论文笔记(1):From Image-level to Pixel-level Labeling with Convolutional Networks
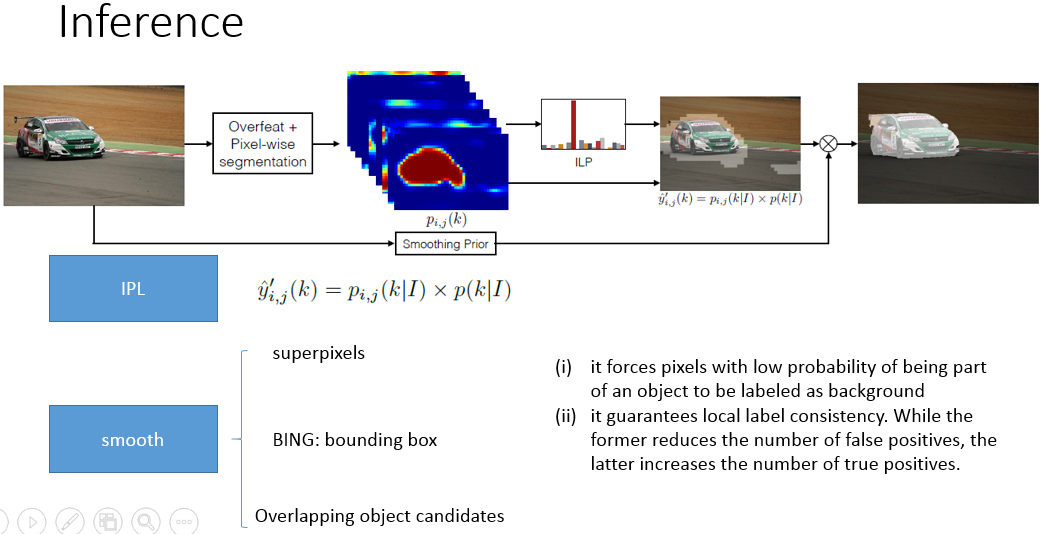
文章采用了多实例学习(MIL)机制构建图像标签同像素语义的关联 。 该方法的训练样本包含了70 万张来自ImageNet的图片,但其语义分割的性能很大程度上依赖于复杂的后处理过程,主要包括图像级语义的预测信息、超像素平滑策略、物体候选框平滑策略和 MCG分割区域平滑策略。
下图是论文所用方法的一般性说明:
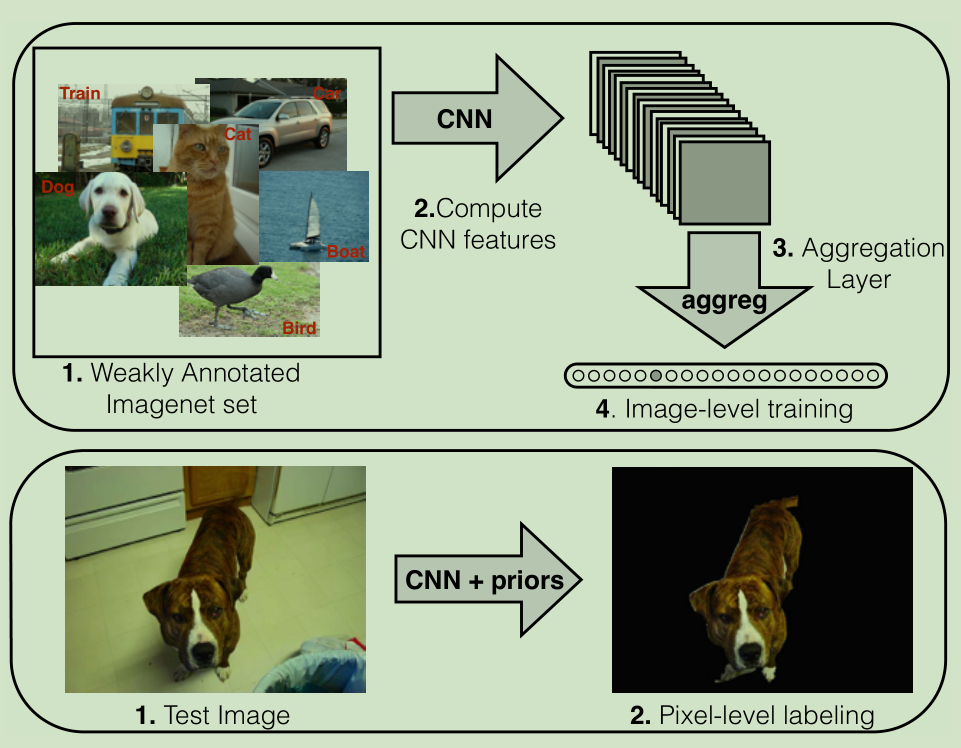
(1)使用来自Imagenet的弱注释数据(仅图像级别的类别信息)对模型进行训练。
(2)CNN生成特征平面。
(3)这些平面通过一个聚合层来约束模型,把更多的权重放在正确的像素上。
(4)通过分类正确的图像级标签来训练系统。
底部:在测试期间,聚合层被去除,并且CNN密集地将图像的每个像素进行分类(仅考虑少数分割先验)。
3 Architecture
正如我们在第1节中指出的,CNN是一个非常灵活的模型,可以应用于各种图像处理任务,因为它们减轻了任务特定功能的需求。 CNN学习过滤器的层次结构,当层次结构“更深入”时,过滤器提取更高层次的表示。 他们学习的功能类型也是非常普遍的,CNN使转移学习(到另一个任务)非常容易。 但是,这些模型的主要缺点是在训练过程中需要大量的数据。
由于图像级对象标签的数量比像素级分割标签大得多,因此利用图像分类数据集来执行分割是理所当然的。 接下来,我们考虑一个类C的分割问题。我们假设分类数据集至少包含相同的类。
在分类时可用的额外类,不在分割数据集中的,映射到“背景”类。 这个背景类对于在分割过程中限制假阳性的数量是必不可少的。
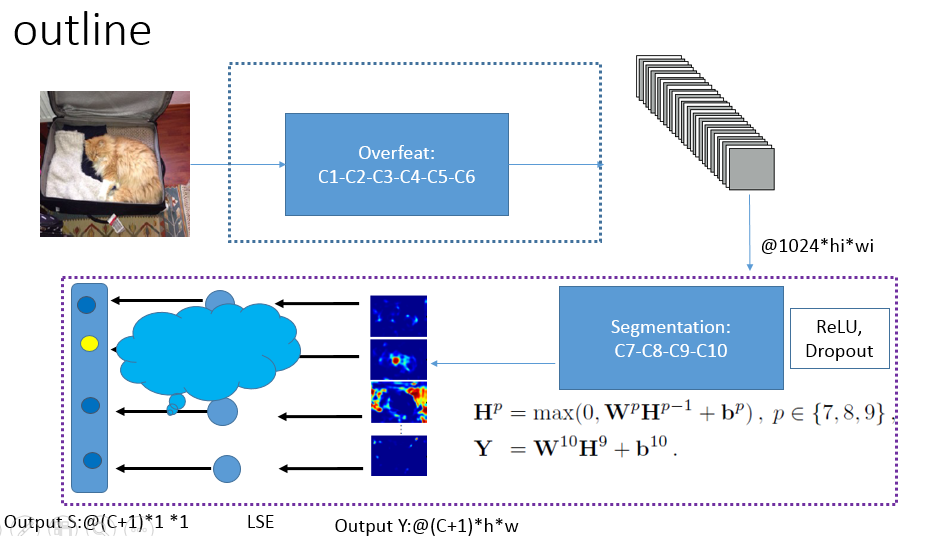
