一起学Hadoop——Hadoop的前世今生
Hadoop是什么?
Hadoop是一个处理海量数据的开源框架。2002年Nutch项目面世,这是一个爬取网页工具和搜索引擎系统,和其他众多的工具一样,都遇到了在处理海量数据时效率低下,无法存储爬取网页和搜索网页时产生的海量数据的问题。2003年谷歌发布了一篇论文,专门介绍他们的分布式文件存储系统GFS。鉴于GFS在存储超大文件方面的优势,Nutch按照GFS的思想在2004年实现了Nutch的开源分布式文件系统,即NDFS。2004年谷歌发布了另一篇论文,专门介绍他们处理大数据的计算框架MapReduce,2005年初Nutch开发人员在Nutch上实现了开源的MapReduce,这就是Hadoop的雏形。2006年Nutch将NDFS和MapReduce迁出Nutch,并命名为Hadoop,同时雅虎公司专门为Hadoop建立一个团队,将其发展成为能够处理海量数据的Web框架,2008年Hadoop成为Apache的顶级项目。
2007年9月发布hadoop 0.14.1,第一个稳定版本。
2009年4月发布hadoop 0.20.0版本。
2011年12月发布hadoop 1.0.0版本,这是经过将近6年的酝酿后发布的一个版本,该版本基于0.20安全代码线,增加如下的功能:
安全,
Hbase(append/hsynch/hflush和security)
webhdfs(完全支持安全)
增加HBase访问本地文件系统的性能
2.12年5月发布hadoop 2.0.0-alpha,则是hadoop-2.X系列的第一个版本,增加很多重要的特性:
1、NameNode HA(High Availability高可靠性),当主NameNode挂掉时,备用NameNode可以快速启动,成为主NameNode节点,向外提供服务。
2、HDFS Federation。
3、YARN aka NextGen MapReduce。
2017年9月份发布Hadoop 3.0.0 generally版本,这是hadoop 3.x系列的第一个版本。
目前市面上还是以Hadoop2.x系列为主,Hadoop3.x还没正式的运用到生产系统中。
一句话总结:Hadoop是开源的大数据处理框架,分为处理数据的MapReduce和存储数据的HDFS。
Hadoop能做什么?
Hadoop可以用来处理海量数据,对数据进行分析。现在互联网企业每天都产生大量的日志数据,有的甚至达到PB级别,像国外的facebook,twitter,国内的阿里、腾讯、京东、百度等企业。在Haddop没出现之前,都是用小型机处理数据,价格昂贵不说,还耗费时间,Hadoop面世之后,可以使用廉价机器搭建Hadoop集群,一台小型机的价格就可以搭建起一个20个节点的Hadoop集群。2007年雅虎在900个节点的hadoop集群上对1T的数据进行排序只需要209秒,引起业界的关注,从此Haddoop逐渐成为大数据处理的标准,众多厂商纷纷向其靠拢。目前国内的互联网企业对Hadoop的使用都比较成熟,在2015年的时候百度的Hadoop集群就达到4000个节点。
Hadoop的缺点
Hadoop适合处理海量的离线数据,对于处理实时数据却不合适,例如实时股票交易分析。实时海量数据处理目前有比较好的框架,分别是Spark Streaming,Storm,Flink。他们也都是基于Hadoop的基础上实现的,数据Hadoop生态系统中的一员。
Hadoop生态框架
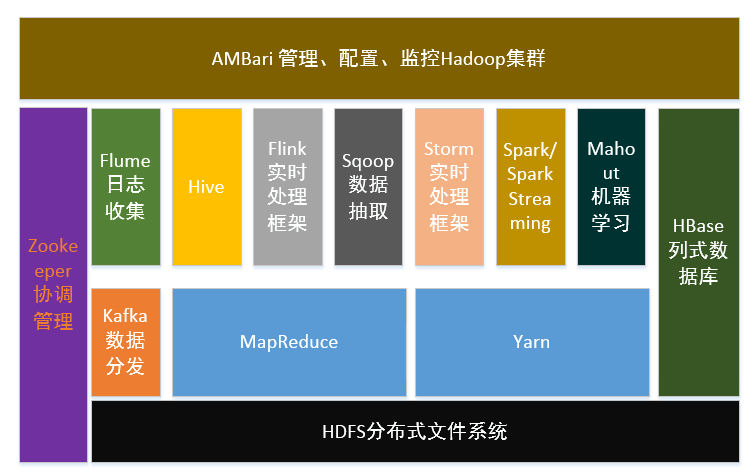
现在我们讲Hadoop,泛指Hadoop生态系统中的各种组件,包括用于构架数据仓库和分析数据的Hive,基于HDFS的列式数据库HBase,实时数据处理框架Flink、Storm、Spark Streaming等。下图是Hadoop的生态系统图。
一起学Hadoop——Hadoop的前世今生的更多相关文章
- [Hadoop]Hadoop章2 HDFS原理及读写过程
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统. HDFS有很多特点: ① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份. ② ...
