logstash 切分tomcat日志
以下配置是logstash切分tomcat catalina.out日志。
http://grok.qiexun.net/ 分割时先用这个网站测试下语句对不对,能不能按需切割日志。
input {
file {
type => "01-catalina"
path => ["/usr/local/tomcat-1/logs/catalina.out"]
start_position => "beginning"
ignore_older =>
codec=> multiline {
pattern => "^2018"
negate => true
what => "previous"
}
}
file {
type => "02-catalina"
path => ["/usr/local/tomcat-2/logs/catalina.out"]
start_position => "beginning"
ignore_older =>
codec=> multiline {
pattern => "^2018"
negate => true
what => "previous"
}
}
}
filter {
grok {
match => {
"message" => "%{DATESTAMP:date} \|-%{LOGLEVEL:level} \[%{DATA:class}\] %{DATA:code_info} -\| %{GREEDYDATA:log_info}"
}
}
}
output {
elasticsearch {
hosts => ["192.168.1.1:9200"]
index => "tomcat-%{type}"
}
stdout {
codec => rubydebug
}
}
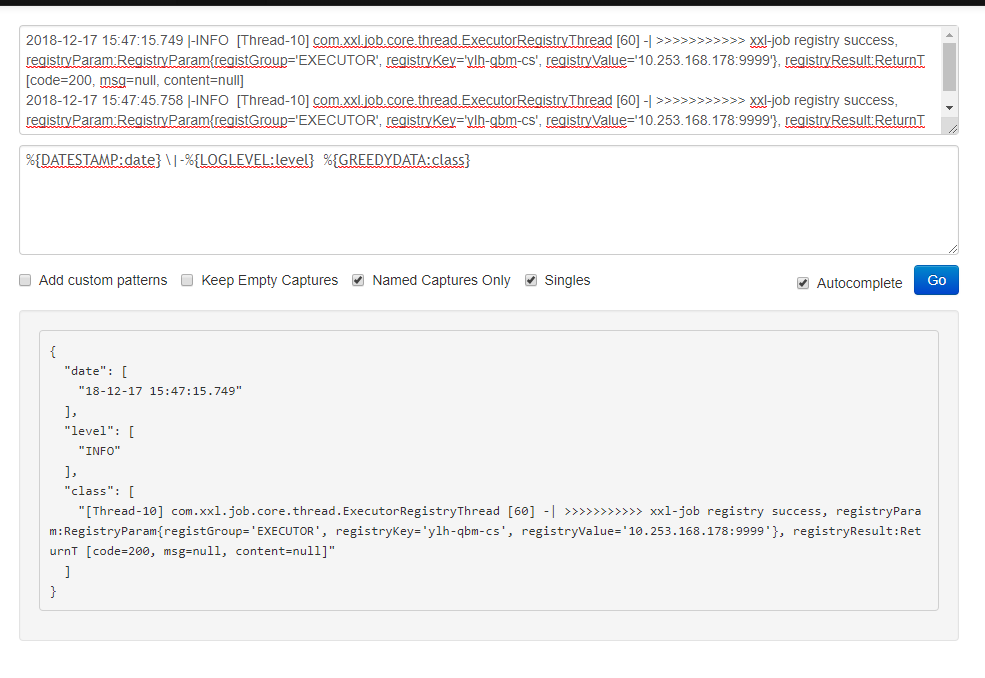
跨行匹配 比如java 堆栈信息
input {
file {
type => "10.139.32.68"
path => ["/data1/application/api/apache-tomcat/logs/catalina.out"]
start_position => "beginning"
ignore_older =>
codec=> multiline {
pattern => "^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}"
negate => true
what => "previous"
}
}
codec=> multiline 引用 multiline插件