我们的架构是CNN,它是通过Imagenet的一个子集进行训练的,从图像级标签生成像素级标签。 如图2所示,我们的CNN是相当标准的,有10级卷积和(可选)池化。输入一个400×400的RGB补丁I,并输出对应于12倍下采样图像像素标签分数的| C | +1个平面(每个类一个,加上背景类)。在训练过程中,第3.1节中介绍的一个额外图层将像素级标签聚合为图像级标签。 出于计算能力的原因,我们“冻结”了CNN的第一层,以及一些已经训练有素(通过Imagenet分类数据)的CNN模型。
我们选择训练以用于对ILSVRC13进行对象分类的Overfeat。Overfeat模型生成尺寸为1024×hi×wi的特征图,其中hi和wi是RGB输入图像大小,卷积核大小,卷积步长和最大池大小的函数。只保留前6个卷积层和2个Overfeat层,我们的RGB 400×400图像块I被转换成1024×29×29的特征表示。
我们增加了四个额外的卷积层(我们用H6来表示来自OverFeat的特征面)。 每一个(除了最后的Y)之后是逐点校正非线性(ReLU)单元。
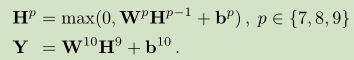
(W p,b p)表示第p层的参数。 在这一步,我们不使用任何最大池化。 一个dropout正规化策略被用于所有层(以防止过拟合)。 网络输出| C | + 1个维度为h o×w o的特征平面,训练中考虑为每个类别加上背景。
3.1 Multiple Instance Learning
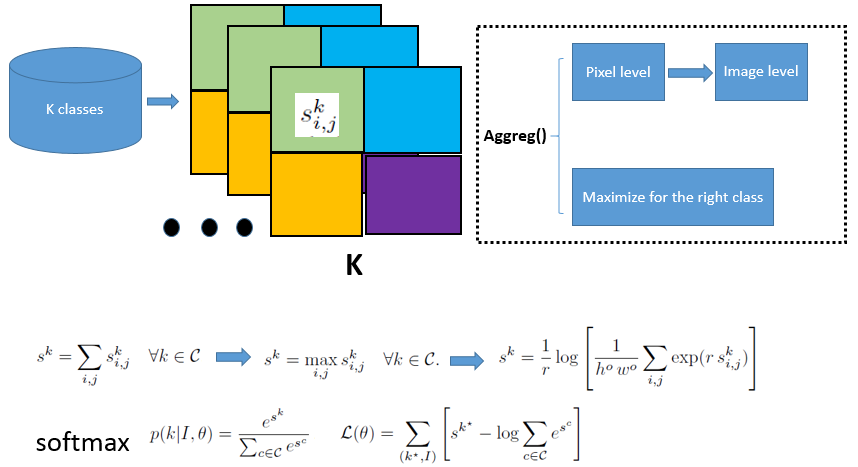
网络从二次采样图像I为每个像素位置(i,j)产生一个分数 和对于每个k∈C的类。假定在训练期间,我们只能访问图像类别标签,我们需要一种方法来聚合这些像素级分数,将其合并为一个单一的图像级别的分数
