python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录
- 前言
- 一、BeautifulSoup的基本语法
- 二、爬取网页图片
- 扩展学习
- 后记
前言
本章同样是解析一个网页的结构信息
在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三])我们知道了可以使用re正则表达式来解析一个网页。
但是这样的一个解析方式可能对大部分没有正则表达式的人来说就比较困难了,
额,就算会的,也会嫌麻烦。比如me( ̄︶ ̄)↗
那么我们本章同样是学习解析,只不过这个解析的方式不需要特别的一个学习功底。
能够分析一个网页的结构就行了
φ(* ̄0 ̄)
本次的流程:
- 学习BeautifulSoup的基本语法
- 开始分析爬取
一、BeautifulSoup的基本语法
建议直接看官方文档
如果有什么进阶性的需求这章内容不能解决的话,就可以看官方文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
下载lxml模块
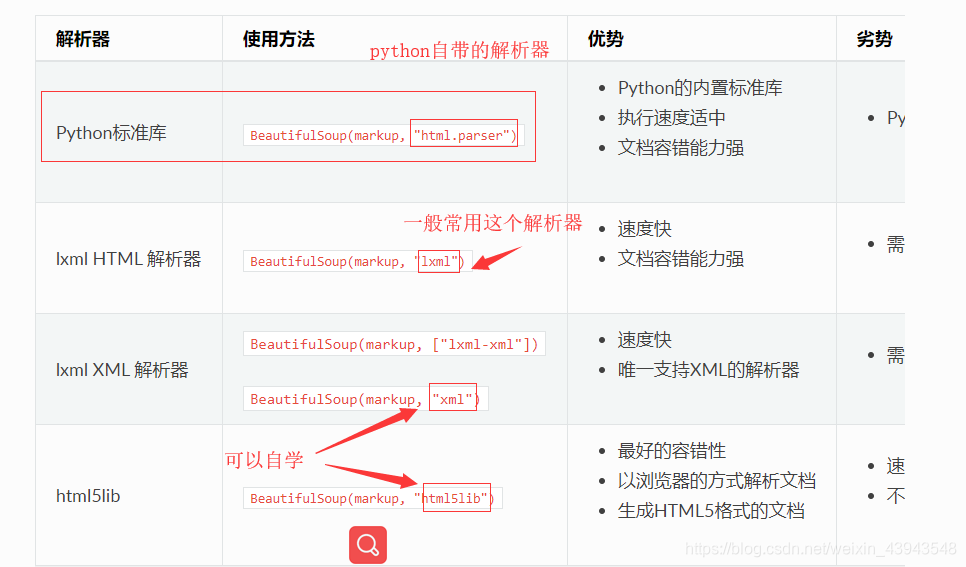
解析器的区别可以参考文档上面的资料。
下好之后就可以测试了:
先给大家解析一波: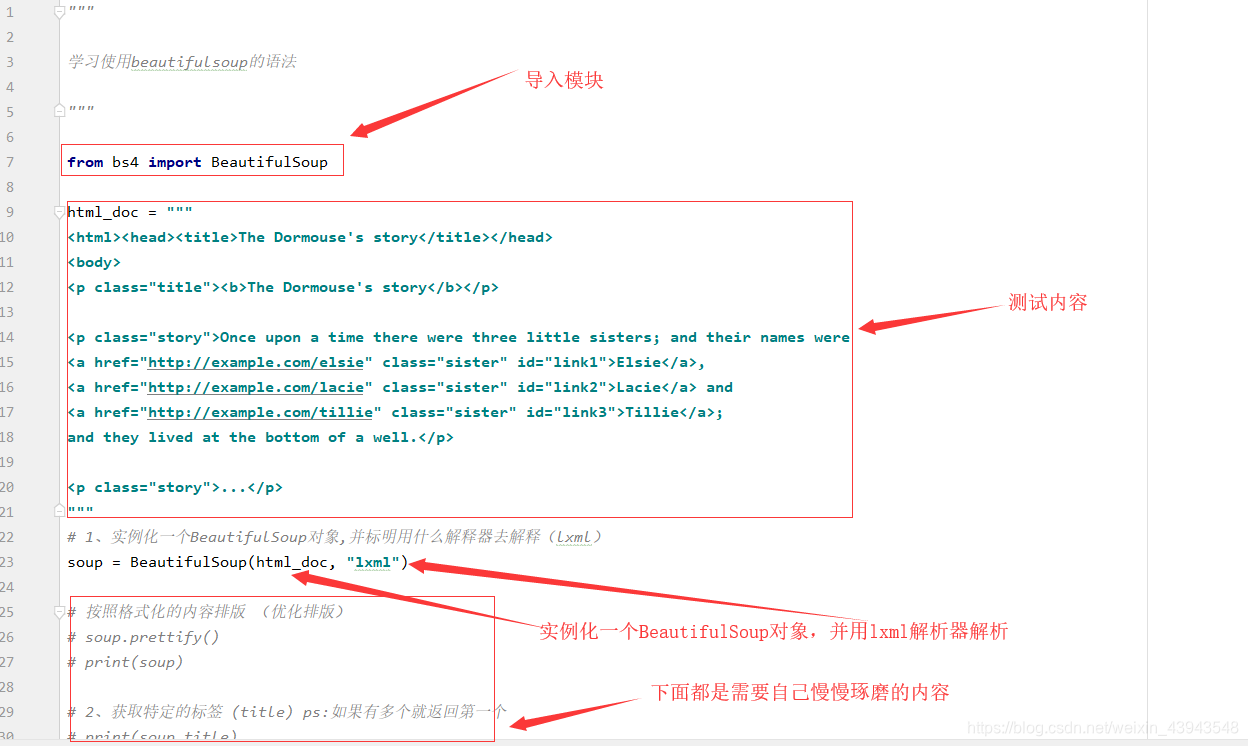
全部代码
""" 学习使用beautifulsoup的语法 """ from bs4 import BeautifulSoup html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
"""
# 1、实例化一个BeautifulSoup对象,并标明用什么解释器去解释(lxml)
soup = BeautifulSoup(html_doc, "lxml") # 按照格式化的内容排版 (优化排版)
soup.prettify()
print(soup)
# 2、获取特定的标签 (title) ps:如果有多个就返回第一个
print(soup.title)
# 3、获取特定的标签 (title) 里面的值
print(soup.title.string)
# 4、查询特定的标签 里面的值
print(soup.find("a"))
# 5、查询全部标签 以ResultSet的形式
print(soup.find_all("a")) # 查询所有标签为a的 print(soup.find_all("a", attrs={"id": "link2"})) # 查询所有标签为a的,并且属性为id,属性值为link2 print(soup.find_all(attrs={"id":"link3"})) # 查询所有属性为id,属性值为link3的 print(soup.find_all(id="link1")) # 查询所有属性为id,属性值为link1的
# 6、获取父节点
print(soup.find_all(id="link1")[0].parent.name) # 它的属性为ResultSet
print(soup.find("a").parent.name)
# 7、获取子节点
print(soup.find("p",attrs={"class":"story"}).contents) # 遍历了所有内容