pattern 正则匹配 ^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2} 表示以 2018-10-10 10:10:10 日期形式开通的negate what 值为previous 表示未匹配的内容属于上一个匹配内容
自定义正则表达式
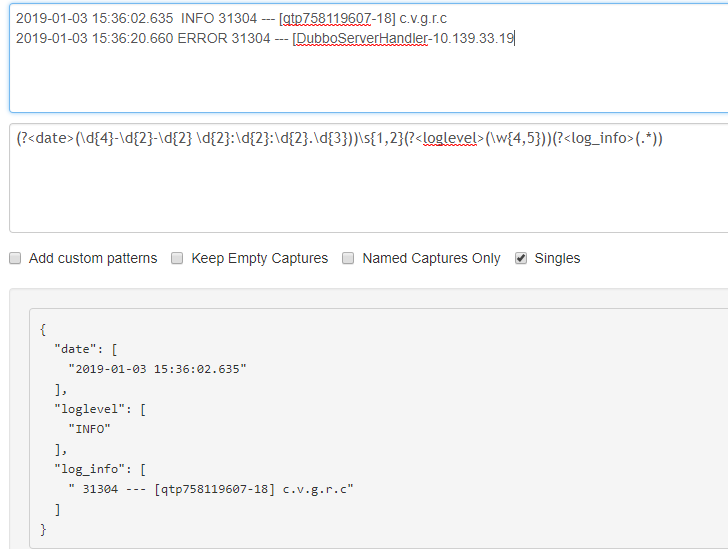
其中(?<>())格式表示一个正则开始,<>里是正则匹配名,()里是正则表达式
上图正则分四段,分别是
(?<date>(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d{3})) 匹配日期
\s{1,2} 匹配1或2个空格
(?<loglevel>(\w{4,5})) 匹配4或5个字母
(?<log_info>(.*)) 匹配所有字符
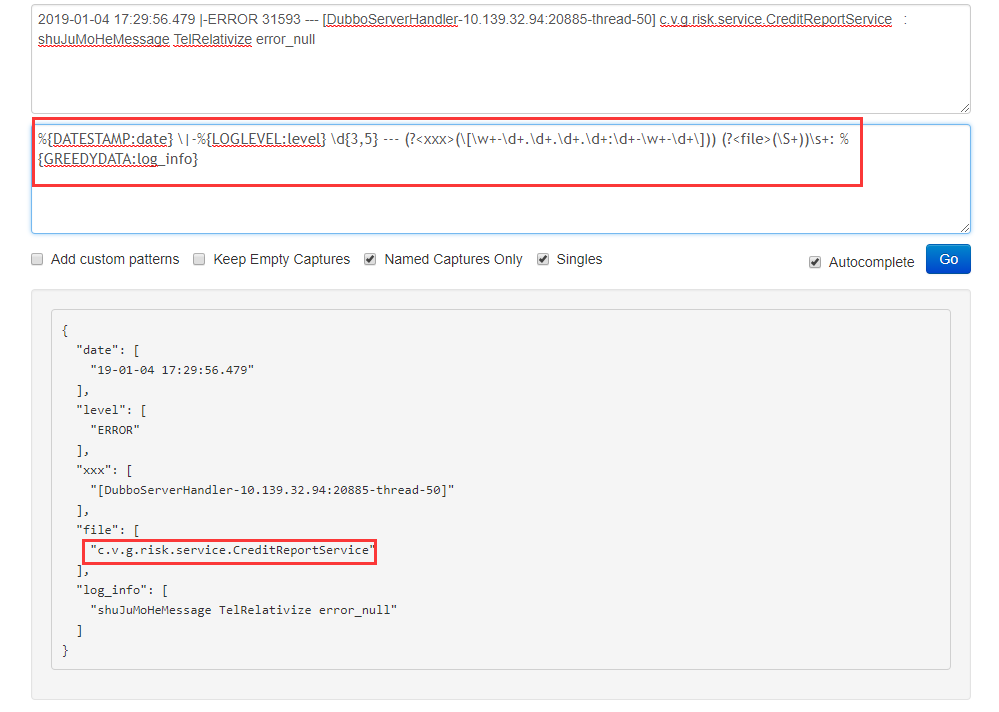
又如下面这个
2019-01-04 17:29:56.479 |-ERROR 31593 --- [DubboServerHandler-10.139.32.94:20885-thread-50] c.v.g.risk.service.CreditReportService : shuJuMoHeMessage TelRelativize error_null
%{DATESTAMP:date} \|-%{LOGLEVEL:level} \d{3,5} --- (?<xxx>(\[\w+-\d+.\d+.\d+.\d+:\d+-\w+-\d+\])) (?<file>(\S+))\s+: %{GREEDYDATA:log_info}
logstash 启动多个配置文件
logstash 启动多个配置文件,比如conf目录下有cs.conf和server.conf就可以用下面命令启动./logstash -f ../conf/ 记住conf后面不能加上* 如./logstash -f ../conf/* ,这样只会读取conf目录下的一个配置文件。
另外虽然可以同时启动多个配置文件,但实际上是把多个配置文件拼接成一个的配置文件的,也就是多个配置文件里的input、filter、output不是相互独立的。如有俩个配置文件cs.conf和server.conf 配置如下:
cs.conf配置: 1 input {
file {
type => "192.168.1.1"
path => ["/data1/application/cs/tomcat-1/logs/catalina.out"]
start_position => "beginning"
ignore_older =>
codec=> multiline {
pattern => "^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}"
