Hadoop基础知识串烧

YARN资源调度:
三种
FIFO
大任务独占 一堆小任务独占
capacity 弹性分配 :计算任务较少时候可以利用全部的计算资源,当队列的任务多的时候会按照比例进行资源平衡。
容量保证:保证队列可以获取到资源利用。
安全:ACL访问控制限制 用户只能向自己的队列提交任务。
Fair
Yarn资源调度模型:
当向yarn提交任务之后,ResourceManager会启动NodeManager。
NodeManager会启动APPManager。
APPManager向ResourceManager申请资源,目的领取用于任务计算的container。(心跳发送请求)
(第一层资源调度)ResourceManager作为响应会把container发送给 APPManager ( 但是这个过程不是push那么简单,而是container被放到一个缓存池,下次AM心跳的时候会将资源pull走)
(第二层资源调度)AppManager拿到container之后会分配给task
资源抢占:正常合理的抢占,是由于某个小队列存在空闲资源,会被调度器临时分配给负载较重的队列,但是如果那个小队列突然需要资源进行处理任务,会向那个大队列收回资源,要求物归原主,但是这部分资源还在使用中,此时小队列会等待一段时间,稍后资源如果还没释放,那么小队列就会抢占那部分资源。非常合理。
关于Hive的了解:
基本架构
用户接口,可以直接操作的接口。CLI(命令行界面)JDBC/ODBC(java访问hive)WEBUI(浏览器访问Hive)
元数据:表所属的数据库,表名,表的字段,表的拥有者等等
Hadoop 使用HDFS进行数据存储,使用MapReduce进行计算。(可以使用tez)进行计算,测试环境下比MapReduce查询效果较好。但是相比于HBase。那接着下文……
对比一下HBase和Hive
HBase的构建是用于海量数据的查询,是一种NoSQL数据库,在存储结构的设计上便是优于查询。Hive用于设计数据仓库,使用类SQL的操作方式来存储结构化数据,主要目的是用于存储,以及离线的批量数据计算。Hive会将SQL翻译成对应的MR任务提交给Yarn进行计算。在实际的生产环境中,可以把HBase和Hive看作是协作关系。(参考知乎https://www.zhihu.com/question/21677041)通过ETL(extract-transform-load)的方式将数据存在HDFS中,Hive对数据进行清洗处理计算。可以将最终的数据存入HBase中,用于查询。
对比一下MapReduce\Tez\Storm\Spark四个框架
MapReduce:是一种离线的计算型框架,将算法抽象成Map和Reduce两个阶段,适合密集型数据计算。不适合迭代计算和交互式计算。缺点是,就只有Map和Reduce操作,需要大量IO,无法利用内存资源,几乎全是磁盘开销。Spark内存计算:适合迭代计算,可以把MR理解为一种磁盘计算框架,而Spark是一种内存型计算框架,将数据放在内存中计算可以提高计算效率,但这对计算的硬件的要求较高。使用scala进行编程更为出色。DAG执行引擎。所以在数据规模和时效性要求两个方面考量是用MR计算还是用Spark计算。Storm:往往跟实时流计算关联。Storm更加擅长对流式计算、实时分析等这种实时计算。实时性能远好于MapReduce。Tez:本质上是对MapReduce进行的优化,用于提高MapReduce的运行效率。依赖DAG作为核心算法模型,可以将MR任务拆分成多个子过程计算,也可以将多个MR任务合并成一个较大的DAG(下面有介绍)任务(可以省去好多存储时间,更专注于计算)。多用于Hive查询优化,用来替代原来的低效MR。
DAG在Hadoop中的应用场景
定义:有向图,从某一点出发无法回到原点。
- Tez
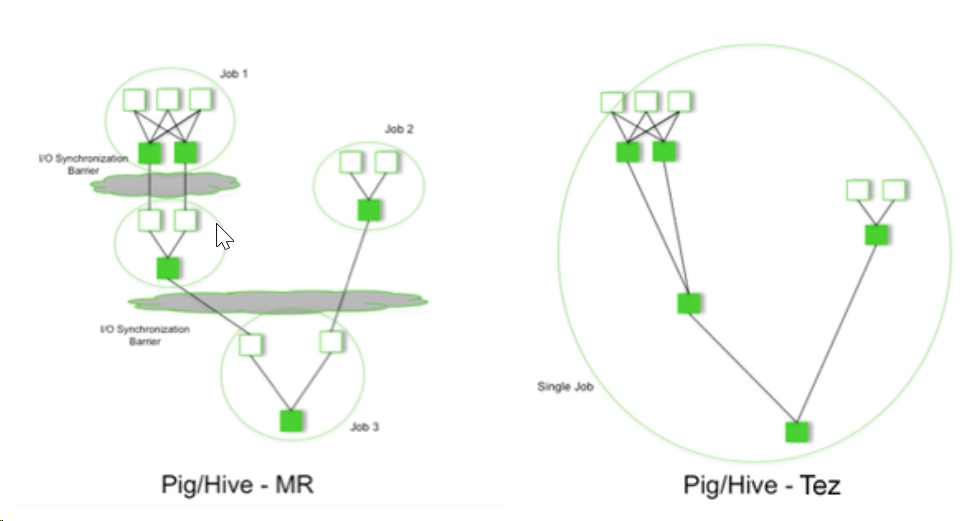
从图中可以看到MR好Tez的区别。比较明显,MR产生中间结果,需要一步步进行。而Tez不产生中间结果,是一气呵成,将多个任务连接成single job,中间的值是直接传递而来,不涉及存取过程。 - Spark
对,就是RDD,一提及Spark的DAG,很快就会联想到Spark的RDD,学 Spark的时候了解到 RDD的两种操作, transform和 action, 其中 transform是一种延时性操作,只有当发生action动作的时候,前面的transform才会执行。理解理解吧,这就是DAG设计啊。 - Oozie
还没使用过,做个了解。是Apache的顶级项目。
主要用于创建工作流,将多个MR/Spark/Pig……任务串在一起,专门针对大规模复杂工作流程和数据管道设计。这个工作流就是DAG图。
Hadoop基础知识串烧的更多相关文章
- Hadoop基础知识
摘要:Hadoop的安装目录了解.etc的核心配置项.hadoop的启动.HDFS文件的block块级副本的存放策略.checkpoint触发设置. 1.hadoop目录了解 bin:可执行文件,命令 ...
