tf.train.examle函数
在自定义数据集中:
example = tf.train.Example(features=tf.train.Features(feature={
'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw])),
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=labels))
}))
下面简要谈一谈我对其的理解
创建 Example 对象,并且将 Feature(img_raw,label) 一一对应填充进去。并保存到writer中。
tf.train.Example的定义如下:
message Example {
Features features = 1;
};
message Features{
map<string,Feature> featrue = 1;
};
message Feature{
oneof kind{
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
从上述代码可以看出,tf.train.Example中包含了属性名称到取值的字典,其中属性名称为字符串,属性的取值可以为字符串(BytesList)、实数列表(FloatList)或者整数列表(Int64List)。
一般tf.train.Int64List tf.train.FloatList对应处理整数和浮点数,tf.train.BytesList用于处理字符串的数据。
从上面可以看出一个 Example 消息体包含了一系列的 feature 属性。
每一个 feature 是一个 map,也就是 key-value 的键值对。
key 取值是 String 类型。
而 value 是 Feature 类型的消息体,它的取值有 3 种:
BytesList
FloatList
Int64List
需要注意的是,他们都是列表的形式。
举例说明:
1.构建writer,用于写入数据
2.创建 Example 对象,并且将 Feature(a,b,c) 一一对应填充进去。a,b,c三个不同格式的列表并保存到writer中
3.# 将 example 序列化成 string 类型,然后写入。即 writer.write(example.SerializeToString());
或者
serialized = example.SerializeToString()
writer.write(serialized)
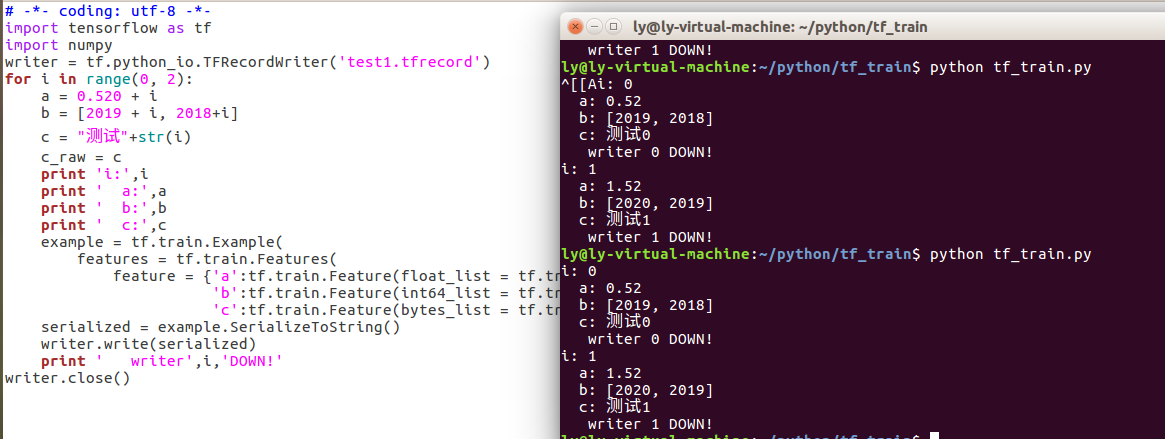
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy
writer = tf.python_io.TFRecordWriter('test1.tfrecord')
for i in range(0, 2):
a = 0.520 + i
b = [2019 + i, 2018+i]
c = "测试"+str(i)
c_raw = c
print 'i:',i
print ' a:',a
print ' b:',b
print ' c:',c
example = tf.train.Example(
features = tf.train.Features(
feature = {'a':tf.train.Feature(float_list = tf.train.FloatList(value=[a])),
'b':tf.train.Feature(int64_list = tf.train.Int64List(value = b)),
'c':tf.train.Feature(bytes_list = tf.train.BytesList(value = [c_raw]))}))
serialized = example.SerializeToString()
writer.write(serialized)
print ' writer',i,'DOWN!'
writer.close()
tf.train.examle函数的更多相关文章
- tf.train.shuffle_batch函数解析
tf.train.shuffle_batch (tensor_list, batch_size, capacity, min_after_dequeue, num_threads=1, seed=No ...