negate => true
what => "previous"
}
}
}
filter {
grok { remove_tag => ["multiline"] #打印多行时有时会无法解析,因为tags里会多出一个multiline ,进而报错,报错信息如文末备注1
match => hosts => [ index => codec => }
server.conf配置 1 input {
file {
type => "192.168.1.1"
path => ["/data1/application/server/tomcat-2/logs/catalina.out"]
start_position => "beginning"
ignore_older =>
codec=> multiline {
pattern => "^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}"
negate => true
what => "previous"
}
}
}
filter {
grok {
match => {
"message" => "%{DATESTAMP:date} \|-%{LOGLEVEL:level} %{GREEDYDATA:log_info}"
}
}
}
output {
elasticsearch {
hosts => ["192.168.0.1:9200"]
index => "qwe-server-tomcat"
}
stdout {
codec => rubydebug
}
}
上面俩个配置就算同时启动,但实际上俩个配置文件会拼接成一个,input里的内容会输出俩个,导致elk里数据看起来是重复的,打印了俩次
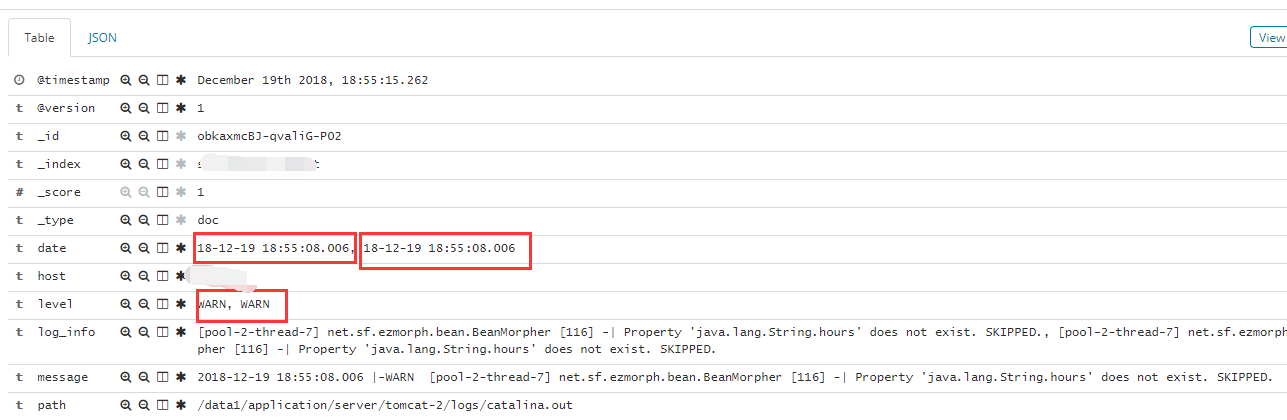
一般这种情况建议,input里建议使用tags或者type这两个特殊字段,即在读取文件的时候,添加标识符在tags中或者定义type变量。如下面这种
input {
file {
type => "192.168.1.1"
tags =>"cs"
path => ["/data1/application/cs/tomcat-1/logs/catalina.out"]
start_position => "beginning"
ignore_older =>
codec=> multiline {
pattern => "^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}"
negate => true
what => "previous"
}
}
file {
type => "192.168.1.1"
tags =>"server"
