Hadoop基础-Protocol Buffers串行化与反串行化
Hadoop基础-Protocol Buffers串行化与反串行化
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
我们之前学习过很多种序列化文件格式,比如python中的pickle序列化方式(https://www.cnblogs.com/yinzhengjie/p/8531308.html),golang的Gob序列化方式(https://www.cnblogs.com/yinzhengjie/p/7807051.html),hadoop的SequenceFile序列化文件(https://www.cnblogs.com/yinzhengjie/p/9114301.html),Java内置的ObjectOutputStream序列化方式(https://www.cnblogs.com/yinzhengjie/p/8988003.html)等等。
当然,除了语言自己内置的序列化方式外,还有一些手动二进制编码的序列化文件,以及人性化可读格式的序列化文件,比如XMl,JSON,DOM,SAX,STAX,JAXB,JAXP等等,不过这些序列化方式都不是今天的主角,我今天要介绍的是Google公司在2008年就开源的一种序列化方式,即Protocol Buffers序列化。
一.Protocol Buffers 简介
1>.什么是 Protocol Buffers
第一:A description language(一种描述语言);
第二:A complier(它是一个编译器);
第三:A library(它是一种库);
2>.Protocol Buffers 优点
第一:易于使用,高效的二进制编码;
第二:它是由谷歌公司研发的;
第三:简单高效的串行化技术,在2008公开该技术;
3>.支持跨语言
官方支持:Java, C++, and Python等等
非官方支持:C, C#, Erlang, Perl, PHP, Ruby等等
二.Protocol Buffers 代码生成
1>.创建emp.proto自描述文件(非java文件,具体内容如下)
package tutorial;
option java_package = "tutorialspoint.com";
option java_outer_classname = "Emp2";
message Emp {
required int32 id = 1;
required string name = 2;
required int32 age = 3;
required int32 salary = 4;
required string address = 5;
}
2>.将emp.proto(下载地址:链接:https://pan.baidu.com/s/1crYmFwI68kUnzwJgoyOdpw 密码:bh63)和protobuf\src\protoc.exe放在同一个文件夹
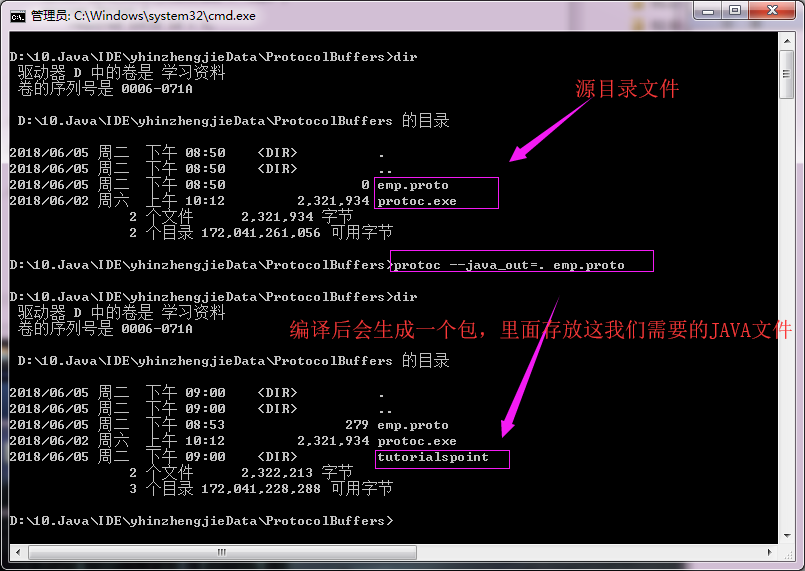
3>.编译emp.proto(protoc --java_out=. emp.proto)
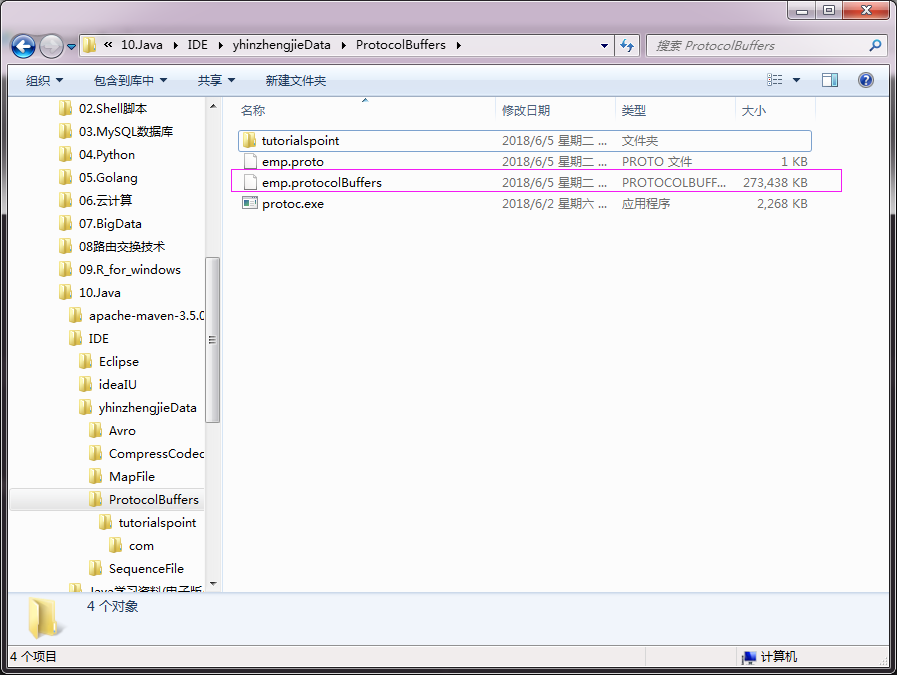
4>.将"D:\10.Java\IDE\yhinzhengjieData\ProtocolBuffers\tutorialspoint\com"(这是我本地目录)下的Emp2.java放置在idea中,包名“tutorialspoint.com”


三.编写代码
1>.编写串行化代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.protocolBuffers; import tutorialspoint.com.Emp2; import java.io.File;
import java.io.FileOutputStream; public class MyProtocolBuffers { private static final File protocolBuffers = new File("D:\\10.Java\\IDE\\yhinzhengjieData\\ProtocolBuffers\\emp.protocolBuffers"); public static void main(String[] args) throws Exception {
protocolBuffersSerial();
}
/**
* 定义序列化方式
*/
public static void protocolBuffersSerial() throws Exception {
long start = System.currentTimeMillis();
FileOutputStream fos = new FileOutputStream(protocolBuffers);
