简单看看ThreadPoolExecutor原理
线程池的作用就不多说了,其实就是解决两类问题:一是当执行大量的异步任务时线程池能够提供较好的性能,在不使用线程池时,每当需要执行异步任务是需要直接new一个线程去执行,而线程的创建和销毁是需要花销的,而线程池中的线程是可复用的,不需要每次执行异步任务时都去创建和销毁线程;二是线程池提供了一种资源限制和管理的手段,比如可以限制线程的个数、动态新增线程等;
一.Executors工具类
我们创建一个线程池最好直接用这个工具类去创建,常用的线程池有几种,一种是用newFixedThreadPool方法创建固定大小的线程池,一种是newSingleThreadExecutor方法创建单线程的线程池,一种是newCachedThreadPool方法创建线程最多个数为Integer.MAX_VALUE的线程池,还有一些其他的线程池;
看一下Executors工具类中一些重要的方法,先是newFixedThreadPool方法,只看这个,我们可以实际的线程池类型是ThreadPoolExecutor,而且内部是以LinkedBlockingQueue这个并发队列实现的,前面说过,这是一个有界阻塞队列,底层是一个单向链表,入队和出队是用独占锁实现的一个生产者消费者模式,比较容易;

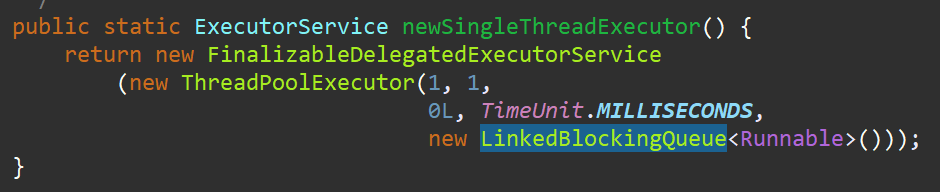
newSingleThreadExecutor方法,其实可以看到就是用上面的这种线程池实现的,只不过限制了线程池中线程必须只能是一个;
newCachedThreadPool方法,这种线程池也是以最上面的那种形式实现的,只不过限制了最大的数量是Integer.MAX_VALUE

由上面可知,三种其实都是以ThreadPoolExecutor实现的,所以我们了解这个类的实现机制就行了;
二.简单看看ThreadPoolExecutor结构
先看看其中的属性,比较多:
public class ThreadPoolExecutor extends AbstractExecutorService {
//这个原子变量用于记录线程池的状态和其中线程的数量,
//就类似读写锁里面一个int变量,高16位表示读锁的获取次数,低16位表示某一个线程获取写锁的可重入次数
//在线程池这里,高3位表示线程池状态,后面的29位表示线程池线程数量,默认线程池状态是RUNNING,线程数量为0
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//这里叫做线程个数掩码位数,举个例子,线程状态为STOP时,即1<<(32-3),也就是1<<29,用二进制表示00100000 00000000 00000000 00000000
//可以知道在原子变量中高3位是001
private static final int COUNT_BITS = Integer.SIZE - 3;
//线程池中线程的最大容量,其实就是00011111 11111111 11111111 11111111
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
//高三位都是1,其他的29位都是0
private static final int RUNNING = -1 << COUNT_BITS;
//都是0
private static final int SHUTDOWN = 0 << COUNT_BITS;
//高三位是001,其他的29位都是0
private static final int STOP = 1 << COUNT_BITS;
//高三位是010,其他的29位都是0
private static final int TIDYING = 2 << COUNT_BITS;
//高三位是011,其他的29位都是0
private static final int TERMINATED = 3 << COUNT_BITS;
//这里用位运算,取高三位,表示运行状态CAPACITY为:00011111 11111111 11111111 11111111
private static int runStateOf(int c) { return c & ~CAPACITY; }
//取低29位,表示线程个数
private static int workerCountOf(int c) { return c & CAPACITY; }
//这个方法用于计算原子变量ctl的值
private static int ctlOf(int rs, int wc) { return rs | wc; }
//判断线程池状态是否是RUNNING,直接判断高三位是不是小于0就行了
private static boolean isRunning(int c) {
return c < SHUTDOWN;
}
//CAS使得低29位加一,表示线程池中线程数量加一
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}
//线程池中线程数量减一
private boolean compareAndDecrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect - 1);
}
//底层实现就是这个有界阻塞队列,前面已经说过这个队列的原理了,这个队列汇中存放的是实现了Runnable接口的任务
private final BlockingQueue<Runnable> workQueue;
//独占锁用于控制添加Worker到集合workers中
private final ReentrantLock mainLock = new ReentrantLock();
//用于存放worker,这里封装着线程和任务
private final HashSet<Worker> workers = new HashSet<Worker>();
//条件变量
