Scrapy 框架(二)数据的持久化
scrapy数据的持久化(将数据保存到数据库)
一、建立项目
1、scrapy startproject dushu
2、进入项目
cd dushu
执行:scrapy genspider -t crawl read www.dushu.com
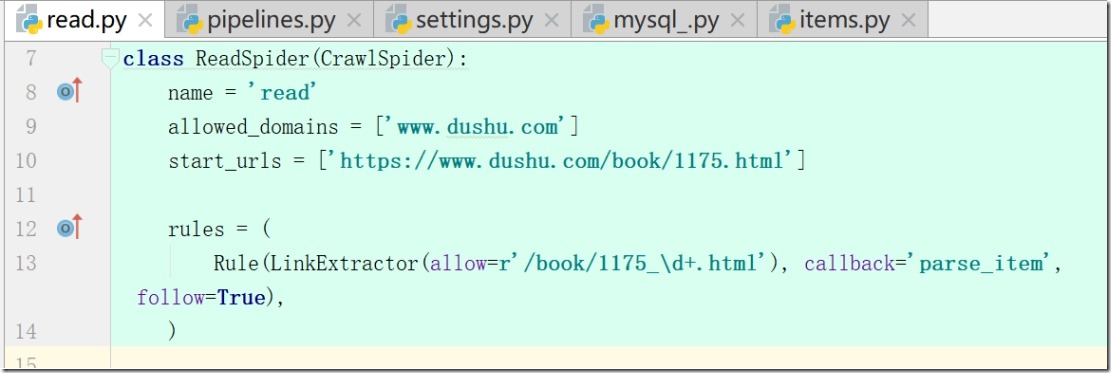
查看:read.py
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1175.html']

注:项目更改了默认模板,使其具有递归性
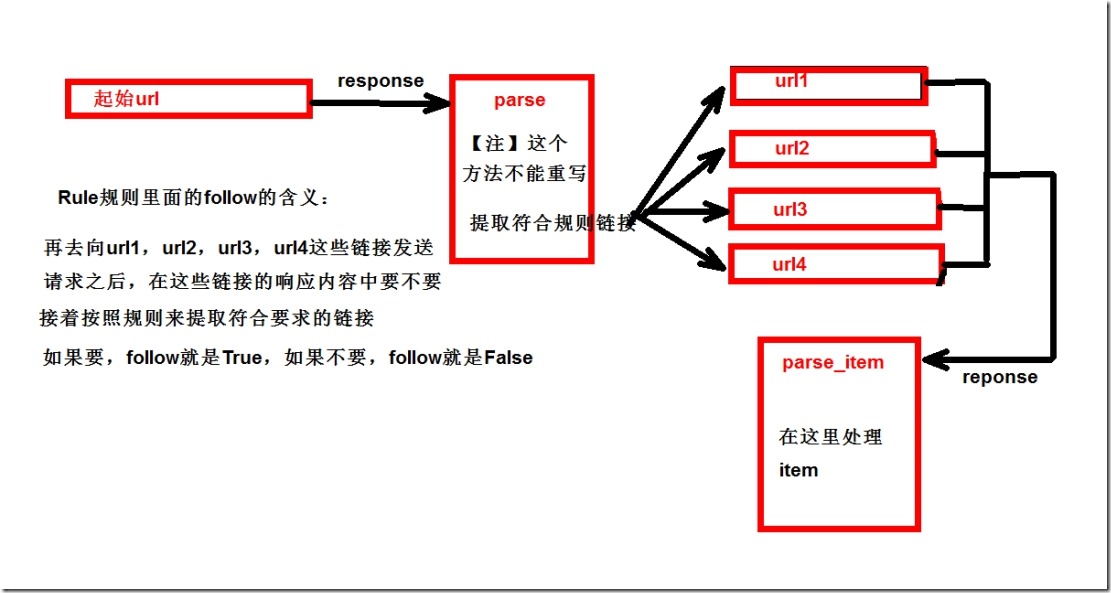
3、模板CrawlSpider具有以下优点:
1)继承自scrapy.Spider;
2)CrawlSpider可以定义规则