- hadoop hadoop install (1)
vmuser@vmuser-VirtualBox:~$ sudo useradd -m hadoop -s /bin/bash[sudo] vmuser 的密码: vmuser@vmuser-Virt ...
- Hadoop hadoop 机架感知配置
机架感知脚本 使用python3编写机架感知脚本,报存到topology.py,给予执行权限 import sys import os DEFAULT_RACK="/default-rack ...
- EDW on Hadoop(Hadoop上的数据仓库)技术选型和实践思考
在这篇文章中, 将讨论EDW on Hadoop 有哪些备选方案, 以及我个人的倾向性, 最后是建构方法. 欢迎转载, 但必须注明原贴(刘忠武, http://www.cnblogs.com/ha ...
- [Hadoop] Hadoop学习历程 [持续更新中…]
1. Hadoop FS Shell Hadoop之所以可以实现分布式计算,主要的原因之一是因为其背后的分布式文件系统(HDFS).所以,对于Hadoop的文件操作需要有一套全新的shell指令来完成 ...
- [Hadoop] Hadoop学习笔记之Hadoop基础
1 Hadoop是什么? Google公司发表了两篇论文:一篇论文是“The Google File System”,介绍如何实现分布式地存储海量数据:另一篇论文是“Mapreduce:Simplif ...
- [hadoop] hadoop “util.NativeCodeLoader: Unable to load native-hadoop library for your platform”
执行 bin/hdfs dfs -mkdir /user,创建目录时出现警告信息. WARN util.NativeCodeLoader: Unable to load native-hadoop l ...
- java.io.FileNotFoundException: /home/hadoop/hadoop/dfs/namenode/current/VERSION (Permission denied)
今天布置hadoop集群,尝试单独将secondarynamenode分属到一台独立的虚拟机上, 当格式化后,start-dfs.sh.namenode没启动.查看日志.报错例如以下 查看权限才发现, ...
- [Hadoop] - Hadoop Mapreduce Error: GC overhead limit exceeded
在运行mapreduce的时候,出现Error: GC overhead limit exceeded,查看log日志,发现异常信息为 2015-12-11 11:48:44,716 FATAL [m ...
随机推荐
- Gitbook
2017年9月13日 17:12:20 星期三 gitbook 可以将markdown格式的文件编译成html格式 放在当前目录里的_book目录里(需要手动创建, 也可以指定编译后的html文件放到 ...
- Python2018-字符串中字符个数统计
1 编写程序,完成以下要求: 统计字符串中,各个字符的个数 比如:"hello world" 字符串统计的结果为: h:1 e:1 l:3 o:2 d:1 r:1 w:1 prin ...
- UniversalImageLoader(异步加载大量图片)
UniversalImageLoader是用于加载图片的一个开源项目,UniversalImageLoader是实现异步加载大量图片的源码和例子,包括缓存.硬盘缓存.容错机制等技术.在其项目介绍中是这 ...
- HDU 1077
题意 : 给你 N 个点, 问一个单位圆最大能包括几个点 直接暴力枚举圆心, 计算个数 O(n^ 3): 精度,细节都要注意, //#include<bit/stdc++.h> ...
- java后台发送请求并获取返回值(续)
在java后端发送请求给另一个平台,从而给前端实现 "透传"的过程中,出现:数据请求到了并传到了前端,但是控制台打印时中文显示Unicode码而前端界面中中文显示不出来!!!开始怀 ...
- mysql报ERROR:Deadlock found when trying to get lock; try restarting transaction(nodejs)
1 前言 出现错误 Deadlock found when trying to get lock; try restarting transaction.然后通过网上查找资料,重要看到有用信息了. 错 ...
- 基于官方mysql镜像构建自己的mysql镜像
参考文章:https://www.jb51.net/article/115422.htm搭建步骤 1.首先创建Dckerfile: 1 2 3 4 5 6 7 8 9 10 11 12 FROM my ...
- Sql语句分页,有待优化
封装成存储过程,但是有点小问题,如果有弄好了的朋友可留言,谢谢了,我只提供了一个模版哈(也是我想实现的功能) create procedure paging_procedure ( @pageInde ...
- Golang服务器热重启、热升级、热更新(safe and graceful hot-restart/reload http server)详解
服务端代码经常需要升级,对于线上系统的升级常用的做法是,通过前端的负载均衡(如nginx)来保证升级时至少有一个服务可用,依次(灰度)升级. 而另一种更方便的方法是在应用上做热重启,直接更新源码.配置 ...
- nginx记录post body/payload数据
1. 文档 在nginx中想利用$request_body命令获取post请求的body参数,并落日志,但是发现该变量值为空,查看官网中对$request_body的描述如下: $request_bo ...