print(soup.find("p",attrs={"class":"story"}).clidren) # 有格式的遍历
print(soup.find("p",attrs={"class":"story"}).descendants) # 遍历子孙节点
# 8、获取筒节点的上下节点
print(soup.find("p", attrs={"class", "story"})) print(soup.find(id="link2").next_sibling) # 下一个节点
print(soup.find(id="link2").previous_sibling.previous_sibling) # 上一个节点 print(soup.find(id="link2").previous_siblings) # 下面所有节点
print(soup.find(id="link2").previous_siblings) # 上面所有节点
# 9、获取一个标签中的属性值
print(soup.find("a")["id"]) # 第一种方式
print(soup.find("a").get("id"))# 第二种方式
# 10、获取一个标签中的所有属性值
print(soup.find("a").attrs) # 全部属性
print(soup.find("a").attrs["class"]) # 获取全部属性中的class属性的值
print(soup.find("a").attrs.get("id"))# 获取全部属性中的id属性的值
二、爬取网页图片
这个仅仅就是用来学习的一个内容,学会了就可以自己去爬自己刚兴趣的东西
爬取的对象:https://maoyan.com/board/4
分析:
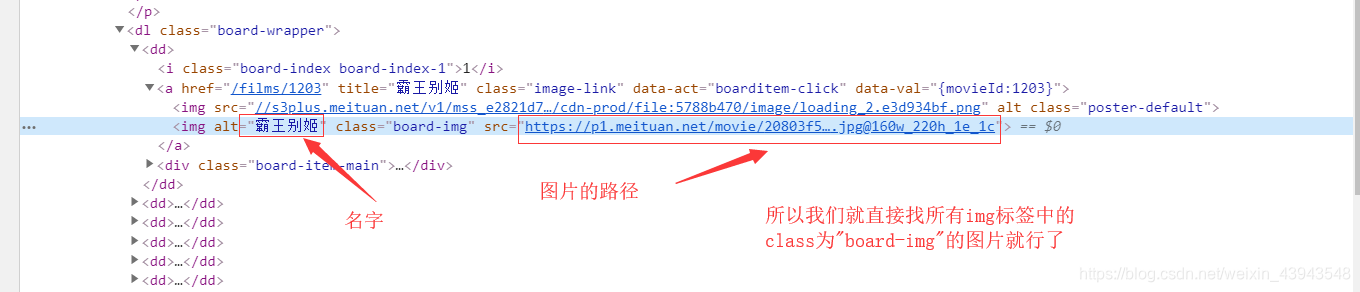
代码解读:
全部代码
"""
BeautifulSoup综合案例:爬取“猫眼电影的排行榜”
"""
import requests
from bs4 import BeautifulSoup
import os headers = {
"Cookie":"__mta=55342740.1575370883618.1575371366305.1575371383145.4; uuid_n_v=v1; uuid=3DACA12015BC11EABE1E1379EFD48C6B2BC02A509AA141CD821BF91F9AF4D24A; _csrf=0f7d373e4f690e2a84b3d5383f941f44faa7316e764ded1cf46f088e34b40614; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1575370883; _lxsdk_cuid=16ecb6c014ec8-059803946267d8-2393f61-144000-16ecb6c014ec8; _lxsdk=3DACA12015BC11EABE1E1379EFD48C6B2BC02A509AA141CD821BF91F9AF4D24A; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1575371383; _lxsdk_s=16ecb6c014e-d7d-844-f5b%7C%7C15",
"User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14"