private final Condition termination = mainLock.newCondition();
//完成任务的线程计数器
private long completedTaskCount;
//创建线程的工厂
private volatile ThreadFactory threadFactory;
//饱和策略,就是当线程池中线程数量达到最大值maximumPoolSize之后采取的策略
private volatile RejectedExecutionHandler handler;
//当线程池中线程数量大于规定的核心数量之后,那些线程还是空闲的,那么最多存活的时间
private volatile long keepAliveTime;
//允许核心线程超时时间
private volatile boolean allowCoreThreadTimeOut;
//线程池核心数量
private volatile int corePoolSize;
//线程池最大线程数量
private volatile int maximumPoolSize;
//默认的策略就是抛出异常,还有CallerRunsPolicy策略(使用调用者所在的线程运行任务),
//DiscardOldestPolicy策略(调用poll丢弃一个任务,执行当前任务),DiscardPolicy策略,默默丢弃。不抛出异常
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
有个内部类Worker:
//由这个类可知,继承了AQS,这里state==0表示锁未被获取,state==1表示创建Worker默认状态
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
//执行该任务的具体线程
final Thread thread;
//线程执行的第一个任务
Runnable firstTask;
//完成的任务计数
volatile long completedTasks;
还有几个饱和策略的内部类分别是AbortPolicy策略(抛出异常),CallerRunsPolicy策略(使用调用者所在的线程运行任务),DiscardOldestPolicy策略(调用poll丢弃一个任务,执行当前任务),DiscardPolicy策略(默默丢弃),这些后面会说到的;
三.ThreadPoolExecutor简单使用
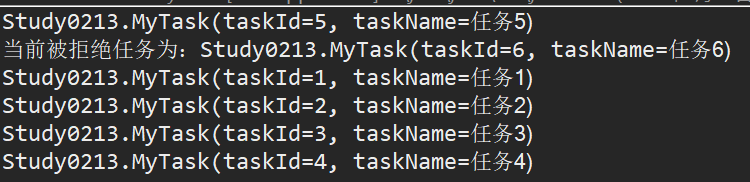
首先我们看看线程池是怎么使用的,由最后的执行结果可知,当执行任务6的时候,线程池中线程都在使用中,而且阻塞队列已经满了,于是就出发拒绝策略去对多余任务进行处理;
package com.example.demo.study; import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit; import lombok.AllArgsConstructor;
import lombok.Data; public class Study0213 { //这里指定任务,实现Runnable接口
@Data
@AllArgsConstructor
static class MyTask implements Runnable {
private int taskId;
private String taskName; @Override
public void run() {
//这里没干什么,就是将任务的taskId和taskName打印出来
System.out.println(this.toString());
}
}
//实现拒绝策略,我们可以自定义处理方法,如果线程池中阻塞队列满了,就把任务怎么处理
static class MyRejected implements RejectedExecutionHandler {
public MyRejected() {
} @Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
//把多余了的任务随便打印一下
System.out.println("当前被拒绝任务为:" + r.toString());
}
} public static void main(String[] args) {
ThreadPoolExecutor pool = new ThreadPoolExecutor(
1, // 线程池核心线程数coreSize
2, // 线程池最大线程数MaxSize
60, //存活时间60 当实际超过核心线程数的线程,如果这些线程有空闲着的,那么过一段时间就会被销毁
TimeUnit.SECONDS, //存活时间单位
new ArrayBlockingQueue<Runnable>(3), // 有界阻塞队列
new MyRejected()//拒绝策略
);
//新建五个任务
MyTask mt1 = new MyTask(1, "任务1");
MyTask mt2 = new MyTask(2, "任务2");
MyTask mt3 = new MyTask(3, "任务3");
MyTask mt4 = new MyTask(4, "任务4");
MyTask mt5 = new MyTask(5, "任务5");
MyTask mt6 = new MyTask(6, "任务6"); //调用execute方法将任务丢到线程池中执行
pool.execute(mt1);
pool.execute(mt2);
pool.execute(mt3);
pool.execute(mt4);
pool.execute(mt5);
pool.execute(mt6); //shutdown表示线程池拒绝新的任务,但是阻塞队列中的任务还是要处理的
pool.shutdown(); } }
四.execute方法
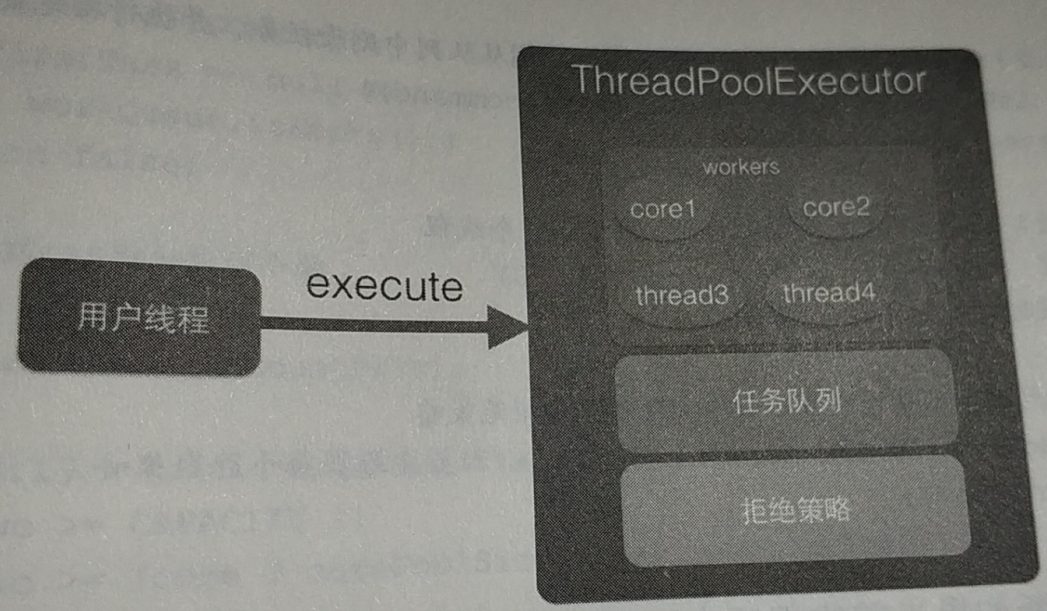
