大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
此处选取的是爬虫大作业——对猫眼电影上《小偷家族》电影的影评。
此处选取的是comment.csv文件,共计20865条数据。
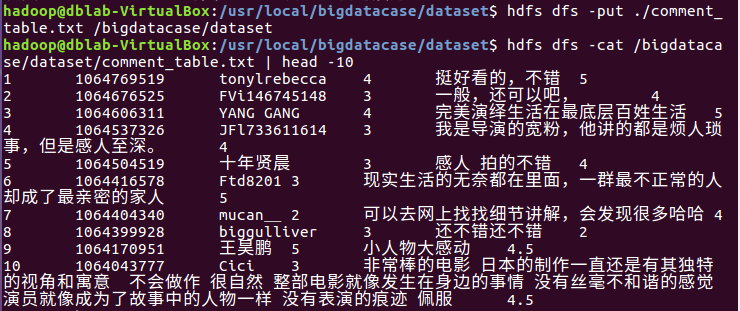
将comment.csv上传到HDFS
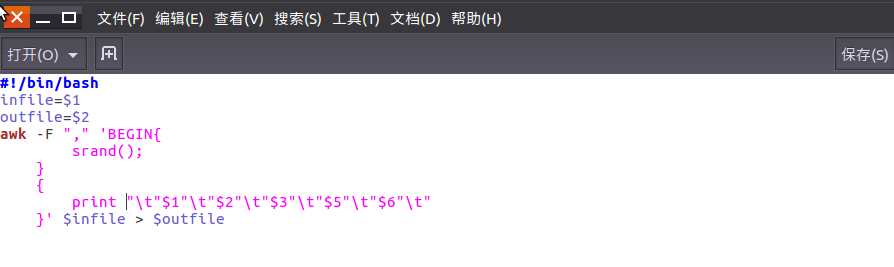
2.对CSV文件进行预处理生成无标题文本文件
编辑pre_deal.sh文件对csv文件进行数据预处理。
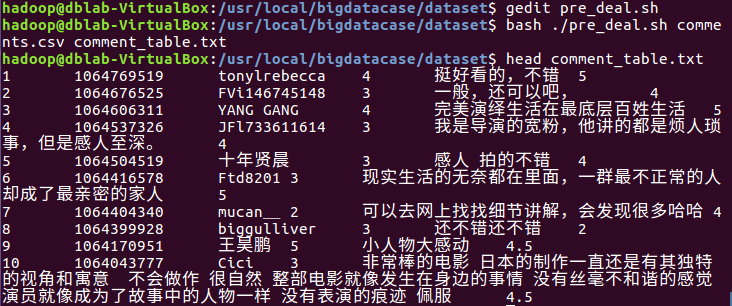
使得pre_deal.sh中的内容生效。
3.把hdfs中的文本文件最终导入到数据仓库Hive中
创建数据库dblab;
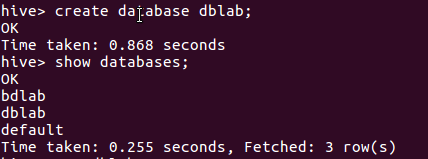
在数据库dblab中创建相应的表,此处是bigdata_user。

4.在Hive中查看并分析数据
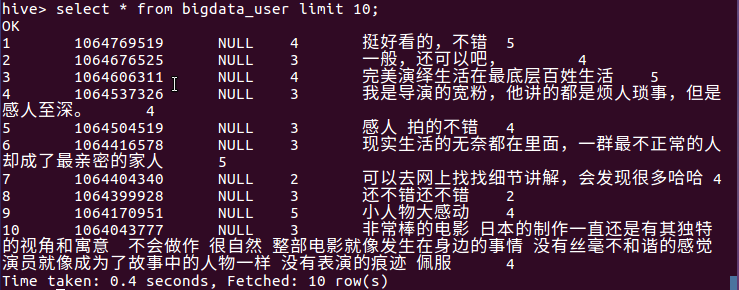
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
- 查询前20位猫眼电影用户对《小偷家族》电影的评分
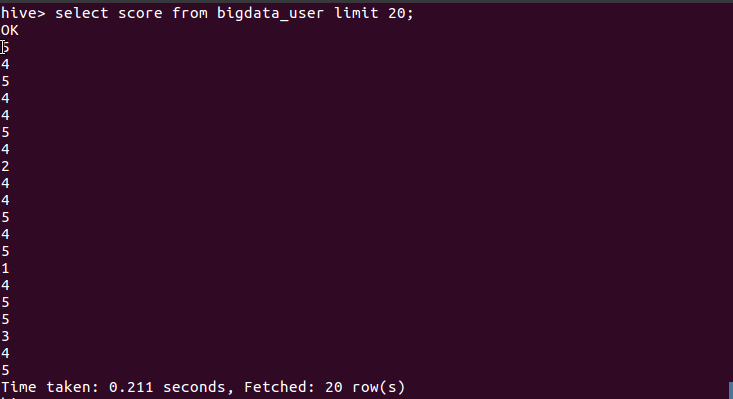
由上图可以看出大部分用户评分都在4分以上(5分评分为满分),这也就说明大部分用户对此部电影的评价都非常高。
- 查询给此电影1分评分的用户的评论

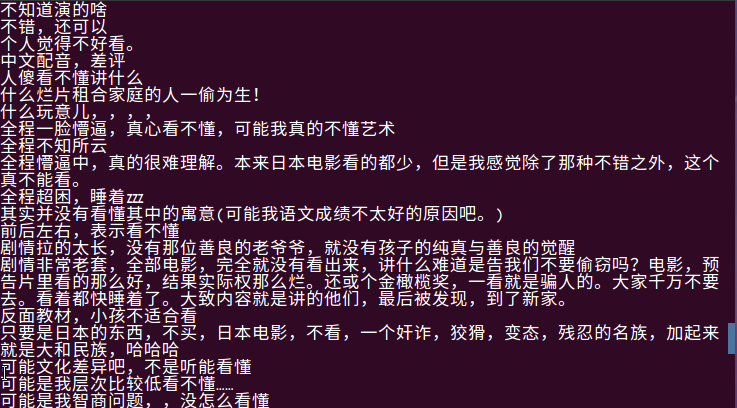
由上图可以看出给低分评价的用户多半为没看懂与难以理解所给出的低评分,由此可以得出用户对于电影的理解都不完全相同,一千个读者就有一千个哈姆雷特,大部分用户都是靠着主观意识来给与电影评分。