在解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求;
所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的;
3)模拟使用:
a: 正则用法:links1 = LinkExtractor(allow=r'list_23_\d+\.html')
b: xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
c:css用法:links3 = LinkExtractor(restrict_css='.x')
4、更改模板后rules参数解释:
a:参数一 (allow=r'/book/1175_\d+.html') 匹配规则;
b: 参数二 callback='parse_item' ,数据回来之后调用多方法
c: 参数三,True,从新的页面中继续提取链接
注:False,当前页面中提取链接,当前页面start_urls
5、 修改start_urls
start_urls = ['https://www.dushu.com/book/1175.html']
写 def parse_item(self, response)
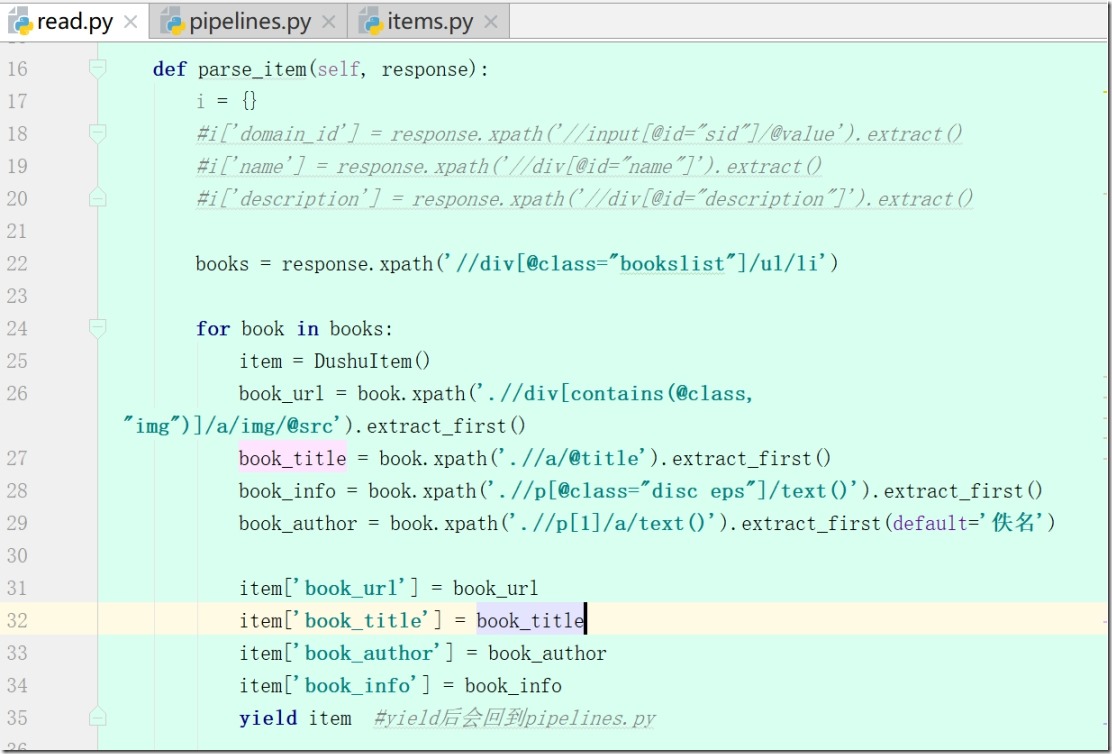
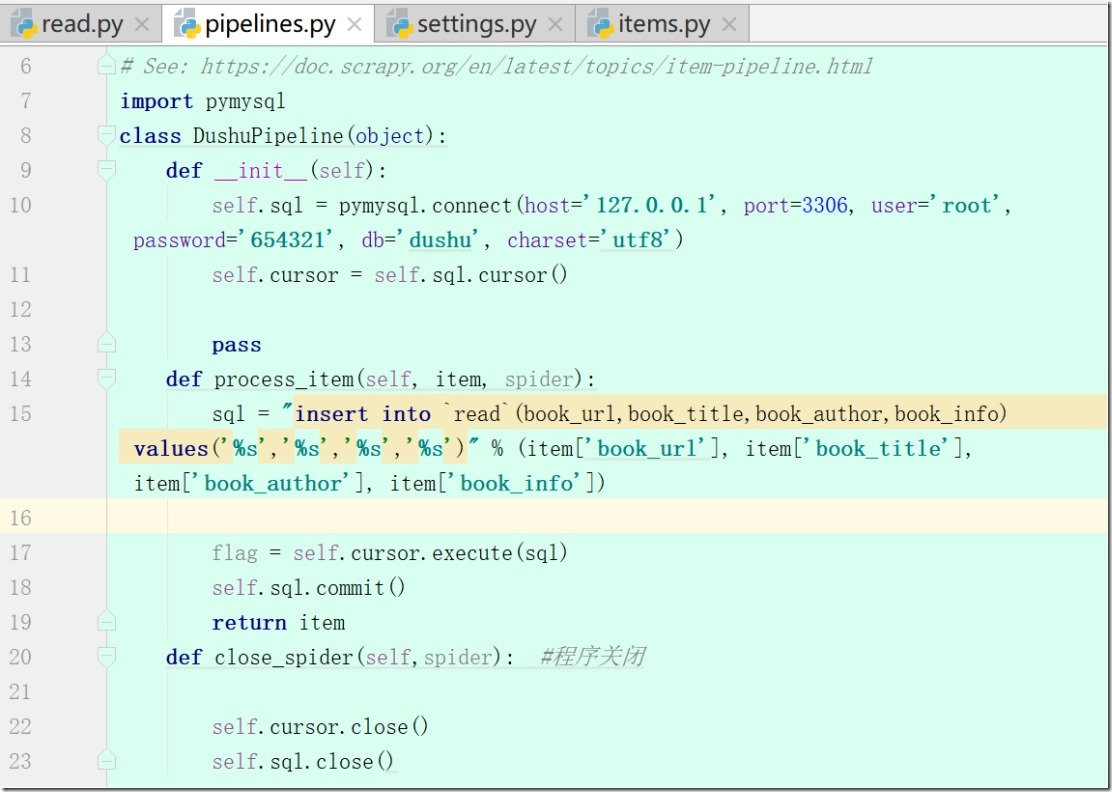
6、items.py
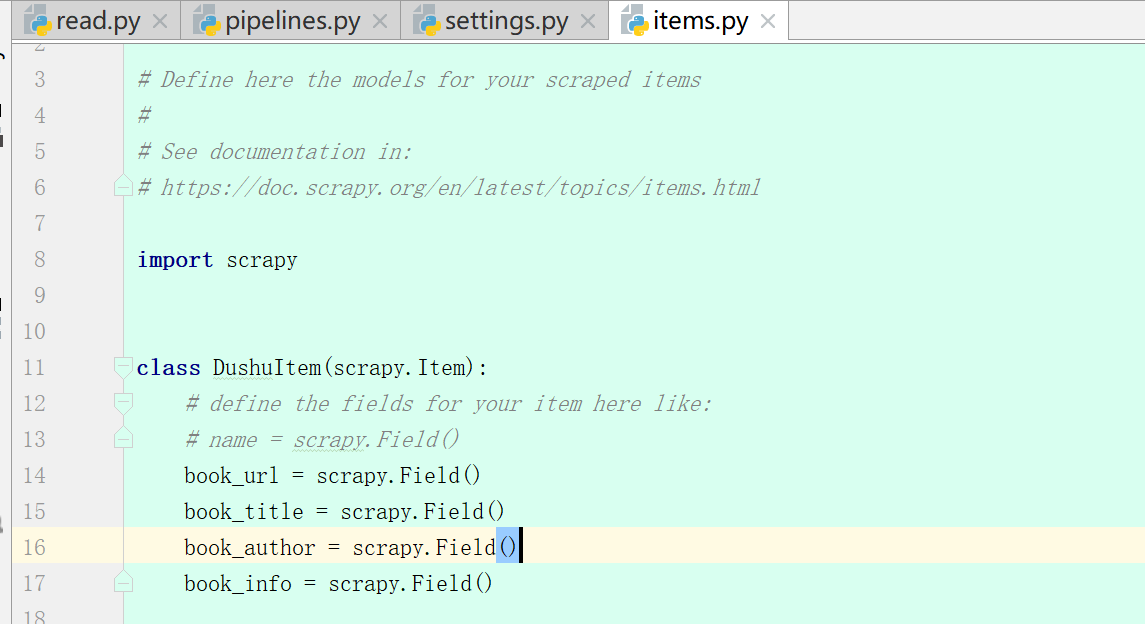
7、pipelines.py(yield后会回到pipelines.py)
1)写def __init__(self): 和 def close_spider(self,spider):
