pytorch识别CIFAR10:训练ResNet-34(微调网络,准确率提升到85%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处。联系方式:460356155@qq.com
在前一篇中的ResNet-34残差网络,经过训练准确率只达到80%。
这里对网络做点小修改,在最开始的卷积层中用更小(3*3)的卷积核,并且不缩小图片尺寸,相应的最后的平均池化的核改为4*4。
具体修改如下:
class ResNet34(nn.Module):
def __init__(self, block):
super(ResNet34, self).__init__() # 初始卷积层核池化层
self.first = nn.Sequential(
# 卷基层1:3*3kernel,1stride,1padding,outmap:32-3+1*2 / 1 + 1,32*32
nn.Conv2d(3, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True), # 最大池化,3*3kernel,1stride(保持尺寸),1padding,
# outmap:32-3+2*1 / 1 + 1,32*32
nn.MaxPool2d(3, 1, 1)
) # 第一层,通道数不变
self.layer1 = self.make_layer(block, 64, 64, 3, 1) # 第2、3、4层,通道数*2,图片尺寸/2
self.layer2 = self.make_layer(block, 64, 128, 4, 2) # 输出16*16
self.layer3 = self.make_layer(block, 128, 256, 6, 2) # 输出8*8
self.layer4 = self.make_layer(block, 256, 512, 3, 2) # 输出4*4 self.avg_pool = nn.AvgPool2d(4) # 输出512*1
self.fc = nn.Linear(512, 10)
运行结果:
Files already downloaded and verified
ResNet34(
(first): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
)
(layer1): Sequential(
(0): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): ResBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): ResBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): ResBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avg_pool): AvgPool2d(kernel_size=4, stride=4, padding=0)
(fc): Linear(in_features=512, out_features=10, bias=True)
)
one epoch spend: 0:00:55.832303
EPOCH:1, ACC:53.05
one epoch spend: 0:00:54.158082
EPOCH:2, ACC:61.94
......
one epoch spend: 0:00:54.178677
EPOCH:199, ACC:85.37
one epoch spend: 0:00:53.657917
EPOCH:200, ACC:85.25
CIFAR10 pytorch ResNet34 Train: EPOCH:200, BATCH_SZ:128, LR:0.1, ACC:85.38
train spend time: 3:11:21.618257
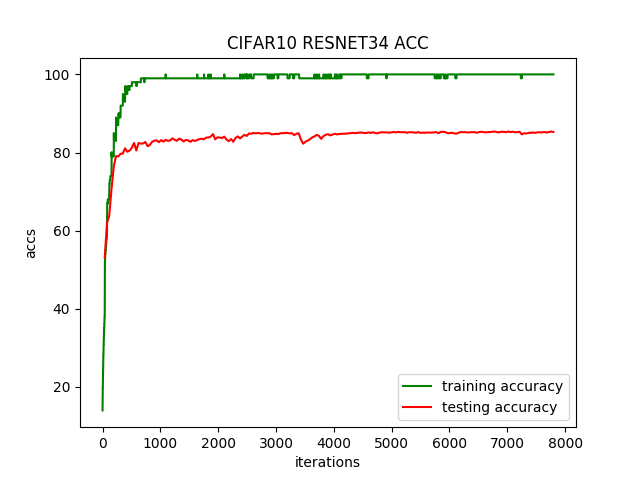
运行200个迭代,每个迭代耗时54秒,准确率提升了5%,达到85%。准确率变化曲线如下:
pytorch识别CIFAR10:训练ResNet-34(微调网络,准确率提升到85%)的更多相关文章
- pytorch识别CIFAR10:训练ResNet-34(数据增强,准确率提升到92.6%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前一篇中的ResNet-34残差网络,经过减小卷积核训练准确率提升到85%. 这里对训练数据集做数据 ...
- pytorch识别CIFAR10:训练ResNet-34(准确率80%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com CNN的层数越多,能够提取到的特征越丰富,但是简单地增加卷积层数,训练时会导致梯度弥散或梯度爆炸. 何 ...
