python爬虫-豆瓣电影的尝试
一、背景介绍
1. 使用工具
Pycharm
2. 安装的第三方库
requests、BeautifulSoup
2.1 如何安装第三方库
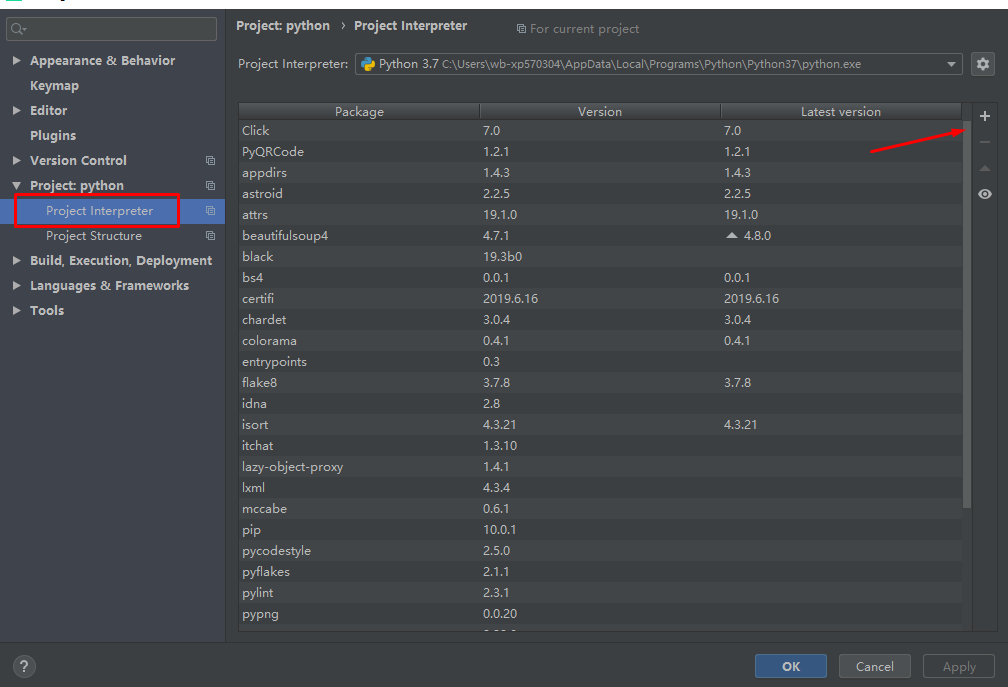
File => Settings => Project Interpreter => + 中搜索你需要的插件
3. 可掌握的小知识
1. 根据url 获取页面html内容
2. 解析html内容,选出自己需要的内容
二、代码示例
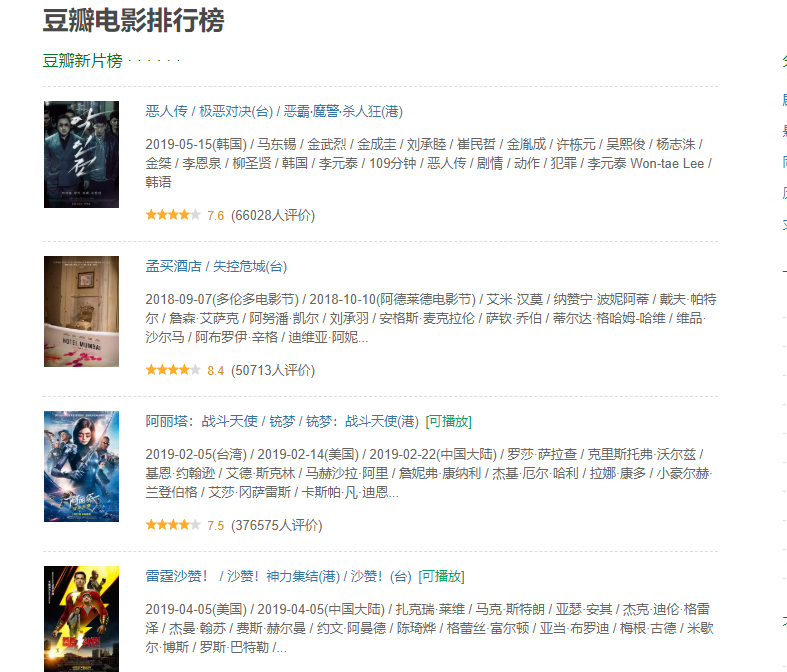
网页的样子是这个,获取排行榜中电影的名字
import requests
from bs4 import BeautifulSoup def getHtml():
url = 'https://movie.douban.com/chart'
# Get获取改页面的内容
html = requests.get(url)
# 用lxml解析器解析该页面的内容
soup = BeautifulSoup(html.content, "lxml")
getFilmName(soup)
# print(soup) def getFilmName(html):
for i in html.find_all('a', class_="nbg"):
img = i.find('img')
print(img['alt']) getHtml() 返回值:
恶人传
孟买酒店
阿丽塔:战斗天使
雷霆沙赞!