} response = requests.get("https://maoyan.com/board/4", headers=headers) # 获取当前根目录
root = os.getcwd() # 在根目录中创建文件夹"第1页"
os.mkdir("第1页") # 改变当前目录
os.chdir("第1页") if response.status_code == 200:
# 解析网页
soup = BeautifulSoup(response.text, "lxml")
imgTags = soup.find_all("img", attrs={"class": "board-img"})
print(imgTags)
for imgTag in imgTags:
name = imgTag.get("alt")
src = imgTag.get("data-src")
resp = requests.get(src, headers=headers)
with open(f"{name}.png", "wb") as f:
f.write(resp.content)
print(f"{name} {src} 保存成功")
扩展学习
"""
BeautifulSoup综合案例:
爬取“最好大学网”排行
"""
import requests
from bs4 import BeautifulSoup headers = {
"User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14"
}
response = requests.get("http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html", headers=headers)
response.encoding = "utf-8"
if response.status_code == 200:
soup = BeautifulSoup(response.text, "lxml")
trTags = soup.find_all("tr", attrs={"class": "alt"})
for trTag in trTags:
id = trTag.contents[0].string
name = trTag.contents[1].string
addr = trTag.contents[2].string
sco = trTag.contents[3].string
print(f"{id} {name} {addr} {sco}")
后记
本章的内容也是解析数据,但是对于正则表达式来说的话实在是方便太多了,
下一章的内容还是解析,不过是使用xpath解析
如果感觉本章写的还不错的话,不如。。。。。(~ ̄▽ ̄)~ ,(´▽`ʃ♡ƪ)
python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]的更多相关文章
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- python网络爬虫之解析网页的XPath(爬取Path职位信息)[三]
目录 前言 XPath的使用方法 XPath爬取数据 后言 @(目录) 前言 本章同样是解析网页,不过使用的解析技术为XPath. 相对于之前的BeautifulSoup,我感觉还行,也是一个比较常用 ...