和对于每个k∈C的类。假定在训练期间,我们只能访问图像类别标签,我们需要一种方法来聚合这些像素级分数,将其合并为一个单一的图像级别的分数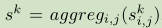 ,然后将最大化正确的类标签k*。 假设聚合过程aggreg()已经被选择,我们通过应用下面的softmax函数将图像级别的分数解释为类别条件概率:
,然后将最大化正确的类标签k*。 假设聚合过程aggreg()已经被选择,我们通过应用下面的softmax函数将图像级别的分数解释为类别条件概率:
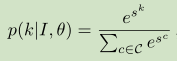
其中θ= {W p,b p∀p}表示我们框架下的所有可训练参数。 然后,我们在所有训练数据对(I,k*)上最大化对数似然(关于θ):
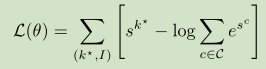
训练是通过随机梯度来实现的,通过softmax,聚合过程进行反向传播,并且直到我们网络的第一个非冻结层。(原文勘误:应为up to the而不是“up the to”)
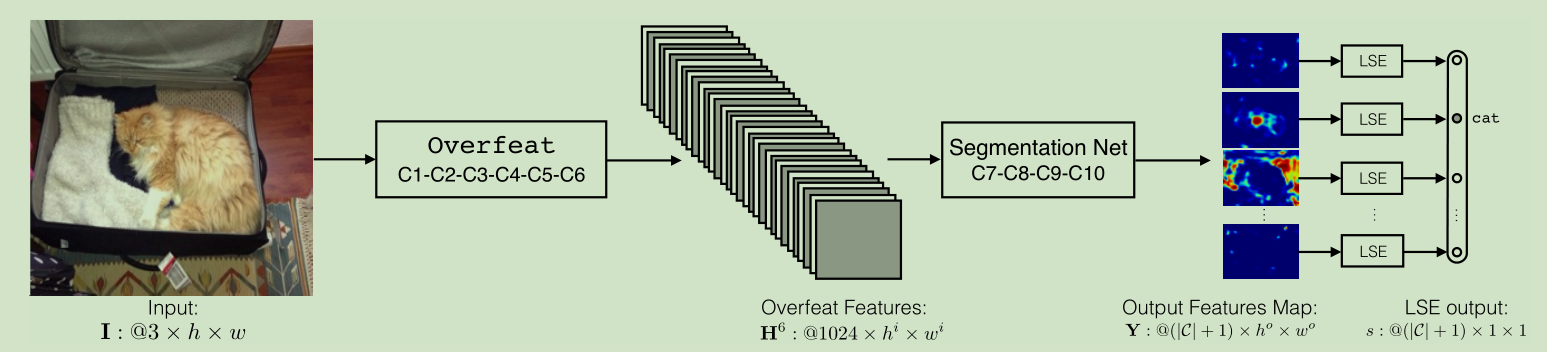
Figure 2:完整的RGB图像通过网络(由Overfeat和四个额外的卷积特征组成)向前传送,生成维度(| C | + 1)×h o×w o的输出平面。 这些输出平面可以看作是输入图像的子采样版本的像素级标签。 然后,输出通过Log-Sum-Exp图层将像素级标签聚合成图像级标签。 误差通过层C10-C7反向传播。
Aggregation
聚合应该促使网络走向正确的像素级分配,这样它可以在分割任务上正常执行。 一个明显的聚合将是所有像素位置的总和:
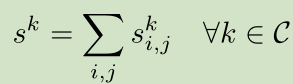