//注意,在序列化一个对象的时候,都是打点的方式设置的哟!在设置完毕后需要以".build"结束!
Emp2.Emp emp = Emp2.Emp.newBuilder().
setId(1).
setName("尹正杰").
setAge(18).
setSalary(66666666).
setAddress("北京").build();
//我们循环写入数据
for (int i = 0; i < 10000000; i++) {
emp.writeTo(fos);
}
fos.close();
System.out.printf("这是protocol Buffers序列化方式: 生成文件大小:[%d],用时:[%d]\n",protocolBuffers.length(),System.currentTimeMillis() - start);
}
} /*
以上代码执行结果如下:
这是protocol Buffers序列化方式: 生成文件大小:[280000000],用时:[10960]
*/
执行以上代码后,在本地目录会生成一个文件如下:
2>.编写反串行化代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.protocolBuffers; import tutorialspoint.com.Emp2; import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream; public class MyProtocolBuffers { private static final File protocolBuffers = new File("D:\\BigData\\JavaSE\\yinzhengjieData\\ProtocolBuffers\\emp.protocolBuffers"); public static void main(String[] args) throws Exception {
protocolBuffersSerial();
protocolBuffersDeserial();
}
/**
* 定义序列化方式
*/
public static void protocolBuffersSerial() throws Exception {
long start = System.currentTimeMillis();
FileOutputStream fos = new FileOutputStream(protocolBuffers);
//注意,在序列化一个对象的时候,都是打点的方式设置的哟!在设置完毕后需要以".build"结束!
Emp2.Emp emp = Emp2.Emp.newBuilder().
setId(1).
setName("尹正杰").
setAge(18).
setSalary(66666666).
setAddress("北京").build();
//我们循环写入数据
for (int i = 0; i < 2000000; i++) {
emp.writeTo(fos);
}
fos.close();
System.out.printf("这是protocol Buffers序列化方式: 生成文件大小:[%d],用时:[%d]\n",protocolBuffers.length(),System.currentTimeMillis() - start);
} /**
* 定义反序列化方式
*/
public static void protocolBuffersDeserial() throws Exception {
long start = System.currentTimeMillis();
FileInputStream fis = new FileInputStream(protocolBuffers); Emp2.Emp emp = Emp2.Emp.parseFrom(fis); for (int i = 0; i < 2000000; i++) {
emp.getId();
emp.getName();
emp.getAge();
emp.getSalary();
emp.getAddress();
}
System.out.printf("这是protocol Buffers反序列化方式: 生成文件大小:[%d],用时:[%d]\n",protocolBuffers.length(),System.currentTimeMillis() - start);
} }
Hadoop基础-Protocol Buffers串行化与反串行化的更多相关文章
- Hadoop基础-Apache Avro串行化的与反串行化
Hadoop基础-Apache Avro串行化的与反串行化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Apache Avro简介 1>.Apache Avro的来源 ...