首先看下面这个图,ThreadPoolExecutor分为由三部分组成,第一部分是workers,这是一个HashSet<Worker> workers = new HashSet<Worker>(),最开始线程池中线程数量小于核心线程数量的时候,会直接把任务封装成Worker丢到这个集合中来,每一个Worker都实现了Runnable接口,里面还保存了一个Runnable类型的属性和Thread类型的属性,线程池中的创建的Thread实例时传进去的是Worker,所以在线程启动调用start方法的时候,实际上是调用Worker的run方法;
第二部分指的是BlockingQueue<Runnable> workQueue,这是一个阻塞队列,存放的是原始的任务,没有封装成Worker,这个队列只有在线程池中线程数量多于核心线程数量的时候才会启用;
第三部分指的是RejectedExecutionHandler handler,这是一个拒绝策略,在比如队列满了,线程数量也到极限了,这时还有任务在往线程池中丢,此时就可以对这些多余的任务做处理;
顺便再说一下线程池有几种状态:
RUNNING:线程池可以接收新任务并且处理阻塞队列中的任务,任务会直接扔到workers中去,高三位是111;
SHUTDOWN:线程池拒绝新任务但是处理阻塞队列中的任务,这里说明任务已经很多了,阻塞队列已经满了,而且线程数量已经达到最大值了,高三位是000;
STOP:线程池拒绝新任务并且抛弃阻塞队列中的任务,同时中断正在处理的任务,这里也就是说强行停止线程池,高三位是001;
TIDING:所有的任务都执行完毕了,包括阻塞队列中的任务也执行完了,此时线程池中所有线程都处于空闲状态,将要调用terminated方法,高三位是010;
TERMINATED:终止状态,terminated方法调用完成以后的状态 ,高三位是011;
public void execute(Runnable command) {
//如果任务是空,就抛出异常
if (command == null)
throw new NullPointerException();
//获取原子变量,32位的,分为高3位和低29位,前面已经介绍了
int c = ctl.get();
//[1]workerCountOf方法获取第29位,也就是线程池中线程数量,当数量小于设置的核心数量时,就开启新的线程执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//[2]如果线程池处于RUNNING状态,而且此时线程池中线程的数量已经达到了核心数量,于是就把任务丢到阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//当前线程池状态不是RUNNING就从队列中删除任务,执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
//如果线程池中没有线程,那就添加一个空闲线程不断的去任务队列中轮询任务
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//[3]能到这里说明阻塞队列也已经满了,然后尝试着再新增线程去处理任务,直到线程数量到达最大数量
//如果新增线程失败,就执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
最关键的就是addWorker方法,这个方法主要是在线程池中添加一个新的线程;
//这个方法分为两个部分,首先是通过双重循环使用CAS增加线程数,也就是将那个原子变量的低29位加一
//然后就是将实现了Runnable接口的任务添加到一个集合HashSet<Worker> workers中,然后启动任务执行
private boolean addWorker(Runnable firstTask, boolean core) {
//goto标志,注意,这个retry一定要在for循环前面,相当于给这个for循环取个名字,在该for循环里面如果
//break retry表示跳出这个for循环;而continue retry表示重新进入到这个for循环
retry:
for (;;) {
int c = ctl.get();
//线程池的状态,也就是ctl原子变量的高三位
int rs = runStateOf(c);
//这里的作用就是线程池创建线程失败的情况;
//这里分为三种情况这里会返回false:
//第一种是线程池状态是STOP,TIDING,TERMINATED
//第二种是线程池状态是SHUTDOWN并且已经有了第一个任务
//第三种是线程池状态是SHUTDOWN而且任务队列为空
if (rs >= SHUTDOWN && !(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()))
return false; //CAS增加线程数
for (;;) {
//获取线程池数量
int wc = workerCountOf(c);
//如果线程池中线程数量大于最大容量或者是线程数大于核心线程数量就返回false
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//线程数量没有超过限制,就CAS使得ctl的低29位的值加一,CAS成功就跳出这两个for循环
if (compareAndIncrementWorkerCount(c))
break retry;
//CAS失败的话,就查看线程池状态是否发生变化,变化则跳出两个for循环,然后再重新进入for循环获取线程池状态;
//线程池状态没有变化,就在此for循环中继续CAS
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
}
} //假如到了这里,说明上面CAS将原子变量低29位加一已经成功了,下面就该新建线程真正的执行任务了