夏目友人帐
地久天长
调音师
三夫
寄生虫
地狱男爵:血皇后崛起
三、结语
先从简单的入手,帮助自己,也希望能帮助未入门的同学
python爬虫-豆瓣电影的尝试的更多相关文章
- Python爬虫-豆瓣电影 Top 250
爬取的网页地址为:https://movie.douban.com/top250 打开网页后,可观察到:TOP250的电影被分成了10个页面来展示,每个页面有25个电影. 那么要爬取所有电影的信息,就 ...
- python爬虫: 豆瓣电影top250数据分析
转载博客 https://segmentfault.com/a/1190000005920679 根据自己的环境修改并配置mysql数据库 系统:Mac OS X 10.11 python 2.7 m ...
- 放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~)
放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wa ...
- python pandas 豆瓣电影 top250 数据分析
豆瓣电影top250数据分析 数据来源(豆瓣电影top250) 爬虫代码比较简单 数据较为真实,可以进行初步的数据分析 可以将前面的几篇文章中的介绍的数据预处理的方法进行实践 最后用matplotli ...
- [Python]从豆瓣电影批量获取看过这部电影的用户列表
前言 由于之后要做一个实验,需要用到大量豆瓣用户的电影数据,因此想到了从豆瓣电影的“看过这部电影 的豆瓣成员”页面上来获取较为活跃的豆瓣电影用户. 链接分析 这是看过"模仿游戏"的 ...
- python 爬虫豆瓣top250
网页api:https://movie.douban.com/top250?start=0&filter= 用到的模块:urllib,re,csv 捣鼓一上午终于好了,有些小问题 (top21 ...
- python爬虫---豆瓣Top250电影采集
代码: import requests from bs4 import BeautifulSoup as bs import time def get_movie(url): headers = { ...
- [Python]计算豆瓣电影TOP250的平均得分
用python写的爬虫练习,感觉比golang要好写一点. import re import urllib origin_url = 'https://movie.douban.com/top250? ...
- Python 爬虫-豆瓣读书
import requests from bs4 import BeautifulSoup def parse_html(num): headers = { 'User-Agent': 'Mozill ...
随机推荐
- MySQL事务(脏读、不可重复读、幻读)
1. 什么是事务? 是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作:这些操作作为一个整体一起向系统提交,要么都执行.要么都不执行:事务是一组不可再分割的操作集合(工作逻辑单元): ...
- c# lock TransactionScope
c# lock TransactionScope TransactionOptions option = new TransactionOptions(); //option.IsolationLev ...
- vim 文本替换讲解
在VIM中进行文本替换: 1. 替换当前行中的内容: :s/from/to/ (s即substitude) :s/from/to/ : 将当前行中的第一个from,替换成to.如果当前行含有多个 fr ...
- X-NUCA-ezphp记录
鸽了很久,还是记录一下 比赛的时候搞了很长时间,终于和mlt师傅搞出来了,竟然只有我们一队是预期解== <?php $files = scandir('./'); foreach($files ...
- 003 spring boot访问静态资源与重定向
今天被问到重定向的问题,后续又引起了静态资源路径配置的问题,在这里做一个总结,当然,顺便添加默认访问index.html. 一:默认访问 1.默认路径 在springboot中静态资源的映射文件是在r ...
- Visual Studio 2019更新到16.1.6
Visual Studio 2019更新到16.1.6 此次更新主要是修复几个安全漏洞,如CVE-2019-1077(VS自动更新漏洞).CVE-2019-1075(ASP.net Core欺骗漏洞) ...
- C++main函数命令行选项——学习笔记
atoi字符串的数转化为整数 atof转化为小数
- Mapbox显示地图案例
mapbox地图入门案例 <!DOCTYPE html> <html> <head> <meta charset='utf-8' /> <titl ...
- vs Qt mysql 打包程序 Driver not loaded Driver not loaded
vs下开发Qt连接mysql程序,开发过程中操作MySQL没有问题,但打包以后安装在别的电脑上发现竟然无法连接MySQL,打包的时候,所需的libmysql.dll等dll文件拷贝到exe同级目录了, ...
- 解决:error: Cannot find libmysqlclient_r under /usr/local/mysql.
libodb-mysql-2.4.0.tar.gz 解压完安装libodb-mysql时,执行完./cofigure后,出现如下错误: checking for libmysqlclient_r... ...