python爬虫学习---爬取微软必应翻译(中英互译)
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:OSinooO
本人属于python新手,刚学习的 python爬虫基础迫不及待地想试一试,看了论坛里大佬们写的在线翻译爬虫程序,想着自己把它写出来,以下是我爬微软翻译的过程,作为笔记记录下来:
1.获取信息
要实现在线翻译过程,首先要获得目标网站的信息,我们先打开微软必应翻译的官网(https://cn.bing.com/translator):
我们需要获得它的翻译请求和响应信息,操作如下:
(1)右键“检查”(用的Google Chrome浏览器),进入这个界面:
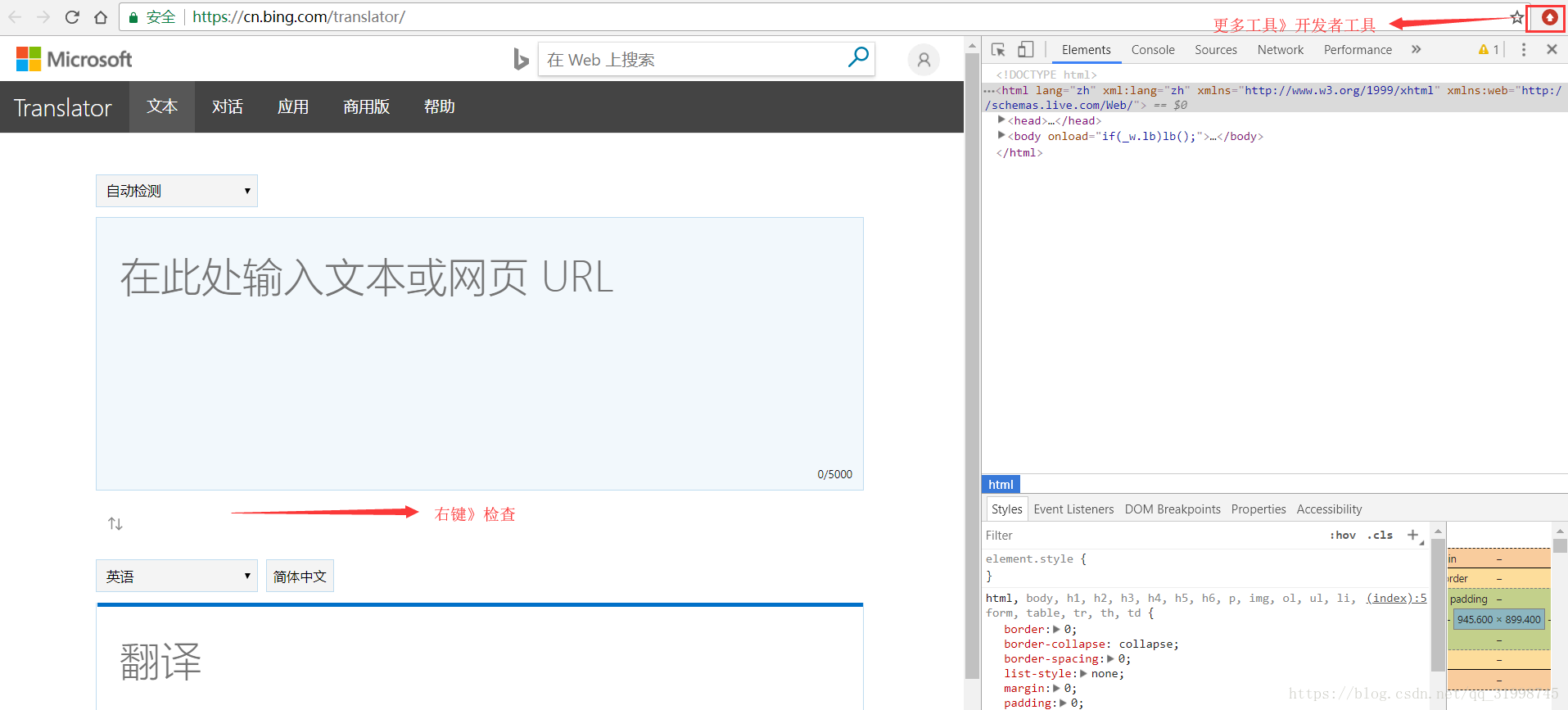
也可以通过右上角》更多工具》开发者工具进入。
(2)选择“Network”
(3)输入我们想翻译的内容,先输入“hello”,选择简体中文:
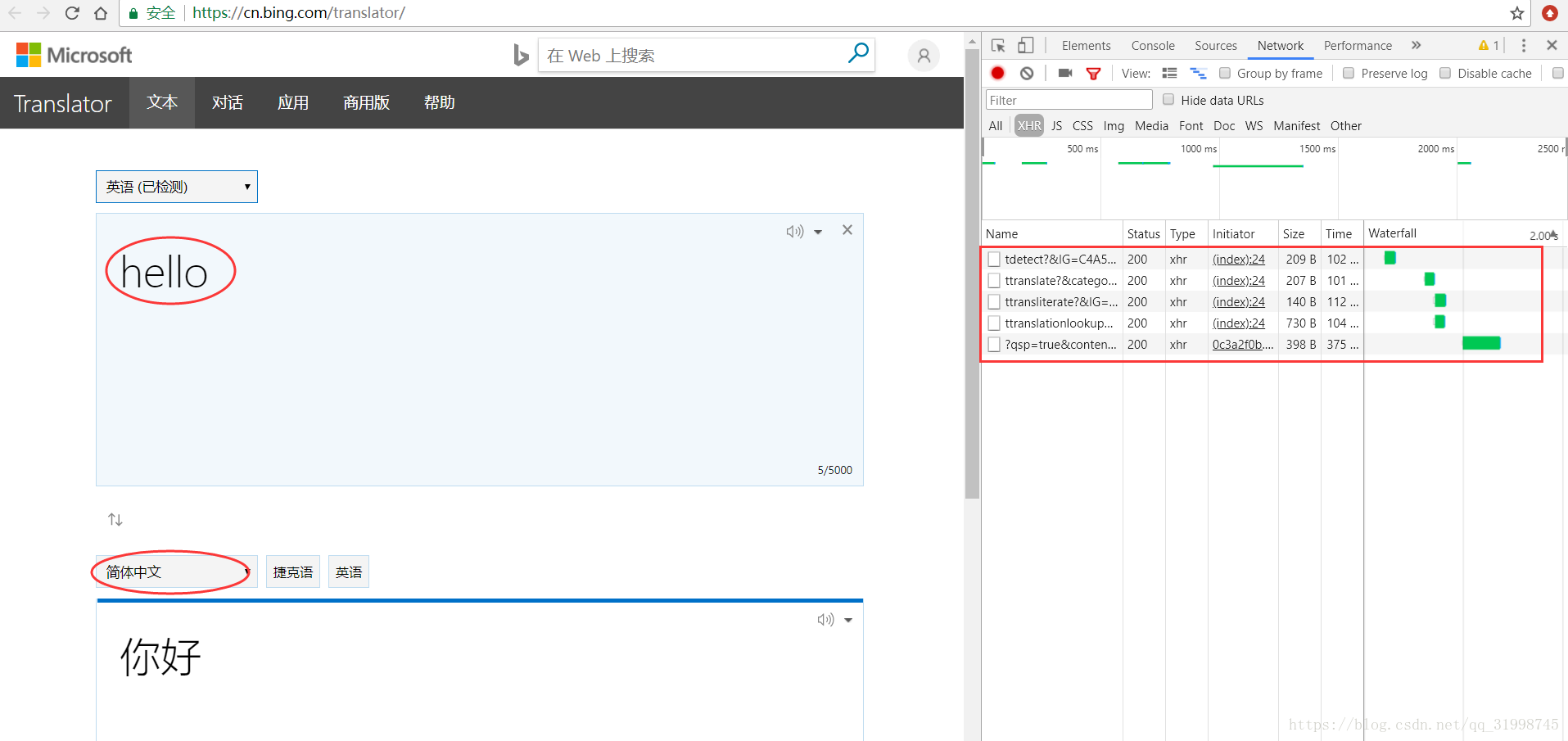
可以看到右边出了很多抓到的包,点开看一下。
(4)找到response(响应)里面出现了翻译结果的包