path => ["/data1/application/server/tomcat-2/logs/catalina.out"]
start_position => "beginning"
ignore_older =>
codec=> multiline {
pattern => "^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}"
negate => true
what => "previous"
}
}
}
filter {
grok { remove_tag =>["multiline"]
match => {
"message" => "%{DATESTAMP:date} \|-%{LOGLEVEL:level} %{GREEDYDATA:log_info}"
}
}
}
output {
elasticsearch {
hosts => ["192.168.0.1:9200"]
index => "ulh-%{tags}-tomcat"
}
stdout {
codec => rubydebug
}
}
这样我们就可以根据tpye和tags分别日志是哪台服务器上的哪个应用了
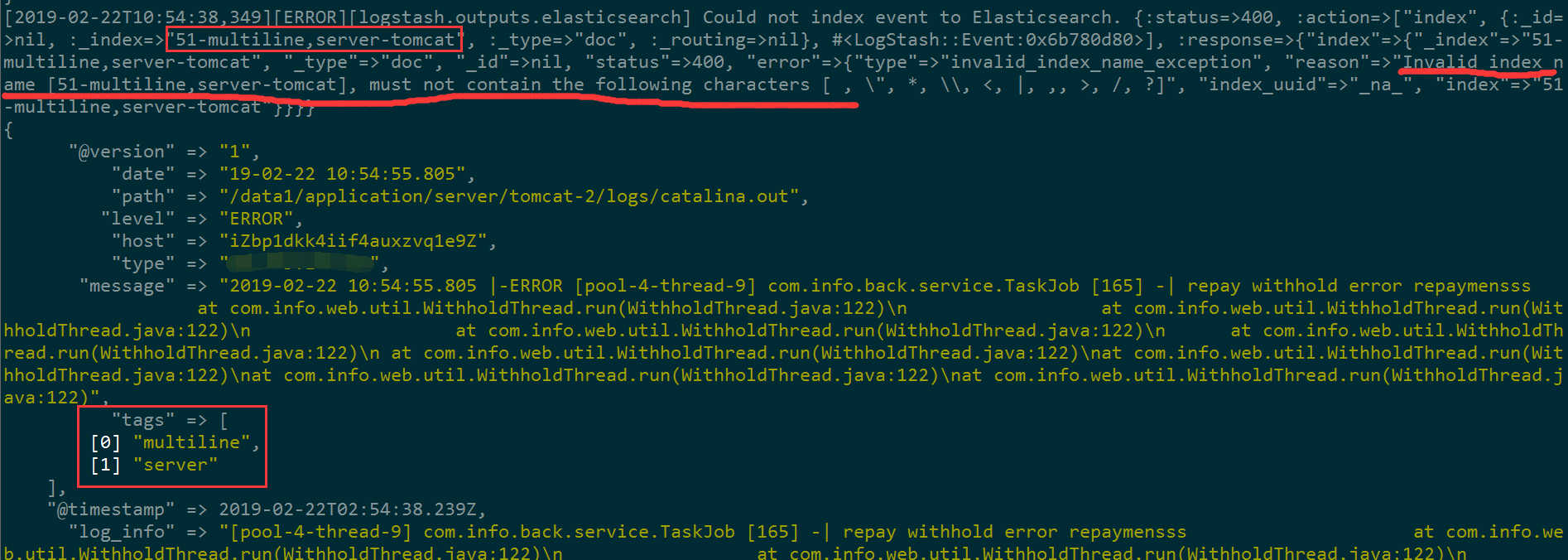
注1:跨行解析时因为多个tags导致无法解析异常的截图,解决方法就是在 filter grok里添加 remove_tag =>["multiline"]
注2:logstash中multiline更多用法
input {
stdin {
codec =>multiline {
charset=>... #可选 字符编码
max_bytes=>... #可选 bytes类型 设置最大的字节数
max_lines=>... #可选 number类型 设置最大的行数,默认是500行
multiline_tag... #可选 string类型 设置一个事件标签,默认是multiline
pattern=>... #必选 string类型 设置匹配的正则表达式
patterns_dir=>... #可选 array类型 可以设置多个正则表达式
negate=>... #可选 boolean类型 设置true是向前匹配,设置false向后匹配,默认是FALSE
what=>... #必选 设置未匹配的内容是向前合并还是先后合并,previous,next两个值选择
}
}
}
logstash 切分tomcat日志的更多相关文章
- logstash采集tomcat日志、mysql错误日志
input{ file { path => "/opt/Tomcat7.0.28/logs/*.txt" start_position => "beginni ...