2)连接mysql,保存数据
3)启动mysql (Navicat)
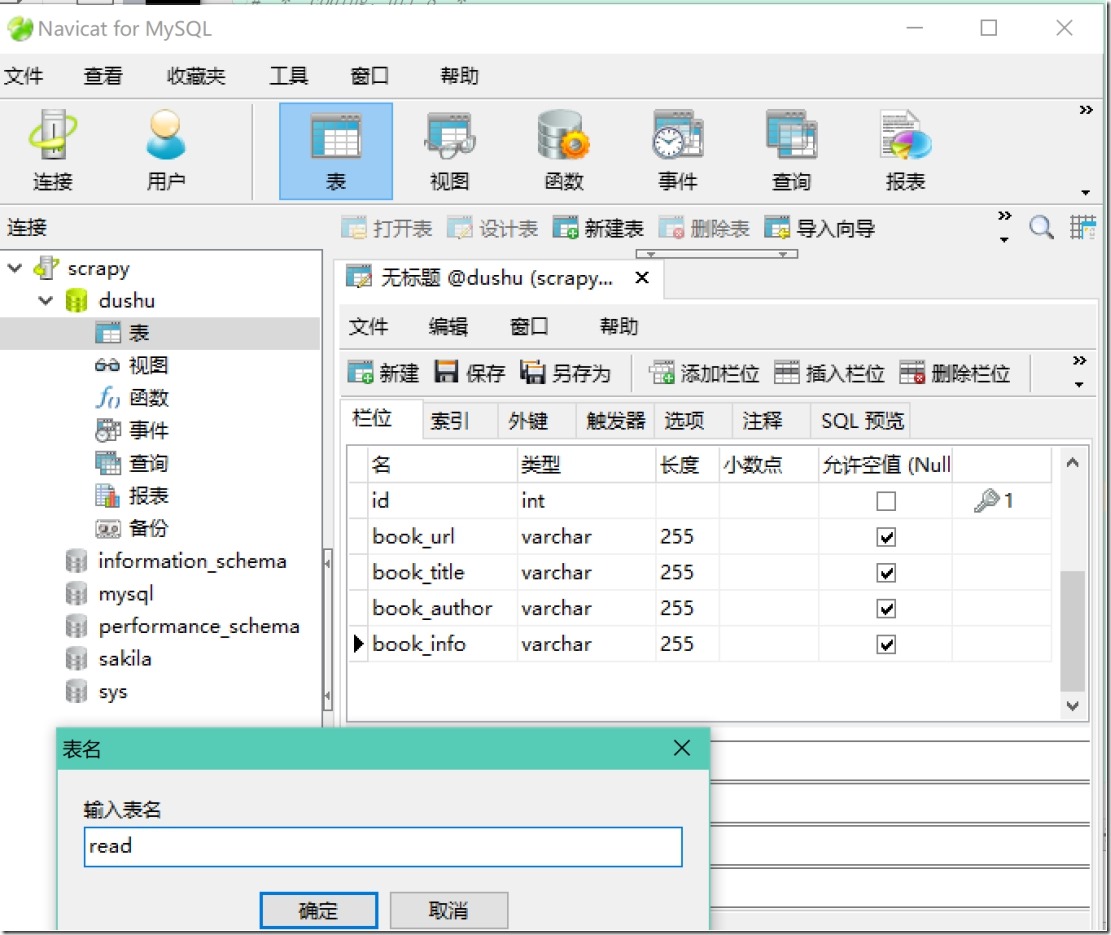
4) 连接数据库def process_item(self, item, spider)
5)setting(robots、USER_AGENT、ITEM_PIPELINES)
6)read.py(修改rules)
8、执行scrapy crawl read,将数据写入数据库
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加QQ群:483766429 或联系作者本人 QQ :87605025
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事说三遍。。。。。。