- 查询给此电影5分评分的用户的评论


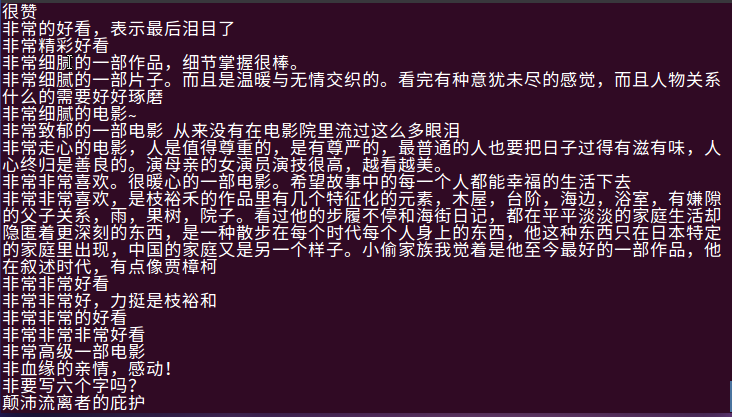
由5分评价也可以得出此部电影的主旨与想向观众表达的东西,可看出此部电影主要是围绕着亲情,感动为主题来叙述的。
- 查询对比5评分用户与1分评分用户的人数
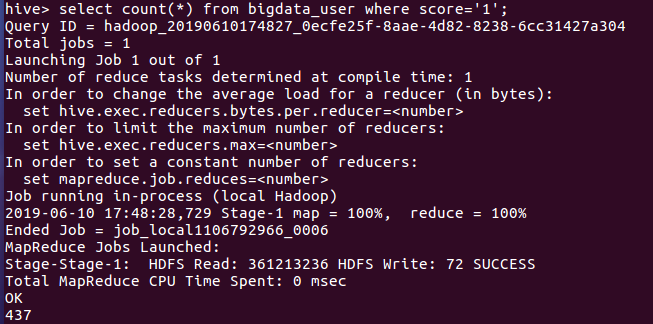
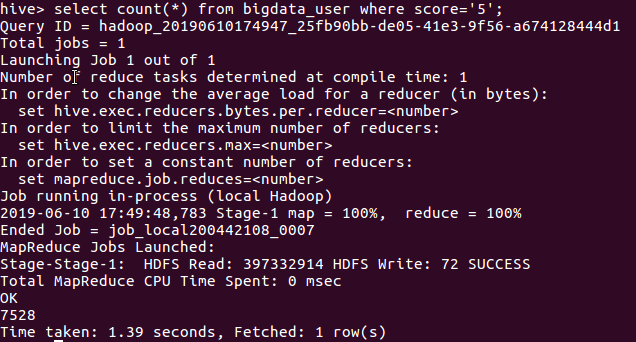
由上图可知给5分高分评价的用户人数为7528人,给1分低分评价用户人数为437人。由此可以知道这是一部优秀的电影。
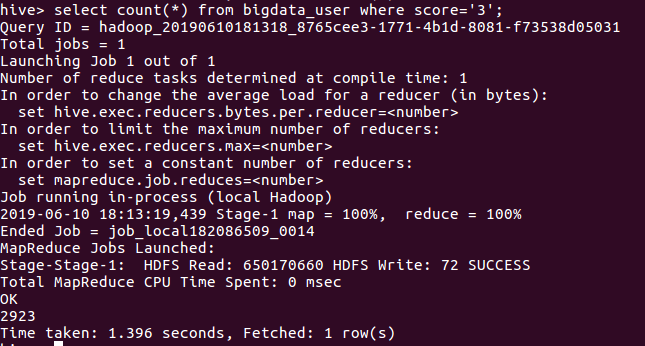
- 查询评分为3的用户人数
- 查询评分为1的用户id

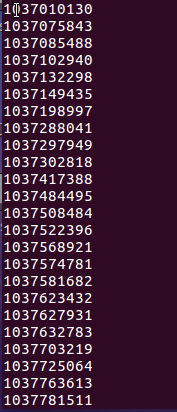
- 查询评分为4的用户的评论


与评分为5的评论相差不多,基本都是对整个电影的好评与受到的感动。
- 查询城市葫芦岛的评论用户人数
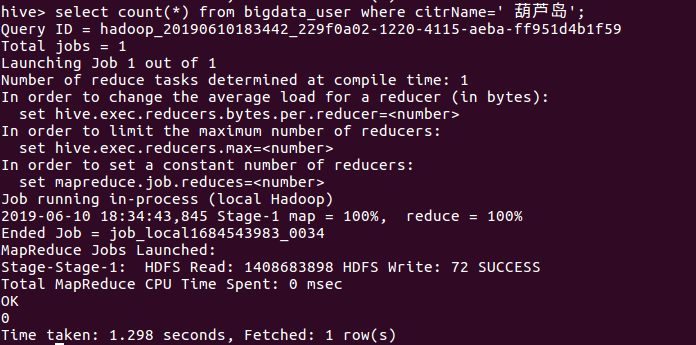
由此可看出此部电影还是比较小众,在较为不发达的城市基本无人问津。
- 查询评分为5的处于表格的序号

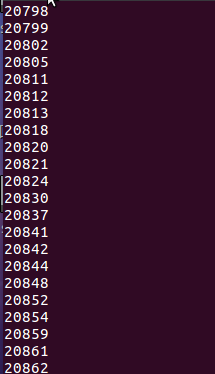
- 查询表格的数据中名字不重合的数据的数量
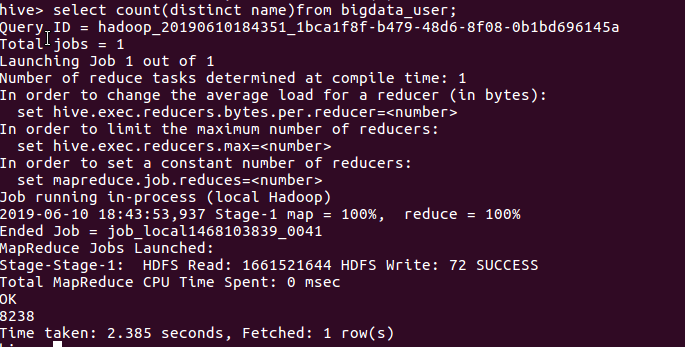
由上图可以看出由8238名用户没有重复评论数据的产生。说明爬取的数据仍然具备较大的重复性,需要注意。
- 查询表格数据中评论未重合的数据数量
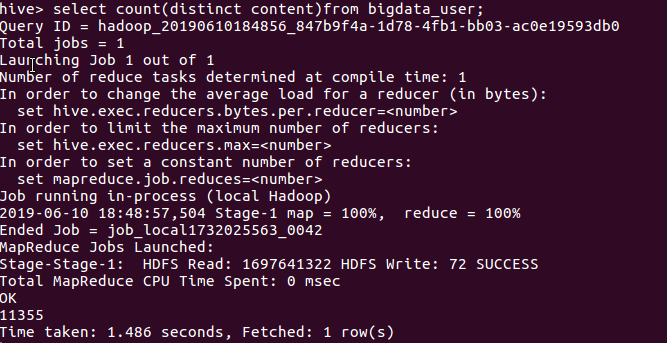
由上图可看出11355名用户评论没有重复数据的产生,基本可以视为有效数据。