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//这里新建一个Worker,注意,这个Worker中存放了当前线程和实现了Runnable接口的具体任务
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//独占锁,因为可能有多个线程同时执行execute方法
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//获取线程池状态
int rs = runStateOf(ctl.get()); if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) throw new IllegalThreadStateException();
//线程池状态满足条件的话将Worker添加到集合中
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
//释放锁
mainLock.unlock();
}
//到这里任务已经添加成功,再启动任务,由于在创建Worker的时候,构造器中使用的是
// this.thread = getThreadFactory().newThread(this);
//注意,Worker实现了Runnable接口,于是就相当于Thread t = new Thread(worker),调用t.start()就是调用worker的run方法
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
} //启动线程的start方法,实际上启动的是worker中观的run方法
public void run() {
runWorker(this);
} final void runWorker(Worker w) {
//获取当前线程
Thread wt = Thread.currentThread();
//获取当前Worker中的任务
Runnable task = w.firstTask;
w.firstTask = null;
//由于Worker也实现了AQS接口,这里就是将AQS中的state设置为0,允许中断,
//因为其他线程可能会调用线程池的shutdownNow方法
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//如果当前Worker中的task==null或者从任务队列中获取task为空,就到这方法的最后执行清理工作,
//注意,这里就是线程池中的线程可以复用的关键,会不断的调用getTask()方法去任务队列中获取任务
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP)))
&&!wt.isInterrupted())
wt.interrupt();
try {
//执行任务之前干一些事情
beforeExecute(wt, task);
Throwable thrown = null;
try {
//执行任务,这里就是我们自己定义的实际任务的run方法
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//执行任务之后干一些事
afterExecute(task, thrown);
}
} finally {
task = null;
//统计当前的Worker完成了多少任务
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//执行清理工作
processWorkerExit(w, completedAbruptly);
}
} //执行清理工作
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
//获取锁,统计整个线程池完成任务的个数,由于在工作集Workers中当前的Worker已经执行完毕,就从集合中删除当前的Worker
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
//释放锁
mainLock.unlock();
}
//尝试将线程池状态设置为TERMINATED,如果当前线程池状态为SHUTDOWN并且工作队列为空,或者是STOP状态,则
//可以断定当前线程池中没有活动线程,就把当前线程池状态设置为TERMINATED
//在这个方法中会调用termination.signalAll()方法唤醒一些阻塞的线程,这些阻塞的线程是由于调用了线程池
//的awaitTermination方法被阻塞的
tryTerminate(); int c = ctl.get();
//如果当前线程个数小于核心线程数量,如果是就新增一个线程
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
我们再看看reject是怎么执行拒绝策略的,就以默认的AbortPolicy策略为例子,其实就是抛出异常:
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
public static class AbortPolicy implements RejectedExecutionHandler {
//无参构造
public AbortPolicy() { }
//这里会直接抛出异常
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
五.shutdown方法
在最上面使用线程池的例子中,我们在最后调用了线程池的shutdown方法了,这表示当前线程池不再接收新的任务了,但是当前线程池中任务队列中还是要执行的;
public void shutdown() {
//获取锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//权限检查