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数(转)
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- 【转载】 tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
原文地址: https://blog.csdn.net/dcrmg/article/details/79776876 ----------------------------------------- ...
- tensorflow数据读取机制tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程 ...
- Tensorflow滑动平均模型tf.train.ExponentialMovingAverage解析
觉得有用的话,欢迎一起讨论相互学习~Follow Me 移动平均法相关知识 移动平均法又称滑动平均法.滑动平均模型法(Moving average,MA) 什么是移动平均法 移动平均法是用一组最近的实 ...
- tensorflow中协调器 tf.train.Coordinator 和入队线程启动器 tf.train.start_queue_runners
TensorFlow的Session对象是支持多线程的,可以在同一个会话(Session)中创建多个线程,并行执行.在Session中的所有线程都必须能被同步终止,异常必须能被正确捕获并报告,会话终止 ...
- tf.train.batch的偶尔乱序问题
tf.train.batch的偶尔乱序问题 觉得有用的话,欢迎一起讨论相互学习~Follow Me tf.train.batch的偶尔乱序问题 我们在通过tf.Reader读取文件后,都需要用batc ...
- 【转载】 tf.train.slice_input_producer()和tf.train.batch()
原文地址: https://www.jianshu.com/p/8ba9cfc738c2 ------------------------------------------------------- ...
随机推荐
- Windows Server多用户同时远程登录
因为工作需要,需要使用windwos作为一个远程登录跳板机,管理员对登录windwos机器再windwos的基础上连接别的机器,普通用户也可以连接windwos机器再连接别的机器,关于管理员普通用户连 ...
- 《操作系统真象还原》bochs安装
在安装bochs之前,我们先需要安装虚拟机和linux发行版,也可以安装双系统,总之有个linux操作系统就好. 我是在ubuntu14.04系统下安装bochs的. 安装Bochs 以下为安装步骤 ...
- P问题,NP问题,NPC问题学习笔记
参考:https://www.luogu.org/blog/styx-ferryman/chu-sai-bei-kao-gan-huo-p-wen-ti-np-wen-ti-npc-wen-ti-sh ...
- ALSA lib编译
http://blog.sina.com.cn/s/blog_7d7e9d0f0101lqlp.html alsa lib: #!bin/sh rm -rf ./output/* mkdir -p ...
- Wannafly Camp 2020 Day 6K 最大权值排列
按照样例那样排列即可 #include <bits/stdc++.h> using namespace std; int main() { int n; cin>>n; if( ...
- Python的特点
简单易学. 免费开源. 跨平台. 解释性.不需要编译就可以直接运行,使用更加简单,移植性更强. 面向对象.arcgis也支持面向对象编程.
- python面试的100题(13)
29.Given an array of integers 给定一个整数数组和一个目标值,找出数组中和为目标值的两个数.你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用.示例:给定nums ...
- 阿里云linux挂载云盘
阿里云购买的第2块云盘默认是不自动挂载的,需要手动配置挂载上. 1.查看SSD云盘 sudo fdisk -l 可以看到SSD系统已经识别为/dev/vdb 2.格式化云盘 sudo mkfs.ext ...
- python接口自动化测试之根据excel中的期望结果是否存在于请求返回的响应值中来判断用例是否执行成功
1.首先在excel中填写好预期结果的值 这里判断接口成功的依据是预期结果值是否存在于接口的返回数据中. 一般接口的返回值都是json对象,我们需要将json对象转换为json格式的字符串 如下图,进 ...
- 一点点学习PS--实战二
本节实战,可以学到如何制作gif动图,制作搜狗输入法皮肤 1.工具使用 (1)滤镜--液化--膨胀:这里是制作出猫咪打呼时肚子和气泡胀大的效果 (2)图像--画布大小:可裁剪画布到指定像素,并且裁剪指 ...