然而,这将在训练过程中对图像的所有像素赋予相同的权重,甚至对该图像上不属于类别标签的像素分配权重(even to the ones which do not belong to the class label assigned to the image)。注意,该聚合方法与通过mini-batch应用传统的全连接分类CNN等同。 实际上,输出平面中的每个值对应于以输入平面中的对应像素为中心的 sub-patch的CNN的输出。 另一方面,可以应用一个最大池化来汇总:
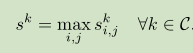
这将促使该模型增加被认为是图像级分类最重要的像素的分数。 根据我们的经验,这种方法训练得不好。 请注意,在训练开始时,所有像素可能具有相同(错误)的分数,但是只有一个(由max选择)将在训练过程的每一步都增加其分数。 因此,模型需要大量的时间才能收敛也不奇怪。
我们选择了最大函数的平滑版本和凸近似,称为Log-Sum-Exp(LSE):
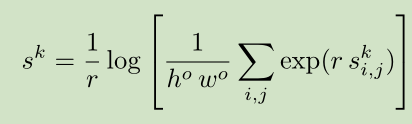
超参数r控制近似值的平滑程度:高r值意味着具有类似于最大值的效果,非常低的值将具有类似于得分平均的效果。 这种聚合的优点是在训练过程中具有相似分数的像素将具有相似的权重,参数r控制这种“相似性”。
论文笔记(1):From Image-level to Pixel-level Labeling with Convolutional Networks的更多相关文章
- 论文笔记:《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks DeepLearning 》
一.Abstract综述 训练出一个CNN可以同时实现分类,定位和检测..,三个任务共用同一个CNN网络,只是在pool5之后有所不同 二.分类 这里CNN的结构是对ALEXNET做了一些改进,具体的 ...