Scrapy 框架(二)数据的持久化的更多相关文章
- 爬虫(十五):Scrapy框架(二) Selector、Spider、Downloader Middleware
1. Scrapy框架 1.1 Selector的用法 我们之前介绍了利用Beautiful Soup.正则表达式来提取网页数据,这确实非常方便.而Scrapy还提供了自己的数据提取方法,即Selec ...
- scrapy框架基于管道的持久化存储
scrapy框架的使用 基于管道的持久化存储的编码流程 在爬虫文件中数据解析 将解析到的数据封装到一个叫做Item类型的对象 将item类型的对象提交给管道 管道负责调用process_item的方法 ...
- Python项目--Scrapy框架(二)
本文主要是利用scrapy框架爬取果壳问答中热门问答, 精彩问答的相关信息 环境 win8, python3.7, pycharm 正文 1. 创建scrapy项目文件 在cmd命令行中任意目录下执行 ...
- (六--二)scrapy框架之持久化操作
scrapy框架之持久化操作 基于终端指令的持久化存储 基于管道的持久化存储 1 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过 ...
- scrapy框架的持久化存储
一 . 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存 ...
- scrapy框架基于CrawlSpider的全站数据爬取
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- scrapy框架的另一种分页处理以及mongodb的持久化储存以及from_crawler类方法的使用
一.scrapy框架处理 1.分页处理 以爬取亚马逊为例 爬虫文件.py # -*- coding: utf-8 -*- import scrapy from Amazon.items import ...
- 10 Scrapy框架持久化存储
一.基于终端指令的持久化存储 保证parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存储:将爬取到的 ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
随机推荐
- SpringMVC+Spring+MyBatis 整合与图片上传简单示例
一.思路: (一) Dao层: 1. SqlMapConfig.xml,空文件即可.需要文件头.2. applicationContext_dao.xml. a) 数据库连接池b) SqlSessio ...
- DRF序列化
1. 安装 pip install djangoframework 2. app注册 rest_framework INSTALLED_APPS = [ 'django.contrib.admin', ...
- Linux打包、压缩与解压详解
介绍:在Windows下最常见的压缩文件就只有两种,另一个是.rar,它有.gz..tar.gz.tgz.bz2..Z..tar等众多的压缩文件名,本文就来对这些常见的压缩文件进行总结,在具体总结各类 ...
- Jaguar_websocket结合Flutter搭建简单聊天室
1.定义消息 在开始建立webSocket之前,我们需要定义消息,如:发送人,发送时间,发送人id等.. import 'dart:convert'; class ChatMessageData { ...
- webpack中配置Babel
Babel是一个javascript编译器,可以将ES6和更新的js语法转换成ES5的,使代码在较老的浏览器里也能正常运行. 一.安装 npm install --save-dev babel-loa ...
- Android手机上,利用bat脚本模拟用户操作
………… 那么你就可以来看看这篇帖子了. 言归正传 利用bat脚本模拟用户操作,需要用到两点: ①就是adb命令了,adb命令可以用来模拟用户在手机上的操作 ②bat语言,就是批处理语言,主要用来进行 ...
- 反射式DLL注入--方法
使用RWX权限打开目标进程,并为该DLL分配足够大的内存. 将DLL复制到分配的内存空间. 计算DLL中用于执行反射加载的导出的内存偏移量. 调用CreateRemoteThread(或类似的未公开的 ...
- Oracle EBS OM 登记订单
DECLARE l_header_rec OE_ORDER_PUB.Header_Rec_Type; l_line_tbl OE_ORDER_PUB.Line_Tbl_Type; l_action_r ...
- 缓存那些事-zz
https://tech.meituan.com/cache_about.html 前言 一般而言,现在互联网应用(网站或App)的整体流程,可以概括如图1所示,用户请求从界面(浏览器或App界面)到 ...
- pt-osc原理、限制、及与原生online-ddl比较
1. pt-osc工作过程 创建一个和要执行 alter 操作的表一样的新的空表结构(是alter之前的结构) 在新表执行alter table 语句(速度应该很快) 在原表中创建触发器3个触发器分别 ...