总结:对于此次作业的完成,最大的问题就在于对于整个Hadoop环境的配置,就算是按部就班的按照步骤走,在这个过程中也遇到了非常多的问题,只要有一步的配置出现错误,会导致整个环境的配置失败。
但是总体来说还是基本按照要求完成了本次作业,在这个过程中我也是受益匪浅。
大数据应用期末总评——Hadoop综合大作业的更多相关文章
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 大数据应用期末总评(hadoop综合大作业)
作业要求源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.将爬虫大作业产生的csv文件上传到HDFS (1)在/usr ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- 报错:failed to get the task for process XXX(解决方案)
引文: iOS真机调试程序,报如下错误信息: 原因: 证书问题,project和targets的证书都必须是开发证书,ADHOC的证书会出现此问题. 解决方案: project和targets的证书使 ...
- 深入理解jvm--分代回收算法通俗理解
1.通俗的理解java对象的这一辈子 我是一个普通的java对象,我出生在Eden区,在Eden区我还看到和我长的很像的小兄弟,我们在Eden区中玩了挺长时间.有一天Eden区中的人实在是太多了,我就 ...
- java系统化基础-day02-运算符、选择结构、循环结构
1.java中的运算符 package com.wfd360.day02; import org.junit.Test; import java.math.BigInteger; /** * 1.算术 ...
- xadmin集成DjangoUeditor,以及编辑器的视频路径配置