- 论文笔记:ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks
ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks2018-03-05 11:13:05 ...
- 论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks
论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks 2018年07月11日 14 ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 【论文笔记】张航和李沐等提出:ResNeSt: Split-Attention Networks(ResNet改进版本)
github地址:https://github.com/zhanghang1989/ResNeSt 论文地址:https://hangzhang.org/files/resnest.pdf 核心就是: ...
- 论文笔记:SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 2019-04-02 12:44:36 Paper:ht ...
- Video Frame Synthesis using Deep Voxel Flow 论文笔记
Video Frame Synthesis using Deep Voxel Flow 论文笔记 arXiv 摘要:本文解决了模拟新的视频帧的问题,要么是现有视频帧之间的插值,要么是紧跟着他们的探索. ...
- 论文笔记《Feedforward semantic segmentation with zoom-out features》
[论文信息] <Feedforward semantic segmentation with zoom-out features> CVPR 2015 superpixel-level,f ...
随机推荐
- mysql查找以逗号分隔的值-find_in_set
有了FIND_IN_SET这个函数.我们可以设计一个如:一只手机即是智能机,又是Andriod系统的. 比如:有个产品表里有一个type字段,他存储的是产品(手机)类型,有 1.智能机,2.Andri ...
- wordpress配置固定链接nginx访问404问题解决方法
WordPress支持使用固定链接,但是在ngnix环境下,访问页面后出现404, 其实官方是有文档说明的,需要单独写配置, 我这边配置的示例代码如下: server { listen 8 ...
- ElasticSearch Kibana 和Logstash 安装x-pack记录
前言 最近用到了ELK的集群,想想还是用使用官方的x-pack的monitor功能对其进行监控,这里先上图看看: 环境如下: 操作系统: window 2012 R2 ELK : elasticsea ...
- 浅谈PHP答题卡识别(一)
最近期末考试考完了,我们也要放寒假了.于是突发奇想,想用PHP写一个答题卡识别程序.已经实现了一些,现分享给大家. 具体的步骤如下: 上传答题卡=>图片二值化(已实现)=>寻找定位点(已实 ...
- 高并发关于微博、秒杀抢单等应用场景在PHP环境下结合Redis队列延迟入库
第一步:创建模拟数据表. CREATE TABLE `test_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `uid` int(11) NOT NUL ...
- javascript正则表达式的一些笔记
正则表达式:Regular Expression.使用单个字符串来描述,匹配一系列符合某个句法规则的字符串.即按照某种规则去匹配符合条件的字符串.正则表达式就是规则. \b 单词边界 regexp对象 ...
- UVALive - 3644 X-Plosives (并查集)
思路:每一个product都可以作一条边,每次添加一条边,如果这边的加入使得某个集合构成环,就应该refuse,那么就用并查集来判断. AC代码: //#define LOCAL #include & ...
- nyoj281 整数中的1(二) 数位DP
和整数中的1一毛一样.就是输入时改了一下罢了. AC代码: #include<cstdio> const int maxn = 35; int w[maxn], h[maxn]; void ...
- 【BZOJ3993】 星际战争
Time Limit: 1000 ms Memory Limit: 128 MB Description 3333年,在银河系的某星球上,X军团和Y军团正在激烈地作战.在战斗的某一阶段,Y军团一 ...
- Java--JDBC连接数据库(二)
本篇文章接着上篇文章,还剩下一个知识点是,可滚动的结果接集和可更新的结果集.一般默认情况之下,多结果集是不可以显式滚动,移动选择的.如果想要做到,需要指定一些参数,那么本篇就接着介绍如何操作可滚动的结 ...