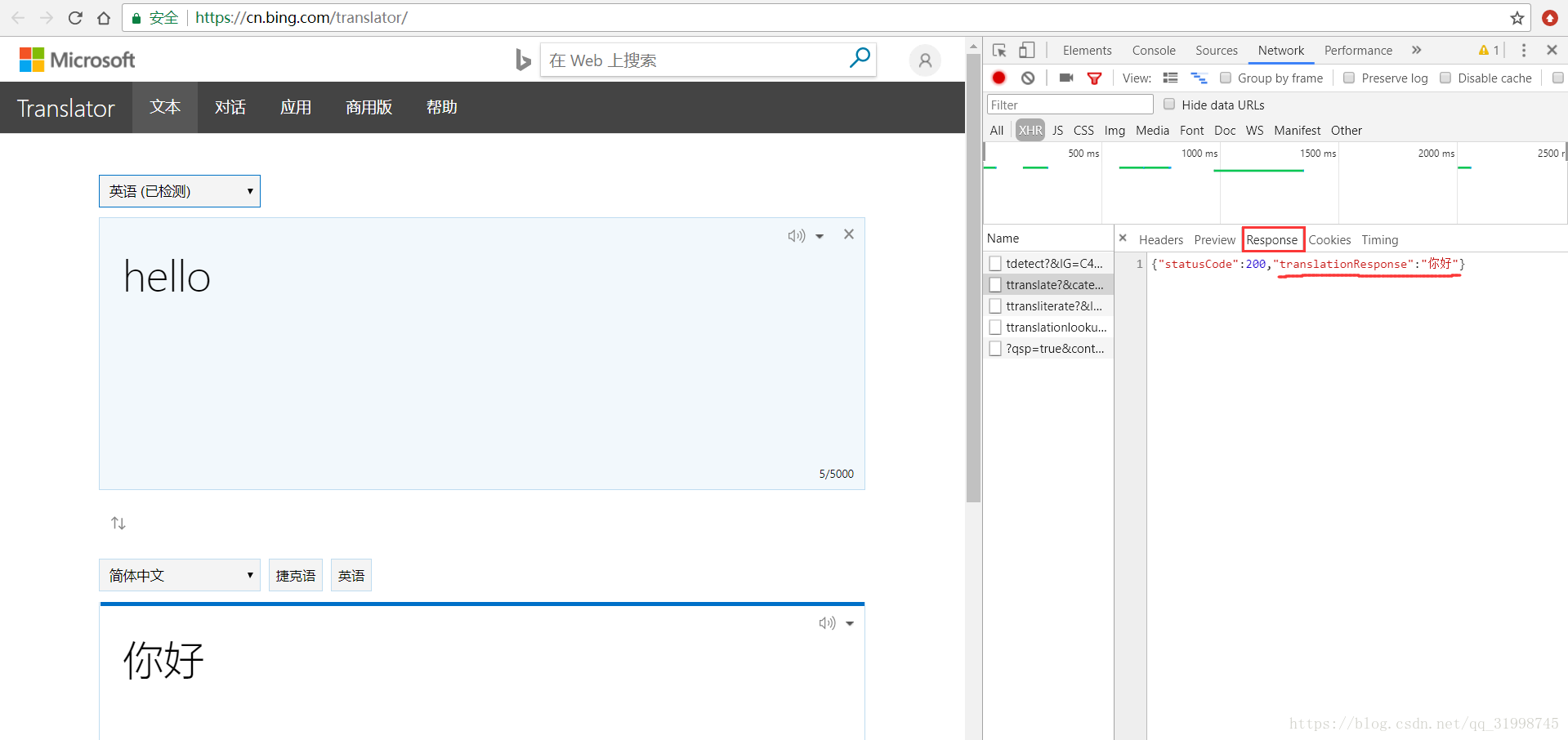
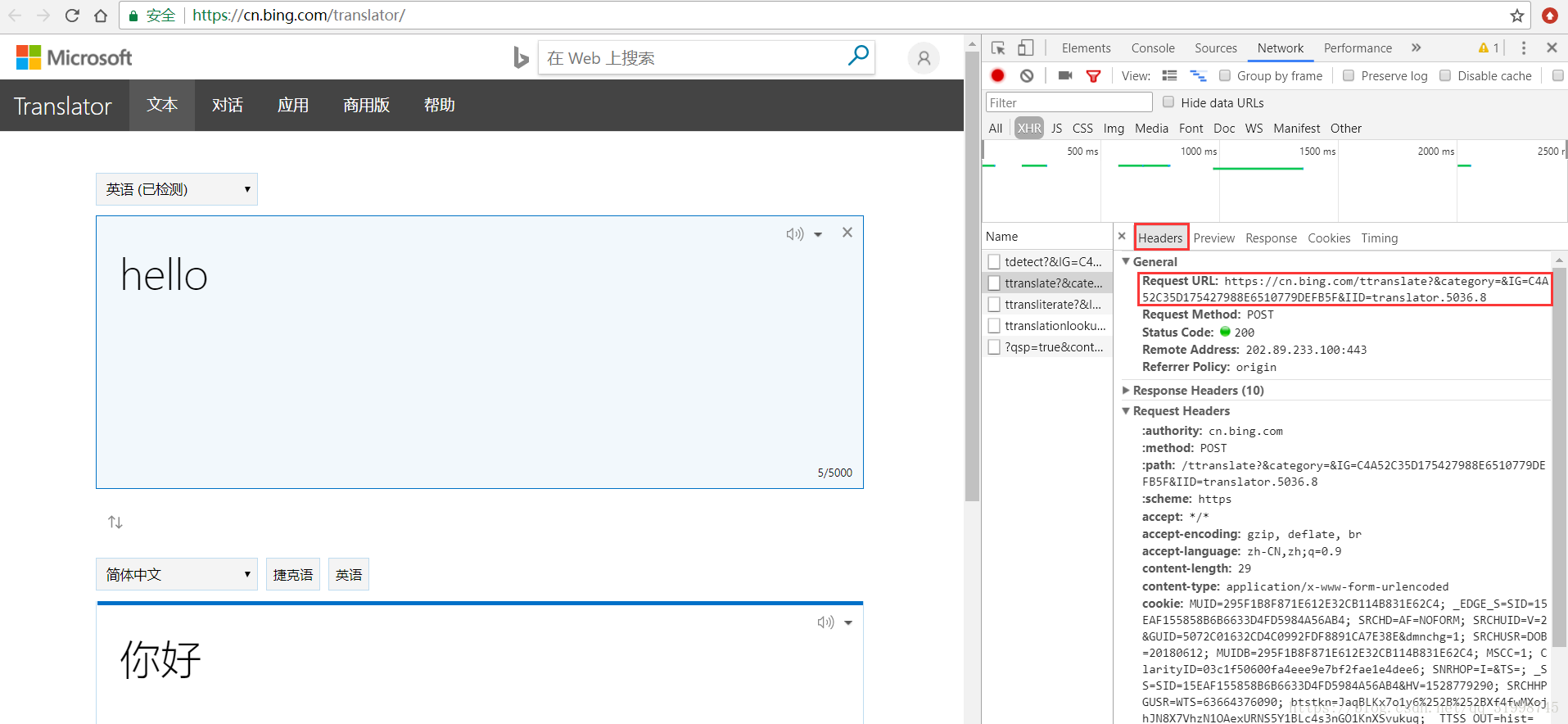
(5)接下来就是获取URL和data信息了,在“Headers”部分就可以看到。这里的URL是处理我们请求翻译的网页地址,当网页请求方式为POST时,请求参数存放在data(类型为字典)里。
URL:https://cn.bing.com/ttranslate?&category=&IG=C4A52C35D175427988E6510779DEFB5F&IID=translator.5036.8
