假期学习【十一】Python切词,以及从百度爬取词典
今天主要对从CSDN爬取的标题利用jieba(结巴)进行分词,但在分词过程中发现,如大数据被分成了大/数据,云计算被分隔成了云/计算。
后来又从百度百科---》信息领域爬取了相关词语作为词典,预计今天晚上完成切词任务。
其中分割代码如下:
import jieba
import io #对句子进行分词
def cut():
f=open("E://luntan.txt","r+",encoding="utf-8")
for line in f:
seg_list=jieba.cut(line)
#print(' '.join(seg_list))
for i in seg_list:
print(i)
write(i+" ")
#write(' '.join(seg_list)) #分词后写入
def write(contents):
f=open("E://luntan_cut.txt","a+",encoding="utf-8")
f.write(contents)
print("写入成功!")
f.close() #创建停用词
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords # 对句子进行去除停用词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('E://stop.txt') # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr #循环去除
def cut_all():
inputs = open('E://luntan_cut.txt', 'r', encoding='utf-8')
outputs = open('E//luntan_stop', 'w')
for line in inputs:
line_seg = seg_sentence(line) # 这里的返回值是字符串
outputs.write(line_seg + '\n')
outputs.close()
inputs.close() if __name__=="__main__":
cut()
分割后的文本
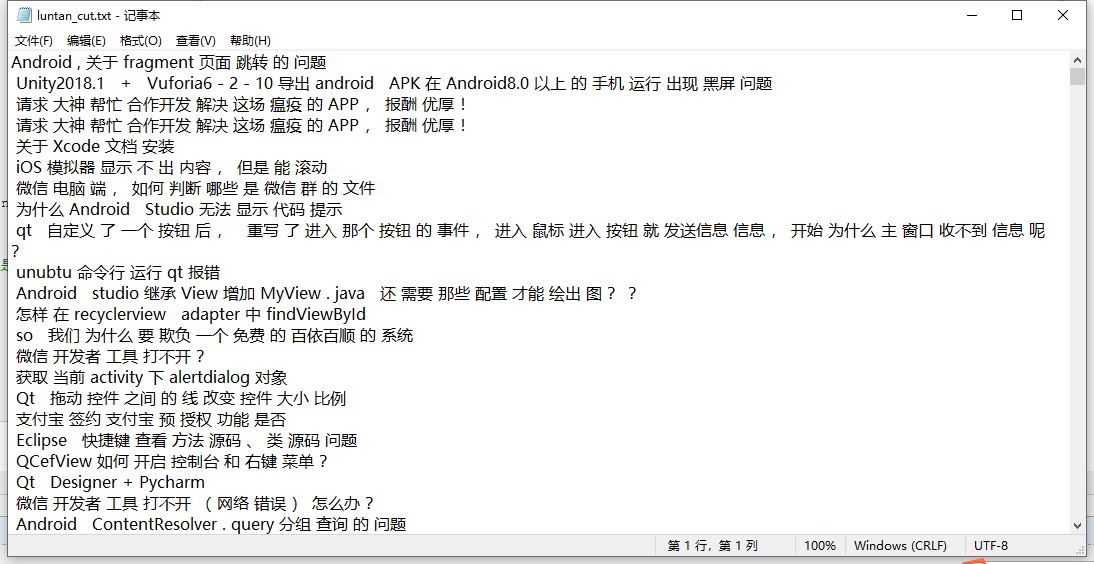
从百度爬取词典要把百度页面 地址:https://baike.baidu.com/wikitag/taglist?tagId=76607
该页拉到最下,并存为本地mhtml格式,在浏览器打开然后右击查看源代码,源代码保存为txt格式文件,
代码如下:
import io
import re patton=re.compile(r'title=".*"')
def read():
f=open("E://mhtml.txt","r+",encoding="utf-8")
for line in f:
line=line.rstrip("\n")
m=patton.findall(line)
#print(line)
if len(m)!=0:
print(m)
write(str(m).lstrip("['title=\"").rstrip("\"']")+"\r") def write(contents):
f=open("E://xinxi.txt","a+",encoding="utf-8")
f.write(contents)
print("写入成功!")