- Python 网络爬虫 007 (编程) 通过网站地图爬取目标站点的所有网页
通过网站地图爬取目标站点的所有网页 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 2016 ...
- (转)Python网络爬虫实战:世纪佳缘爬取近6万条数据
又是一年双十一了,不知道从什么时候开始,双十一从“光棍节”变成了“双十一购物狂欢节”,最后一个属于单身狗的节日也成功被攻陷,成为了情侣们送礼物秀恩爱的节日. 翻着安静到死寂的聊天列表,我忽然惊醒,不行 ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- ASP.NET网络爬虫小研究 HtmlAgilityPack基础,爬取数据保存在数据库中再显示再自己的网页中
1.什么是网络爬虫 关于爬虫百度百科这样定义的:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些 ...
- 一篇文章带你用Python网络爬虫实现网易云音乐歌词抓取
前几天小编给大家分享了数据可视化分析,在文尾提及了网易云音乐歌词爬取,今天小编给大家分享网易云音乐歌词爬取方法. 本文的总体思路如下: 找到正确的URL,获取源码: 利用bs4解析源码,获取歌曲名和歌 ...
- python3网络爬虫(2.1):爬取堆糖美女
额,明明记得昨晚存了草稿箱,一觉醒来没了,那就简写点(其实是具体怎么解释我也不太懂/xk,纯属个人理解,有错误还望指正) 环境: 版本:python3 IDE:pycharm2017.3.3 浏览器: ...
- Python网络爬虫数据解析的三种方式
request实现数据爬取的流程: 指定url 基于request发起请求 获取响应的数据 数据解析 持久化存储 1.正则解析: 常用的正则回顾:https://www.cnblogs.com/wqz ...
随机推荐
- The place where I want to go
The place where I want to go It’s hard to say where I want to go most. Because there are too many pl ...
- xpath的|
xpath的| 相当与交集 本爬虫爬取的是热门城市和全国城市,但是由于爬取的规则不同,所以在同一个xpath中使用了两种规则 import requests from lxml import etre ...
- 修改PHP上传文件大小限制
1. 在php.ini中,做如下修改: file_uploads = on upload_tmp_dir = /home/upload upload_max_filesize = 4000M post ...
- 第四章 开始Unity Shader学习之旅(2)
目录 1. 强大的援手:Unity提供的内置文件和变量 1.1 内置的包含文件 1.2 内置的变量 2. Unity提供的Cg/HLSL语义 2.1 什么是语义 2.2 Unity支持的语义 2.3 ...
- 一句话总结flux,以及我们为何需要flux
如果让你用一句话总结一下什么是flux,该怎么说? 官网上有这样的介绍:flux是一种思想,一种框架,是facebook给react... 这样的解释对程序员来说,显得过于抽象又不具体了. 阮老师的文 ...
- MySQL 8.0新增特性详解【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- javascript基础修炼(13)——记一道有趣的JS脑洞练习题【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- GZIP怎么运用在.NET MVC 简单实现
ZIP压缩其实就是将网页内容压缩,减少HTML代码网络传输的代价,来提高Web性能. 这个请求的过程解释一下: 1:客户端Request请求.Http_header中会根据相应的浏览器发送相应的编码规 ...
- MYSQL“错误代码#1045 Access denied for user 'root'@'********8' (using password:YES)”
用IP远程连接数据库时报这个错误,我查看了下数据库是否开启了远程连接,已经开了,服务也启动着,网上的方法都是重置密码修改权限之类的,我发现都没用,我看了一下数据库所在的电脑,IP地址变了,然后真相了.
- dockerfile 最佳实践及示例
Dockerfile 最佳实践已经出现在官方文档中,地址在 Best practices for writing Dockerfiles.如果再写一份最佳实践,倒有点关公门前耍大刀之意.因此本篇文章是 ...