pytorch识别CIFAR10:训练ResNet-34(自定义transform,动态调整学习率,准确率提升到94.33%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处。联系方式:460356155@qq.com
前面通过数据增强,ResNet-34残差网络识别CIFAR10,准确率达到了92.6。
这里对训练过程增加2个处理:
1、训练数据集做进一步处理:对图片随机加正方形马赛克。
2、每50个epoch,学习率降低0.1倍。
代码具体修改如下:
自定义transform:
class Cutout(object):
def __init__(self, hole_size):
# 正方形马赛克的边长,像素为单位
self.hole_size = hole_size def __call__(self, img):
return cutout(img, self.hole_size) def cutout(img, hole_size):
y = np.random.randint(32)
x = np.random.randint(32) half_size = hole_size // 2 x1 = np.clip(x - half_size, 0, 32)
x2 = np.clip(x + half_size, 0, 32)
y1 = np.clip(y - half_size, 0, 32)
y2 = np.clip(y + half_size, 0, 32) imgnp = np.array(img) imgnp[y1:y2, x1:x2] = 0
img = Image.fromarray(imgnp.astype('uint8')).convert('RGB')
return img
数据集处理修改:
transform_train = transforms.Compose([
# 对原始32*32图像四周各填充4个0像素(40*40),然后随机裁剪成32*32
transforms.RandomCrop(32, padding=4), # 随机马赛克,大小为6*6
Cutout(6), # 按0.5的概率水平翻转图片
transforms.RandomHorizontalFlip(), transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) transform_test = tv.transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) # 定义数据集
train_data = tv.datasets.CIFAR10(root=ROOT, train=True, download=True, transform=transform_train)
test_data = tv.datasets.CIFAR10(root=ROOT, train=False, download=False, transform=transform_test)
训练过程中调整学习率:
for epoch in range(1, args.epochs + 1):
if epoch % 50 == 0:
lr = args.lr * (0.1 ** (epoch // 50)) for params in optimizer.param_groups:
params['lr'] = lr net_train(net, train_load, optimizer, epoch, args.log_interval) # 每个epoch结束后用测试集检查识别准确度
net_test(net, test_load, epoch)
运行结果如下:
Files already downloaded and verified
ResNet34(
(first): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
)
(layer1): Sequential(
(0): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): ResBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): ResBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): ResBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avg_pool): AvgPool2d(kernel_size=4, stride=4, padding=0)
(fc): Linear(in_features=512, out_features=10, bias=True)
)
one epoch spend: 0:01:11.775634
EPOCH:1, ACC:44.28
one epoch spend:
0:01:12.244757
EPOCH:2, ACC:54.46
one epoch spend:
0:01:12.360205
EPOCH:3, ACC:56.84
............
one epoch spend: 0:01:19.172188
EPOCH:198, ACC:94.2
one epoch spend:
0:01:19.213334
EPOCH:199, ACC:94.19
one epoch spend:
0:01:19.222612
EPOCH:200, ACC:94.21
CIFAR10 pytorch
ResNet34 Train: EPOCH:200, BATCH_SZ:128, LR:0.1, ACC:94.33
train spend time:
4:21:32.548834
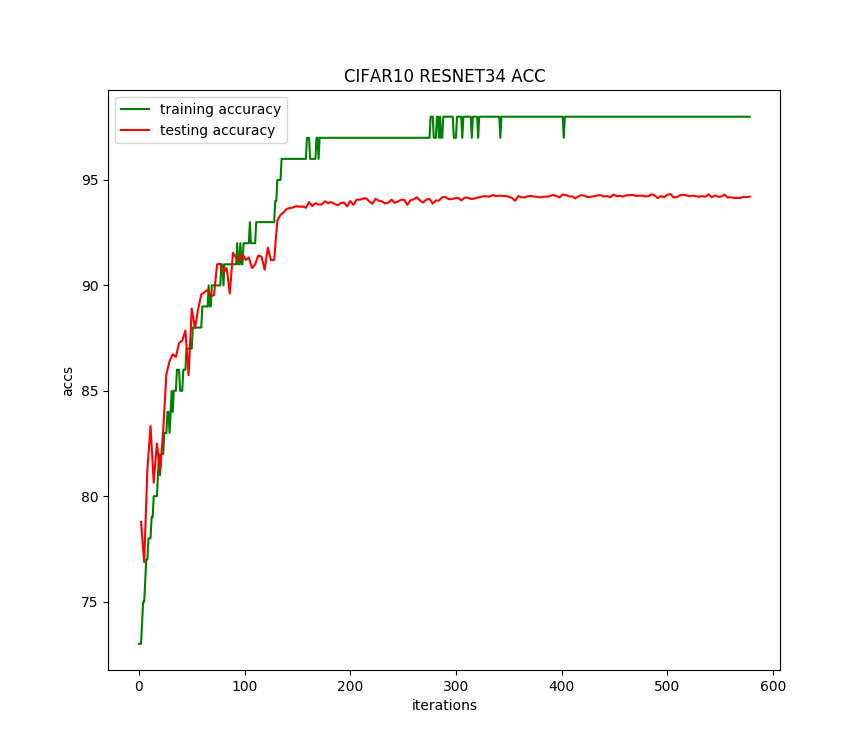
运行200个迭代,每个迭代耗时80秒,准确率提升了1.73%,达到94.33%。准确率变化曲线如下:
pytorch识别CIFAR10:训练ResNet-34(自定义transform,动态调整学习率,准确率提升到94.33%)的更多相关文章
- pytorch识别CIFAR10:训练ResNet-34(准确率80%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com CNN的层数越多,能够提取到的特征越丰富,但是简单地增加卷积层数,训练时会导致梯度弥散或梯度爆炸. 何 ...