- pytorch识别CIFAR10:训练ResNet-34(自定义transform,动态调整学习率,准确率提升到94.33%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 前面通过数据增强,ResNet-34残差网络识别CIFAR10,准确率达到了92.6. 这里对训练过程 ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(二)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com AlexNet在2012年ImageNet图像分类任务竞赛中获得冠军.网络结构如下图所示: 对CIFA ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com VGGNet在2014年ImageNet图像分类任务竞赛中有出色的表现.网络结构如下图所示: 同样的, ...
- PyTorch Tutorials 4 训练一个分类器
%matplotlib inline 训练一个分类器 上一讲中已经看到如何去定义一个神经网络,计算损失值和更新网络的权重. 你现在可能在想下一步. 关于数据? 一般情况下处理图像.文本.音频和视频数据 ...
- Caffe fine-tuning 微调网络
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ 目前呢,caffe,theano,torch是当下比较流行的De ...
- 用pytorch进行CIFAR-10数据集分类
CIFAR-10.(Canadian Institute for Advanced Research)是由 Alex Krizhevsky.Vinod Nair 与 Geoffrey Hinton 收 ...
- 【转】CNN+BLSTM+CTC的验证码识别从训练到部署
[转]CNN+BLSTM+CTC的验证码识别从训练到部署 转载地址:https://www.jianshu.com/p/80ef04b16efc 项目地址:https://github.com/ker ...
随机推荐
- Docker 导出&加载镜像
文章首发自个人网站:https://www.exception.site/docker/docker-save-load-image 本文中,您将学习 Docker 如何导出&加载镜像.当我们 ...
- 【工利其器】必会工具之(三)systrace篇(1)官网翻译
前言 Android 开发者官网中对systrace(Android System Trace)有专门的介绍,本篇文章作为systrace系列的开头,笔者先不做任何介绍,仅仅翻译一下官网的介绍.在后续 ...
- 《前端之路》之 初识 JavaScript
01 初识 JavaScript 作为在码农圈混迹了 四五年的老码畜来说,学习一门新的语言,就仿佛是老司机开新车一样 轻车熟路. 为什么会这么快呢? 因为各种套路啊- 任何一种计算机语言的最开始都是和 ...
- 【Android Studio安装部署系列】三十七、从Android Studio3.2升级到Android Studio3.4【以及创建Android Q模拟器】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 概述 保持Android Studio开发环境的最新版本. 下载Android Studio3.4 使用Android Studio自带的 ...
- kubectl自动补全
source <(kubectl completion bash) echo "source <(kubectl completion bash)" >> ...
- 点击菜单选项,右侧主体区新增子界面(Tab)的实现
今天是2019年小年后一天,还有三天回家过年. 今天记录一下一种前端页面的效果的实现,这种效果很常见,一般用于网站后台系统的前端页面.一般后台系统会分为顶部导航栏,左边的菜单栏和右边的主体区.有一种效 ...
- 【Redis】LRU算法和Redis的LRU实现
LRU原理 在一般标准的操作系统教材里,会用下面的方式来演示 LRU 原理,假设内存只能容纳3个页大小,按照 7 0 1 2 0 3 0 4 的次序访问页.假设内存按照栈的方式来描述访问时间,在上面的 ...
- css3 动画 总结
原来的时候写过一个小程序,里面有一个播放背景音乐的按钮(也是一个圆形的图片),它是一直在旋转的,当我们点击这个按钮的可以暂停或者播放背景音乐.当初的这个动画,是同事自己写的,我看到的时候以为是他在上面 ...
- java 线程池 ---- newSingleThreadExecutor()
class MyThread implements Runnable{ private int index; public MyThread(int index){ this.index = inde ...
- 小米平板8.0以上系统如何不用root激活xposed框架的流程
在大多使用室的引流,或业务操作中,基本上都需要使用安卓的强大XPOSED框架,近来我们使用室购来了一批新的小米平板8.0以上系统,基本上都都是基于7.0以上系统版本,基本上都不能够刷入ROOT的su权 ...