checkShutdownAccess();
//设置当前线程池状态为SHUTDOWN,如果当前线程池状态已经是SHUTDOWN那就直接返回
advanceRunState(SHUTDOWN);
//设置所有空闲线程的中断标志
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
//尝试将线程池状态设置为TERMINATED
tryTerminate();
}
//权限检查,由于当前线程调用了shutdown()方法,于是要先检查当前线程有没有权限关闭线程池
//如果有关闭线程池的权限,还要检查是否有中断工作线程的权限
private void checkShutdownAccess() {
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkPermission(shutdownPerm);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers)
security.checkAccess(w.thread);
} finally {
mainLock.unlock();
}
}
}
//shutdown方法中设置当前线程池状态为SHUTDOWN
//可以看到当线程池状态如果>=SHUTDOWN就直接返回,如果不是SHUTDOWN状态,那就CAS设置成SHUTDOWN状态
private void advanceRunState(int targetState) {
for (;;) {
int c = ctl.get();
if (runStateAtLeast(c, targetState) || ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))
break;
}
}
//设置所有空闲线程的中断标志
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
private void interruptIdleWorkers(boolean onlyOne) {
//加锁,同时只有一个线程可以调用shutdown方法设置中断标志
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//遍历所有的worker中的线程,如果线程没有中断然后成功获取worker自己的锁,就中断该线程
//注意,worker实现了AQS,如果worker能够获取自己的锁,说明该线程没有在执行任务,就可以设置中断
//而有的worker中的线程正在执行的任务的线程,则不会中断
for (Worker w : workers) {
Thread t = w.thread;
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
六.shutdownNow方法
这个方法和shutdown的区别就是,前者会中断线程池中所有的线程,不管是正在执行任务的还是空闲的,而且还会把阻塞队列中没来得及执行的任务丢弃;
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//权限检查
checkShutdownAccess();
//将线程池状态设置为STOP
advanceRunState(STOP);
//中断线程池中所有线程
interruptWorkers();
//将阻塞队列中任务都抛弃
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
//中断线程池中所有线程
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//这里直接遍历,所有的worker都调用interruptIfStarted方法,这个方法就在下面
for (Worker w : workers)
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}
void interruptIfStarted() {
Thread t;
//如果Worker的线程不为空,而且该线程不是中断状态,就把该线程中断
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
//将阻塞队列中任务都抛弃,很简单的集合操作
private List<Runnable> drainQueue() {
BlockingQueue<Runnable> q = workQueue;
ArrayList<Runnable> taskList = new ArrayList<Runnable>();
q.drainTo(taskList);
if (!q.isEmpty()) {
for (Runnable r : q.toArray(new Runnable[0])) {
if (q.remove(r))
taskList.add(r);
}
}
return taskList;
}
七.总结
重要的方法就是这几个,其实所谓的线程池就是巧妙的利用了一个Integer类型的原子变量来记录线程池状态和线程池中线程数量,通过线程池状态来控制线程的执行,每个Worker线程可以执行多个任务,其实就是在runWorker中的循环:while (task != null || (task = getTask()) != null) ,在这里不断的轮询拿到当前Worker中的第一个任务或者从任务队列中取到任务,然后会去执行;
简单看看ThreadPoolExecutor原理的更多相关文章
- C#基础--.net平台的重要组成部分以及.net程序简单的编译原理
.net平台的组成只要有两部分 FCL:框架类库 CLR:公共语言运行时 .net程序简单的编译原理 1.0:使用C#编译器(csc.exe) 将C#源代码编译成程序集+{编译之前:会检查C ...