- PHP中的抽象类与抽象方法/静态属性和静态方法/PHP中的单利模式(单态模式)/串行化与反串行化(序列化与反序列化)/约束类型/魔术方法小结
前 言 OOP 学习了好久的PHP,今天来总结一下PHP中的抽象类与抽象方法/静态属性和静态方法/PHP中的单利模式(单态模式)/串行化与反串行化(序列化与反序列化). 1 PHP中的抽象 ...
- C#基础知识回顾--串行化与反串行化
串行化是指存储和获取磁盘文件.内存或其他地方中的对象.在串行化时,所有的实例数据都保存到存储介质上, 在取消串行化时,对象会被还原,且不能与其原实例区别开来.只需给类添加Serializable属性, ...
- C#--串行化与反串行化
串行化是指存储和获取磁盘文件.内存或其他地方中的对象.在串行化时,所有的实例数据都保存到存储介质上,在取消串行化时,对象会被还原,且不能与其原实例区别开来.只需给类添加Serializable属性,就 ...
- Hadoop基于Protocol Buffer的RPC实现代码分析-Server端
http://yanbohappy.sinaapp.com/?p=110 最新版本的Hadoop代码中已经默认了Protocol buffer(以下简称PB,http://code.google.co ...
- Protocol Buffers学习教程
最近看公司代码的过程中,看到了很多proto后缀的文件,这是个啥玩意?问了大佬,原来这是Protocol Buffers! 这玩意是干啥的?查完资料才知道,又是谷歌大佬推的开源组件,这玩意完全可以取代 ...
- Google Protocol Buffers 入门
Google Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化.它很适合做数据存储或 RPC 数据交换格式.可用于通讯协议.数据存储等领域的 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
随机推荐
- Bing词典vs有道词典比对测试报告——功能篇之核心功能
必应词典vs有道词典 核心功能对比 从应用的UI布局来看,这两款软件的功能如下: 相同 不同 必应词典 词典.例句.翻译 百科 有道词典 词典.例句.翻译 应用 就词典类软件来说,词典是最核心的功能. ...
- mysql 修改语句及耗时
1.含有某串字母的字段替换: update imagetable set imageID = replace(imageID, 'ZH0211001', 'ZH4111001') 只要imageID含 ...
- 【每日scrum】第一次冲刺day2
和小伙伴一起找地图 ,学习了mapinfo地图格式的基本知识,数据和图像分开存储
- Sprint会议2
昨天:准备查找安卓APP开发的有关资料,安装有关软件 今天:自己制作一个安卓小程序,熟悉一下操作 遇到问题:安装遇到问题,环境配置出现问题
- iOS- Exception Type: 00000020:什么是看门狗机制
1.前言 前几天我们项目闪退之后遇到的一个Crash,之后逛了许多论坛,博客都没有找到满意的回复 在自己做了深入的研究之后,对iOS的看门狗机制有了一个基本的了解 而有很多奇怪的Cras ...
- 6th Alpha阶段的postmortem报告
组名:好好学习(代组长发布) 会议重要内容记录: 1. 尝试在beta阶段实现的功能,与alpha阶段相比的优势 (1)更改软件现有的bug: 1)软件的账目只能输入,但是一旦发生失误却无法更改和 ...
- java杂项
简单介绍==和equals区别==是判断两个变量或实例是不是指向同一个内存空间equals是判断两个变量或实例所指向的内存空间的值是不是相同 final, finally, finalize的区别fi ...
- python3 执行AES加密方法
cmd执行命令:pip install pycryptodome # -*- coding: utf-8 -*- # __author__ = 'Carry' import base64 from C ...
- js小功能记录
个人日常中遇到的js小功能记录,方便查看. /** * 判断是否包含字符串某字符串 * @param {[type]} str [被检测的字符串] * @param {[type]} substr [ ...
- Mxnet Windows配置
MXNET Windows 编译安装(Python) 本文只记录Mxnet在windows下的编译安装,更多环境配置请移步官方文档:http://mxnet.readthedocs.io/en/lat ...