司股票信息,提取创近10天股价新高的、停牌的、复牌不超过一天或者新发行的股票,并存入mysql数据库
#该脚本可以提取沪深两市上市公司股票信息,并按以下信息分类:(1)当天股价创近10个交易日新高的股票:(2)停牌的股票:(3)复牌不超过一个交易日或者新发行的股票 #将分类后的股票及其信息(股价新高. ...
- JSON文件存入MySQL数据库
目标:将不同格式的JSON文件存入MySQL数据库 涉及的点有: 1. java处理JSON对象,直接见源码. 2. java.sql.SQLException: Incorrect string v ...
- tensorflow利用预训练模型进行目标检测(三):将检测结果存入mysql数据库
mysql版本:5.7 : 数据库:rdshare:表captain_america3_sd用来记录某帧是否被检测.表captain_america3_d用来记录检测到的数据. python模块,包部 ...
- mysql数据库可以远程连接或者说用IP地址可以访问
mysql数据库可以远程连接或者说用IP地址可以访问 一般情况不建议直接修改root的权限, 先看下,自己mysql数据库的用户级权限 mysql -u root -p----->用root登陆 ...
- 操作服务器及MySQL数据库可以使其远程链接
转自原文操作服务器及MySQL数据库可以使其远程链接 一般情况分三个地方准备,MySQL数据库,防火墙,还有你的服务器主机的准备 操作系统为centos6.5.其他系统大致差不多. 1:在服务器中安装 ...
- <爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库
网页情况: 代码: import requests from requests.exceptions import RequestException from bs4 import Beautiful ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
随机推荐
- 十分钟带你了解CANN应用开发全流程
摘要:CANN作为昇腾AI处理器的发动机,支持业界多种主流的AI框架,包括MindSpore.TensorFlow.Pytorch.Caffe等,并提供1200多个基础算子. 2021年7月8日,第四 ...
- Alibaba-技术专区-RocketMQ 延迟消息实现原理和源码分析
痛点背景 业务场景 假设有这么一个需求,用户下单后如果30分钟未支付,则该订单需要被关闭.你会怎么做? 之前方案 最简单的做法,可以服务端启动个定时器,隔个几秒扫描数据库中待支付的订单,如果(当前时间 ...
- 【笔记】Ada Boosting和Gradient Boosting
Ada Boosting和Gradient Boosting Ada Boosting 除了先前的集成学习的思路以外,还有一种集成学习的思路boosting,这种思路,也是集成多个模型,但是和bagg ...
- Windows注册表内容详解(转载)
(关于windows注册表的整理,来源网络) 前提 一.什么是注册表 注册表是windows操作系统.硬件设备以及客户应用程序得以正常运行和保存设置的核心"数据库",也可以说是 ...
- SIM900A—发送、接收中英文短信
文章目录 一.SMS简介 二.短信的控制模式与编码 1.Text Mode 2.PDU Mode 3.GSM编码 4.UCS2编码 三.收发英文短信 1.AT+CPMS查询短信数量 2.AT+CNMI ...
- 当Atlas遇见Flink——Apache Atlas 2.2.0发布!
距离上次atlas发布新版本已经有一年的时间了,但是这一年元数据管理平台的发展一直没有停止.Datahub,Amundsen等等,都在不断的更新着自己的版本.但是似乎Atlas在元数据管理,数据血缘领 ...
- SQL 练习16
按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩 SELECT * from SC LEFT JOIN (SELECT sid,AVG(score) 平均成绩 from SC GROUP B ...
- bootstrap导航条报错 Uncaught TypeError: Cannot convert object to primitive value
原文: https://feiffy.cc/uncaught-typeerror-cannot-convert-object-to-primitive-value 最近发现我的博客页面移动端上下拉菜单 ...
- leaflet 的 marker 弹框 iframe 嵌套代码
A页面 嵌套 B页面的代码 主要处理 leaflet 的 marker 的 popopen, marker的点击的显示/隐藏 pop 会导致pop中的页面的内容,消失,不在页面中,导致b ...
- QT5学习:分割窗口类的使用
分割窗口在应用程序中经常用到,它可以灵活分布窗口布局,经常用于类似文件资源管理器的窗口设计中,然后抱着这样的想法简单的实现了下 [cpp] view plain copy //main.cpp ...