- pytorch识别CIFAR10:训练ResNet-34(数据增强,准确率提升到92.6%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前一篇中的ResNet-34残差网络,经过减小卷积核训练准确率提升到85%. 这里对训练数据集做数据 ...
- pytorch识别CIFAR10:训练ResNet-34(微调网络,准确率提升到85%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前一篇中的ResNet-34残差网络,经过训练准确率只达到80%. 这里对网络做点小修改,在最开始的 ...
- pytorch 动态调整学习率 重点
深度炼丹如同炖排骨一般,需要先大火全局加热,紧接着中火炖出营养,最后转小火收汁.本文给出炼丹中的 “火候控制器”-- 学习率的几种调节方法,框架基于 pytorch 1. 自定义根据 epoch 改变 ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(二)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com AlexNet在2012年ImageNet图像分类任务竞赛中获得冠军.网络结构如下图所示: 对CIFA ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com VGGNet在2014年ImageNet图像分类任务竞赛中有出色的表现.网络结构如下图所示: 同样的, ...
- PyTorch Tutorials 4 训练一个分类器
%matplotlib inline 训练一个分类器 上一讲中已经看到如何去定义一个神经网络,计算损失值和更新网络的权重. 你现在可能在想下一步. 关于数据? 一般情况下处理图像.文本.音频和视频数据 ...
- Pytorch多GPU训练
Pytorch多GPU训练 临近放假, 服务器上的GPU好多空闲, 博主顺便研究了一下如何用多卡同时训练 原理 多卡训练的基本过程 首先把模型加载到一个主设备 把模型只读复制到多个设备 把大的batc ...
- CNN+BLSTM+CTC的验证码识别从训练到部署
项目地址:https://github.com/kerlomz/captcha_trainer 1. 前言 本项目适用于Python3.6,GPU>=NVIDIA GTX1050Ti,原mast ...
随机推荐
- 从壹开始前后端分离 [ Vue2.0+.NET Core2.1] 十五 ║Vue基础:JS面向对象&字面量& this字
缘起 书接上文<从壹开始前后端分离 [ Vue2.0+.NET Core2.1] 十四 ║ VUE 计划书 & 我的前后端开发简史>,昨天咱们说到了以我的经历说明的web开发经历的 ...
- Identity Server 4 预备知识 -- OpenID Connect 简介
我之前的文章简单的介绍了OAuth 2.0 (在这里: https://www.cnblogs.com/cgzl/p/9221488.html), 还不是很全. 这篇文章我要介绍一下 OpenID C ...
- 【Linux篇】--awk的使用
一.前述 awk是一个强大的文本分析工具.相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,(空格,制表符)为默认分隔符将每行切片 ...
- JS ES6的变量的结构赋值
变量的结构赋值用户很多 1.交换变量的值 let x = 1; let y = 2; [x,y] = [y,x] 上面的代码交换变量x和变量y的值,这样的写法不仅简洁,易读,语义非常清晰 2.从函数返 ...
- 【原创】Mindjet Manager思维导图软件云服务功能的使用方法
注:自己使用了mindjet manager来画思维导图已经有一段时间了,无疑mindjet manager的功能是很强大的,但是最近因为自己两台电脑都安装了mindjet manager,每 ...
- SLAM+语音机器人DIY系列:(八)高阶拓展——1.miiboo机器人安卓手机APP开发
android要与ROS通讯,一种是基于rosbridge,另一种是基于rosjava库. 相关参考例子工程 rosbridge例子: https://github.com/hibernate2011 ...
- .net core中使用autofac进行IOC
.net Core中自带DI是非常简单轻量化的,但是如果批量注册就得扩展,下面使用反射进行批量注册的 public void AddAssembly(IServiceCollection servic ...
- Java 中的几种线程池,你之前用对了吗
好久不发文章了,难道是因为忙,其实是因为懒.这是一篇关于线程池使用和基本原理的科普水文,如果你经常用到线程池,不知道你的用法标准不标准,是否有隐藏的 OOM 风险.不经常用线程池的同学,还有对几种线程 ...
- 一文搞定MySQL的事务和隔离级别
一.事务简介 事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成. 一个数据库事务通常包含了一个序列的对数据库的读/写操作.它的存在包含有以下两个目的: 为数据库操作序列提供 ...
- Java中数组的插入,删除,扩张
Java中数组是不可变的,但是可以通过本地的arraycop来进行数组的插入,删除,扩张.实际上数组是没变的,只是把原来的数组拷贝到了另一个数组,看起来像是改变了. 语法: System.arrayc ...