- OpenCV探索之路(二):图像处理的基础知识点串烧
opencv图像初始化操作 #include<opencv2\opencv.hpp> #include<opencv2\highgui\highgui.hpp> using n ...
- Hadoop 基础知识
Hadoop 数据是存储在HDFS, Mapreduce 是一种计算框架,负责计算处理. HDFS上的数据存储默认是本地节点数据一份,同一机架不同节点一份,不同机架不同节点一份.默认是存储3份 HDF ...
- 5) 十分钟学会android--ActionBar知识串烧
建立ActionBar Action bar 最基本的形式,就是为 Activity 显示标题,并且在标题左边显示一个 app icon.即使在这样简单的形式下,action bar对于所有的 act ...
- Hadoop基础(一)
Hadoop 基础知识 大数据已经火了很长很长时间了,从最开始是个公司都说自己公司的数据量很大,我们在搞大数据.到现在大数据真的已经非常成熟并且已经在逐渐的影响我们的生产生活.你可能听过支付宝的金融大 ...
- kubebuilder实战之三:基础知识速览
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 零基础学习hadoop开发所必须具体的三个基础知识
大数据hadoop无疑是当前互联网领域受关注热度最高的词之一,大数据技术的应用正在潜移默化中对我们的生活和工作产生巨大的改变.这种改变给我们的感觉是“水到渠成”,更为让人惊叹的是大数据已经仅仅是互联网 ...
- Hadoop基础-Protocol Buffers串行化与反串行化
Hadoop基础-Protocol Buffers串行化与反串行化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们之前学习过很多种序列化文件格式,比如python中的pickl ...
- Hadoop基础-Apache Avro串行化的与反串行化
Hadoop基础-Apache Avro串行化的与反串行化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Apache Avro简介 1>.Apache Avro的来源 ...
随机推荐
- Eclipse中查看没有源码的Class文件的方法
本文地址:http://blog.csdn.net/sushengmiyan/article/details/18798473 本文作者:sushengmiyan 我们在使用Eclipse的时候,经常 ...
- TCP的ACK确认系列 — 延迟确认
主要内容:TCP的延迟确认.延迟确认定时器的实现. 内核版本:3.15.2 我的博客:http://blog.csdn.net/zhangskd 延迟确认模式 发送方在发送数据包时,如果发送的数据包有 ...
- 【Android 应用开发】 ActionBar 基础
作者 : 万境绝尘 (octopus_truth@163.com) 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/3920439 ...
- 【一天一道LeetCode】#50. Pow(x, n)
一天一道LeetCode系列 (一)题目 Implement pow(x, n). (二)解题 题目很简单,实现x的n次方. /* 需要注意一下几点: 1.n==0时,返回值为1 2.x==1时,返回 ...
- Leetcode_12_Integer to Roman
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/42744649 Given an integer, conv ...
- 如何实现 集群化/Session 复制-doc(cluster-howto.html)
源文档链接: http://tomcat.apache.org/tomcat-6.0-doc/cluster-howto.html 翻译日期: 2014年3月19日 翻译人员: 铁锚 感受: Tomc ...
- Cocos2d-swift V3.x 中的update方法
在cocos2d V3.x中update方法如果实现,则会被自动调用;不用向早期的版本那样要显式schedule. 但是你还是要显式schedule其他方法或blocks使用node的schedule ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
- Linux - 用make进行工程编译
首先建立好自己的工作目录 然后创建主函数main.cpp 接着写sinValue.h和cosValue.h函数文件 先按照传统方式进行编译运行 然后用make,先写makefile文件 将原来生成的文 ...
- Android实训案例(一)——计算器的运算逻辑
Android实训案例(一)--计算器的运算逻辑 应一个朋友的邀请,叫我写一个计算器,开始觉得,就一个计算器嘛,很简单的,但是写着写着发现自己写出来的逻辑真不严谨,于是搜索了一下,看到mk(没有打广告 ...