- 构建Logstash+tomcat镜像(让logstash收集tomcat日志)
1.首先pull logstash镜像作为父镜像(logstash的Dockerfile在最下面): 2.构建my-logstash镜像,使其在docker镜像实例化时,可以使用自定义的logstas ...
- logstash 处理tomcat日志
[root@dr-mysql01 tomcat]# cat logstash_tomcat.conf input { file { type => "zj_api" path ...
- logstash配合filebeat监控tomcat日志
环境:logstash版本:5.0.1&&filebeat 5.0.1 ABC为三台服务器.保证彼此tcp能够相互连接. Index服务器A - 接收BC两台服务器的tomcat日志 ...
- ELK对Tomcat日志双管齐下-告警触发/Kibana日志展示
今天我们来聊一聊Tomcat,相信大家并不陌生,tomcat是一个免费开源的web应用服务器,属于轻量级的应用程序,在小型生产环境和并发不是很高的场景下被普遍使用,同时也是开发测试JSP程序的首选.也 ...
- ELK收集Nginx|Tomcat日志
1.Nginx 日志收集,先安装Nginx cd /usr/local/logstash/config/etc/,创建如下配置文件,代码如下 Nginx.conf input { file { typ ...
- tomcat日志采集
1. 采集tomcat确实比之前的需求复杂很多,我在搭建了一个tomcat的环境,然后产生如下报错先贴出来: Jan 05, 2017 10:53:35 AM org.apache.catalina. ...
- 4:ELK分析tomcat日志
五.ELK分析tomcat日志 1.配置FIlebeat搜集tomcat日志 2.配置Logstash从filebeat输入tomcat日志 3.查看索引 4.创建索引
- log4j托管tomcat日志
由于项目中 Tomcat 日志越来越大,对于日志查找非常不方便,所以经过一番调查可以通过log4j来托管 Tomcat 日志的方式,实现Tomcat日志切片.这里只说明怎么是log4j托管Tomcat ...
随机推荐
- Vector Math for 3D Computer Graphics (Bradley Kjell 著)
https://chortle.ccsu.edu/VectorLessons/index.html Chapter0 Points and Lines (已看) Chapter1 Vectors, P ...
- HBASE 优化之REGIONSERVER
HBASE 优化之REGIONSERVER 一,概述 本人在使用优化regionserver的过程有些心得,借此随笔的机会,向大家介绍我的心得,有些是网上拿来的有些是自己在使用过程自己的经验,希望对大 ...
- char* 与 string 互转
因为c#强调安全性,每次意图将string的地址赋给指针时,系统都要报错,原因是系统无法计算字符串的空间和地址,这里不多bb,使用IntPtr类(using Runtime.InteropServic ...
- .net core2.0获取host的方法
Example there's an given url: http://localhost:4800/account/login 获取整个url地址: 在页面(cstml)中 Microsoft.A ...
- win10 caffe GPU环境搭建
一.准备 系统:win10 显卡:gtx1050Ti 前期的一些必要软件安装,包括python3.5.matlab2016.vs2015.git, 可参考:win10+vs2015编译caffe的cp ...
- webpack打包vue -->简易讲解
### 1. 测试环境: 推荐这篇文章:讲的很细致 https://www.cnblogs.com/lhweb15/p/5660609.html 1. webpack.config.js自行安装 { ...
- ubuntu中连接mssql数据库sqlserver
参考文章 https://blog.csdn.net/fangaoxin/article/details/5386149 (感谢作者) sudo apt-get install tdsodbc sud ...
- Java Web开发Session超时设置
在Java Web开发中,Session为我们提供了很多方便,Session是由浏览器和服务器之间维护的.Session超时理解为:浏览器和服务器之间创建了一个Session,由于客户端长时间(休眠时 ...
- Win32-Application的窗口和对话框
Win32 Application,没有基于MFC的类库,而是直接调用C++接口来编程. 一.弹出消息窗口 (1)最简单的,在当前窗口中弹出新窗口.新窗口只有“YES”按钮. int APIENTRY ...
- 工控随笔_09_西门子_S7-200 Smart与V20 USS通信USS_RPM_R利用轮询的方式通讯异常
前两天处理过一个故障,是S7-200 Smart与V20的USS通讯,设备厂家在程序里面利 用USS_RPM _R程序循环轮询5个V20设备读取频率和电流值等信息. 图 USS_RPM_R读取信息 上 ...