这里我要说明一下,我在第一次找URL的时候找到的是这个:
https://cn.bing.com/ttranslate?&category=&IG=7E72C4A882064F48BAD8D7C06B7F22A9&IID=translator.5036.1
用这个URL也可以翻译,但是只能翻译单个单词和词语,在后面的代码中如果翻译了长句子就会报错。所以提取参数的时候可以把翻译内容多写一点,找到能长句翻译的URL。
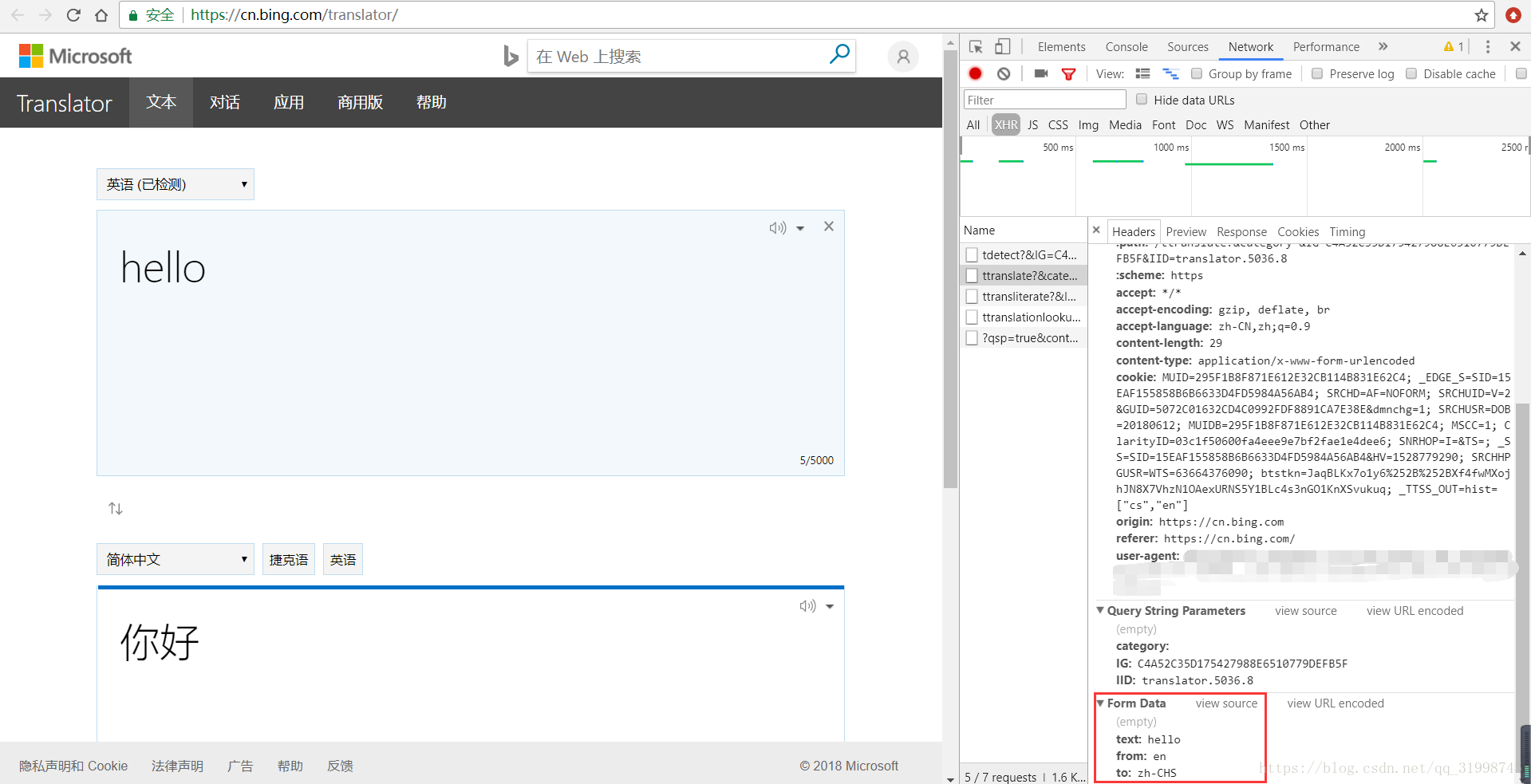
data:{‘text’:'hello', 'from':'en', 'to':'zh-CHS'}这里用字典形式写出来,简单解读就是'text'是翻译的内容,'from'是翻译内容的语言,这里的'en'就代表英语,'to'是翻译结果的语言,'zh-CHS'代表简体中文。这些之后要用到。
2.代码构建
得到信息之后就可以开始写代码了,具体可以参考文章开头的两篇参考博文,这里直接给出代码:如果你看不懂的话,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,多跟里面的人交流,进步更快哦!