f.close() if __name__=="__main__":
read()
效果:
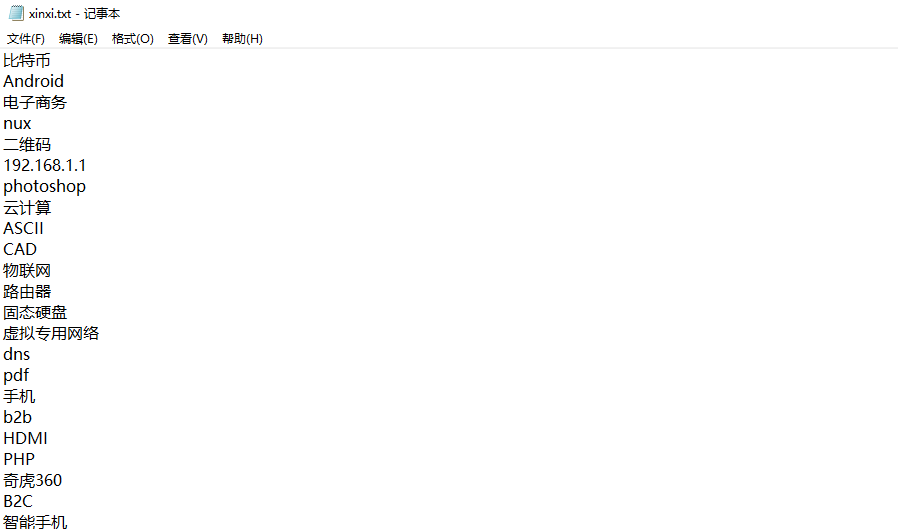
假期学习【十一】Python切词,以及从百度爬取词典的更多相关文章
- 【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
[学习笔记]Python 3.6模拟输入并爬取百度前10页密切相关链接 问题描述 通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接. me ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
随机推荐
- vue路由--嵌套路由
静态嵌套路由: <!DOCTYPE html> <html lang="en"> <head> <meta charset="U ...
- [MySQL]ANALYZE TABLE 更新索引基数
MySQL使用存储的键分布基数来确定表连接顺序在决定对查询中的特定表使用哪些索引时,也会使用使用键分布基数 ANALYZE TABLE 表名 可以更新表的索引基数,使其更接近非重复的记录数,记录数可以 ...
- Lucene之索引库的维护:添加,删除,修改
索引添加 Field域属性分类 添加文档的时候,我们文档当中包含多个域,那么域的类型是我们自定义的,上个案例使用的TextField域,那么这个域他会自动分词,然后存储 我们要根据数据类型和数据的用途 ...
- Excel——排序筛选
1,自定义排序:多个关键字,从右向左一一排序 * 按颜色排序 * 按自定义序列排序 *两列中,列一个中间数,升序 * 打印标题行 * 选中,定位条件(可见),选择 * 数值筛选(大于等于),文本筛选( ...
- python文件操作汇总day7
Python处理文件 文件操作分为读.写.修改,我们先从读开始学习 读文件 示例1: f = open(file='D:/工作日常/兼职白领学生空姐模特护士联系方式.txt',mode='r',enc ...
- 根据词频生成词云(Python wordcloud实现)
网上大多数词云的代码都是基于原始文本生成,这里写一个根据词频生成词云的小例子,都是基于现成的函数. 另外有个在线制作词云的网站也很不错,推荐使用:WordArt 安装词云与画图包 pip3 insta ...
- 灵活运用SQL Server2008 SSIS变量
在SSIS开发ETL(Extract-Transform-Load),数据抽取.转换.装载的过程.我们需要自己定义变量 一.SSIS变量简介 SSIS(SQL Server Integration ...
- 如何在vue-cli中使用vuex(配置成功
前言 众所周知,vuex 是一个专为 vue.js 应用程序开发的状态管理模式,在构建一个中大型单页应用中使用vuex可以帮助我们更好地在组件外部管理状态.而vue-cli是vue的官方脚手架,它能帮 ...
- kaggle之猫狗数据集下载
链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw 提取码:2xq4 百度网盘实在是恶心,找的别人的网盘下载不仅速度慢,还老挂掉,自己去kaggle下 ...
- 开发FTP服务接口,对外提供接口服务
注意:本文只适合小文本文件的上传下载,因为post请求是有大小限制的.默认大小是2m,虽然具体数值可以调节,但不适合做大文件的传输 最近公司有这么个需求:以后所有的项目开发中需要使用ftp服务器的地方 ...