稍微讲一下DjangoUeditor的配置,因为之前去找配置的时候东拼西凑的,所以自己写一下自己一步步配置的过程.首先我是再github上去下载下来,因为是当作第三方插件集成到xadmin中,所以不用 ...
- bat文件中运行python脚本方法
在脚本中使用start命令: @echo off start python xxx.py 注: start命令:启动单独的“命令提示符”窗口来运行指定程序或命令.如果在没有参数的情况下使用,start ...
- MySQL/MariaDB数据库的主从级联复制
MySQL/MariaDB数据库的主从级联复制 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.主从复制类型概述 1>.主从复制 博主推荐阅读: https://ww ...
- Vue命名规范
views 命名 views 文件夹下面是由 以页面为单位的vue文件 或者 模块文件夹 组成的,放在 src 目录之下,与 components.assets 同级. views 下的文件夹命名 v ...
- OpenStack核心组件-glance镜像服务
1. glance介绍 Glance是Openstack项目中负责镜像管理的模块,其功能包括虚拟机镜像的查找.注册和检索等. Glance提供Restful API可以查询虚拟机镜像的metadata ...
- Mysql InnoDB行锁不使用索引锁表的时候会锁整张表
原文:http://www.thinkphp.cn/topic/41577.html 如果使用针对InnoDB的表使用行锁,被锁定字段不是主键,也没有针对它建立索引的话.行锁锁定的也是整张表.锁整张表 ...
- python SQLAlchemy的简单配置和查询
背景: 今天小鱼从0开始配置了下 SQLAlchemy 的连接方式,并查询到了结果,记录下来 需要操作四个地方 1. config ------数据库地址 2.init ----- 数据库初始化 3 ...