import requests url = 'https://cn.bing.com/ttranslate?&category=&IG=C4A52C35D175427988E6510779DEFB5F&IID=translator.5036.8' def translate_weiruan(info,fr='zh-CHS',to="en"):
print('翻译结果:'+requests.post(url,data={'text':info,'from':fr,'to':to,'doctype':'json'}).json()['translationResponse']) def is_Chinese(str): #判断输入的内容是否是中文
for ch in str:
if '\u4e00' <= ch <= '\u9fff':
return True
else:
return False def start_translate():
trans = input('翻译内容:')
if is_Chinese(trans): #实现自动判断,中英互译
translate_weiruan(trans)
else:
translate_weiruan(trans,fr='en',to='zh-CHS') if __name__ == '__main__':
print(' 翻译结果由微软翻译提供!(请确保网络已连接)')
while True:
start_translate()
print('\n')
这里用的requests模块,可以用一句话实现我们的功能,具体参考文章开头的第二篇博文。
再简单解释一下:
def translate_weiruan(info,fr='zh-CHS',to="en"):
print('翻译结果:'+requests.post(url,data={'text':info,'from':fr,'to':to,'doctype':'json'}).json()['translationResponse'])
这段代码的功能就是用POST方式连接翻译网站(url)并给它传参数(data),返回一个 json 类型的信息,再用 json()方法对信息进行处理。返回的信息如下:
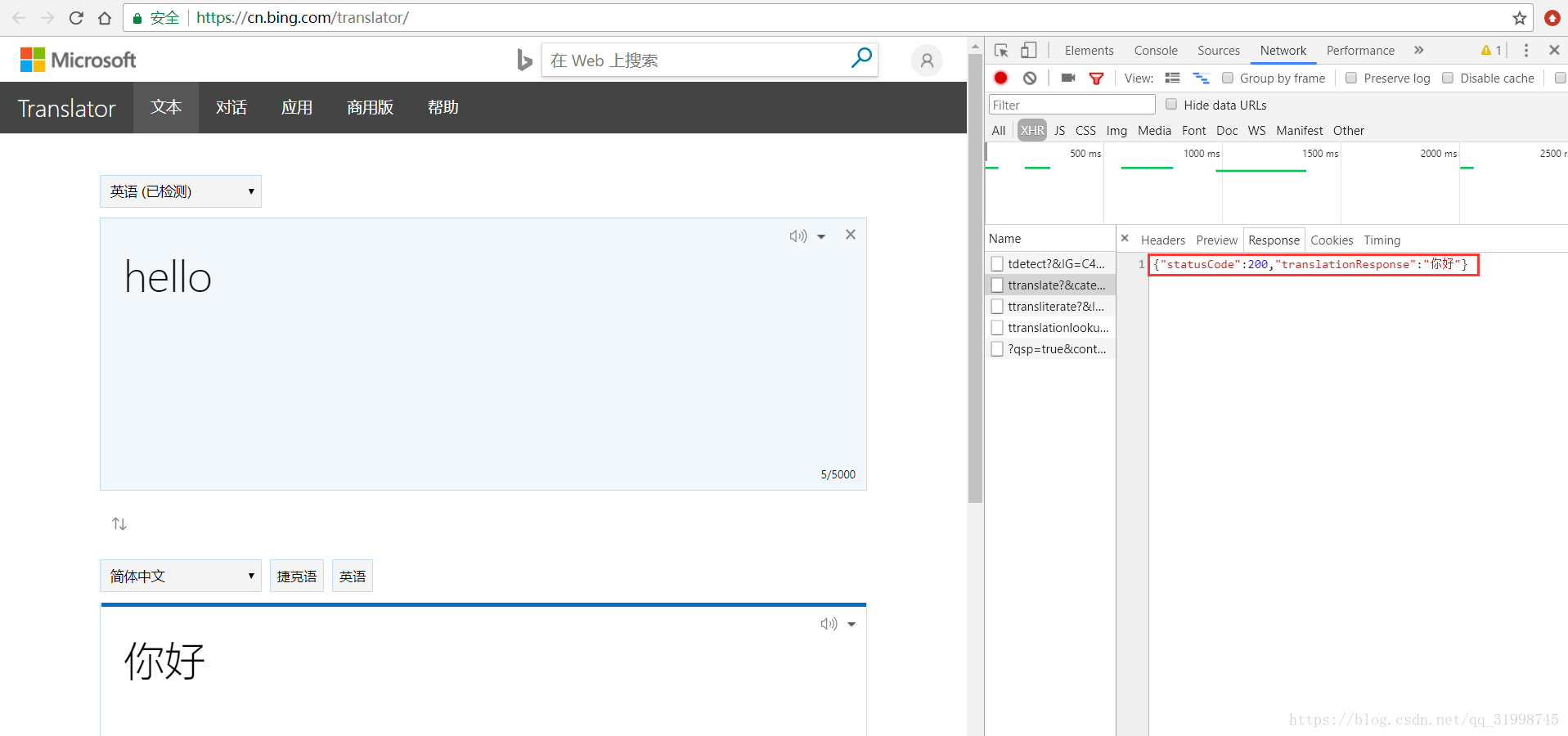
很简单的字典类型:{"statusCode":200,"translationResponse":"你好"}
再用关键字"translationResponse"提取翻译结果。
3.实战结果
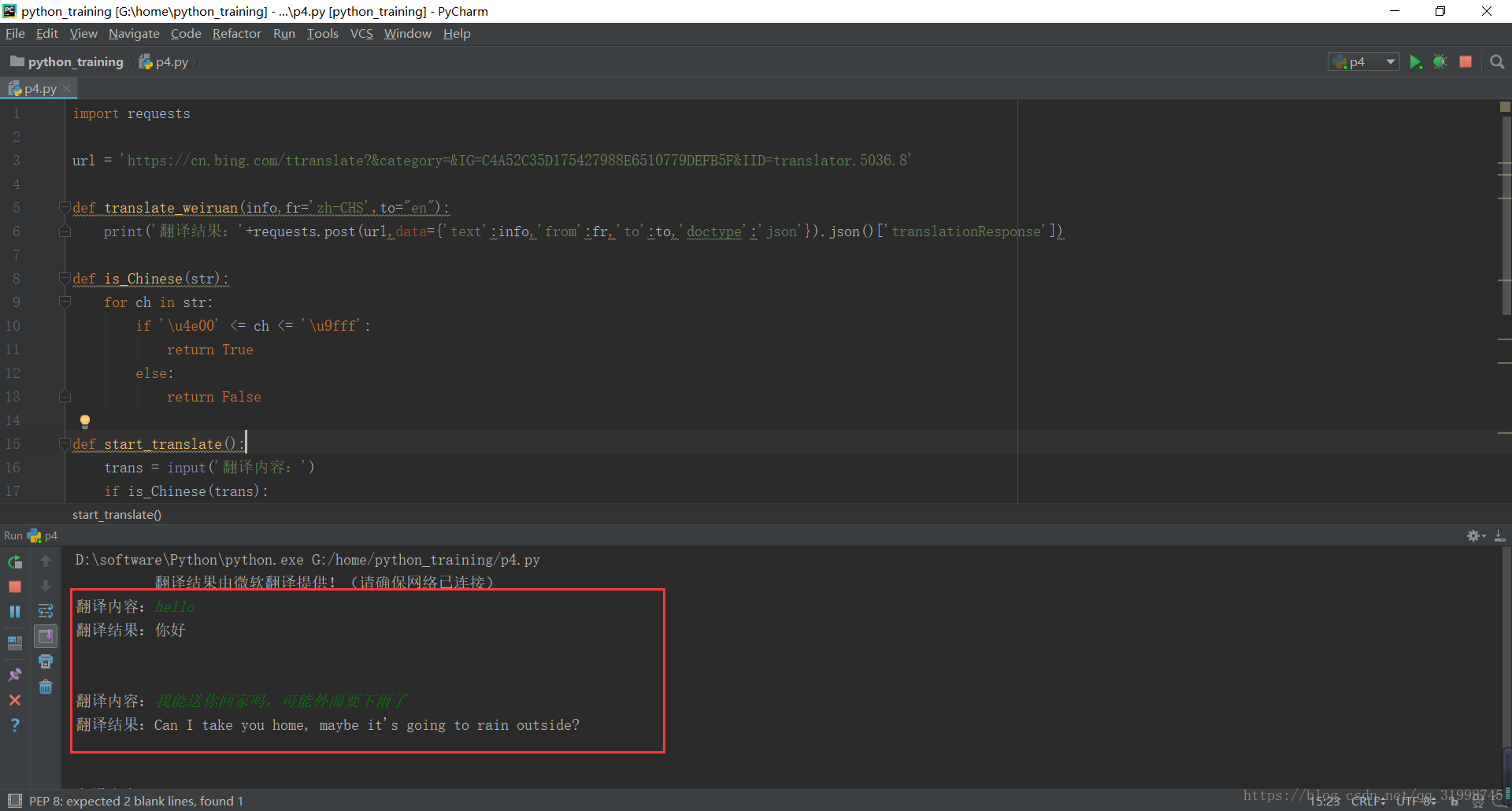
OK,也算是初步完成功能啦!当然里面也还是有很多不足,还请各位大牛指点。如果你也正在学习,可以去如果你看不懂的话,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,多跟里面的人交流,进步更快哦!