- pureMVC简单示例及其原理讲解五(Facade)
本节将讲述Facade,Proxy.Mediator.Command的统一管家.自定义Facade必须继承Facade,在本示例中自定义Facade名称为ApplicationFacade,这个名称也 ...
- pureMVC简单示例及其原理讲解四(Controller层)
本节将讲述pureMVC示例中的Controller层. Controller层有以下文件组成: AddUserCommand.as DeleteUserCommand.as ModelPrepCom ...
- pureMVC简单示例及其原理讲解三(View层)
本篇说的是View层,即视图层,在本示例中包括两个部分:MXML文件,即可视控件:Mediator. 可视控件 可视控件由UserForm.mxml(图1)和UserList.mxml(图2)两个文件 ...
- Java线程池ThreadPoolExecutor原理和用法
1.ThreadPoolExecutor构造方法 public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAli ...
- 简单分析ThreadPoolExecutor回收工作线程的原理
最近阅读了JDK线程池ThreadPoolExecutor的源码,对线程池执行任务的流程有了大体了解,实际上这个流程也十分通俗易懂,就不再赘述了,别人写的比我好多了. 不过,我倒是对线程池是如何回收工 ...
- Java 线程池(ThreadPoolExecutor)原理分析与使用
在我们的开发中"池"的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 使用线程池的好处 1.降低资源消耗 可以重复利用 ...
- Java 线程池(ThreadPoolExecutor)原理解析
在我们的开发中“池”的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 有关java线程技术文章还可以推荐阅读:<关于java多线程w ...
- Java线程池(ThreadPoolExecutor)原理分析与使用
在我们的开发中"池"的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 使用线程池的好处 1.降低资源消耗 可以重复利用 ...
随机推荐
- OAuth2.0概念以及实现思路简介
一.什么是OAuth? OAuth是一个授权规范,可以使A应用在受限的情况下访问B应用中用户的资源(前提是经过了该用户的授权,而A应用并不需要也无法知道用户在B应用中的账号和密码),资源通常以REST ...
- 关于Log4Net的使用及配置方式
目录 0.简介 1.安装程序包 2.配置文件示例 3.日记的级别:Level 4.日志的输出源:Appenders 5.日志格式:Layout 6.日志文件变换方式(回滚方式):RollingStyl ...
- CentOS6.8 LAMP
第一次配置LAMP运行环境,上网查询了很多资料,一边试命令一边学习.服务器重置了很多次. 虽然有OneinStack这个方便的网站一键命令部署,但知道这个网站却是我自己踩坑之后的事情了,故此记录. 1 ...
- 【LC_Lesson5】---求最长的公共前缀
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- hdfs断电报错解决
一,/home/hadoop/tmp/dfs/name/current 目录下查看文件二,1.stop hadoop所有的服务;2.重新格式化namenode即可: hadoop根目录下: hadoo ...
- Webpack实战(一):Webpack打包工具安装及参数配置
为什么要模块化 javascript跟其他开发语言有很多的区别,其中一个就是没有模块化概念,如果一个项目中有多个js文件,我们只能通过script标签引入的方式,把一个个js文件插入到页面,这种做法会 ...
- spring boot 集成apollo 快速指南
目前市面上流行的三大配置中心框架:Spring CLoud Config .Alibaba Nacos 以及携程apollo, 我们相应架构组号召,就使用Apollo吧. Work Flow 简单解释 ...
- Vue 组件复用性和slot
1.组件可复用 2.slot元素作为组件模板之中的内容分发插槽,元素自身可以被替换 <!DOCTYPE html> <html lang="en"> < ...
- 软件工程概论 网站开发要掌握的技术 &登录界面
1.网站系统开发需要掌握的技术 一.界面和用户体验(Interface and User Experience) 1.1 知道如何在基本不影响用户使用的情况下升级网站.通常来说,你必须有版本控制系统( ...
- 第二次团队作业-需求分析(By七个小矮人)
第二次团队作业-需求分析 一.格式描述 这个作业属于哪个课程 https://edu.cnblogs.com/campus/xnsy/GeographicInformationScience/ 这个作 ...