python爬虫学习---爬取微软必应翻译(中英互译)的更多相关文章
- python爬虫学习-爬取某个网站上的所有图片
最近简单地看了下python爬虫的视频.便自己尝试写了下爬虫操作,计划的是把某一个网站上的美女图全给爬下来,不过经过计算,查不多有好几百G的样子,还是算了.就首先下载一点点先看看. 本次爬虫使用的是p ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
随机推荐
- [springboot 开发单体web shop] 6. 商品分类和轮播广告展示
商品分类&轮播广告 因最近又被困在了OSGI技术POC,更新进度有点慢,希望大家不要怪罪哦. 上节 我们实现了登录之后前端的展示,如: 接着,我们来实现左侧分类栏目的功能. ## 商品分类|P ...
- Hbase简介以及简单的入门操作
Hbase是一个分布式的.面向列的开源数据库,可实时的读写.随机访问超大规模的数据集. Hbase主要分为两种模型: 逻辑模型和物理模型 1. 逻辑模型 Hbase的名字的来源是Hadoop data ...
- nyoj 266-字符串逆序输出 (isdigit(), geline(cin, my_string))
266-字符串逆序输出 内存限制:64MB 时间限制:3000ms 特判: No 通过数:15 提交数:18 难度:0 题目描述: 给定一行字符,逆序输出此行(空格.数字不输出) 输入描述: 第一行是 ...
- nyoj 264-国王的魔镜 (string[-1:-int(str_len/2+1):-1])
264-国王的魔镜 内存限制:64MB 时间限制:3000ms 特判: No 通过数:13 提交数:25 难度:1 题目描述: 国王有一个魔镜,可以把任何接触镜面的东西变成原来的两倍——只是,因为是镜 ...
- C#实现整型数据字任意编码任意进制的转换和逆转换
实现如下: using System; using System.Collections.Generic; using System.Linq; using System.Text; namespa ...
- 执行yaml.load()出现警告信息:YAMLLoadWarning: callingyaml.load() without Loader=..
执行yaml.load()出现警告信息:YAMLLoadWarning: callingyaml.load() without Loader=... 原因: yaml5.1版本后弃用了yaml.loa ...
- linux服务器cpu信息查看详解
在linux系统中,提供了/proc目录下文件,显示系统的软硬件信息.如果想了解系统中CPU的提供商和相关配置信息,则可以查/proc/cpuinfo.但是此文件输出项较多,不易理解.例如我们想获取, ...
- djanao请求生命周期
djanao请求生命周期 浏览器发送请求到服务端 服务端的wsgi服务器接收到来自浏览器的请求, 对request做一些预处理, 把浏览器的请求信息(请求方式, 请求头, socket信息等)都封装在 ...
- 格式化JS代码
平常在项目中经常会遇到下载别人的js文件都是加密过的,不方便阅读都是一整行, 个人无法进行阅读,浏览器能够识别出来,所以就可以使用浏览器进行格式化js代码: 1.打开浏览器chrome为例,打开使用j ...
- svn+apache搭建版本控制服务器
Centos7(linux)搭建版本控制服务器(svn+apache) 1.简介: 版本控制服务器: 版本控制(Revision control)是一种软体工程技巧,籍以在开发的过程中,确保由不同人所 ...