爬虫实战【7】Ajax解析续-今日头条图片下载
昨天我们分析了今日头条搜索得到的信息,一直对图集感兴趣的我还是选择将所有的图片下载下来。
我们继续讲一下如何通过各个图集的url得到每个图集下面的照片。
分析图集的组成
【插入图片,某个图集的页面】
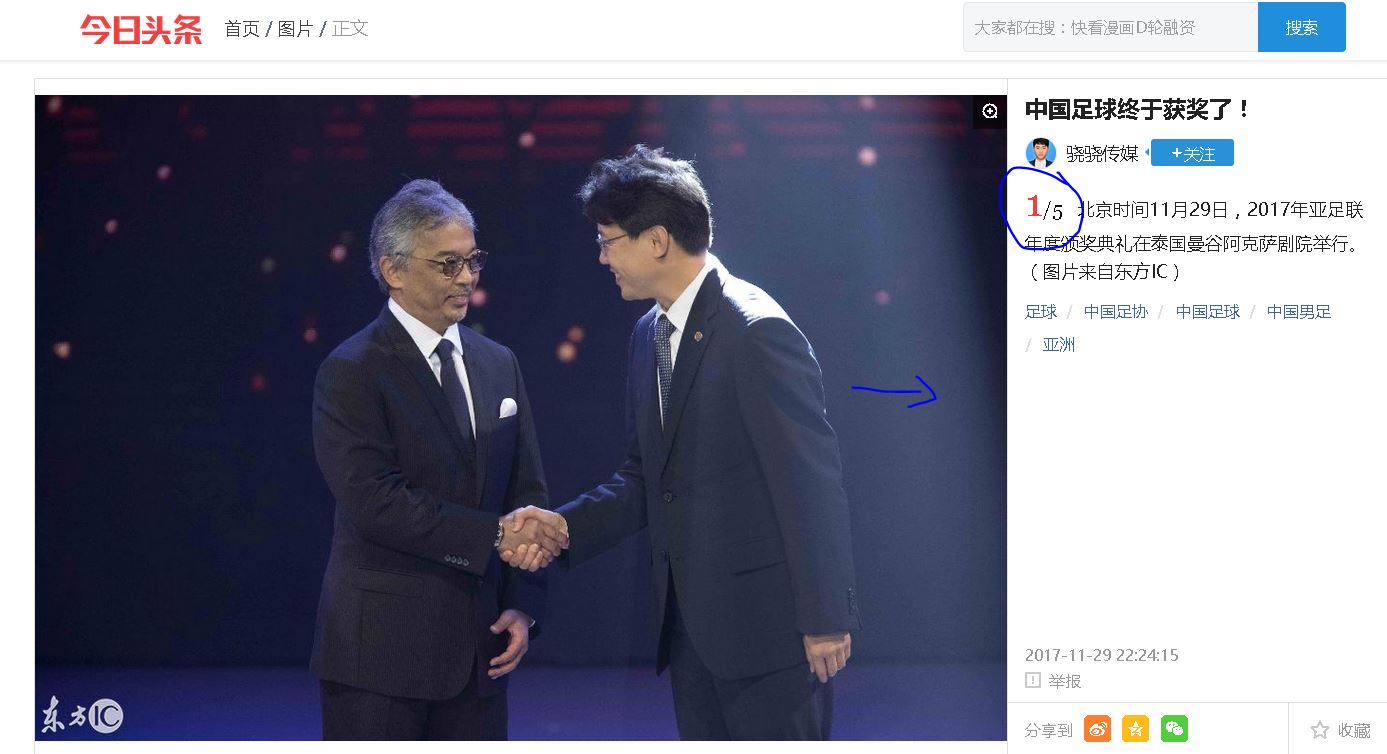
我们看上面的这个图片,右面的1/5可以看出,这个图集有5张图片,在图片上右侧点击的话,会打开下一张图片。
我们来看一下这些图片的url在哪里?
分析图集的源代码
【插入图片,图集页的XHR信息】

我们先看一下XHR,返回的仍然是一些json信息,但是每个json里面的内容都不是我们需要的图片的url。
而是一些评论、广告等信息。
那么这些图片的url在哪里呢?
我们再看一下HTML的源代码。
【插入图片,图集源代码】
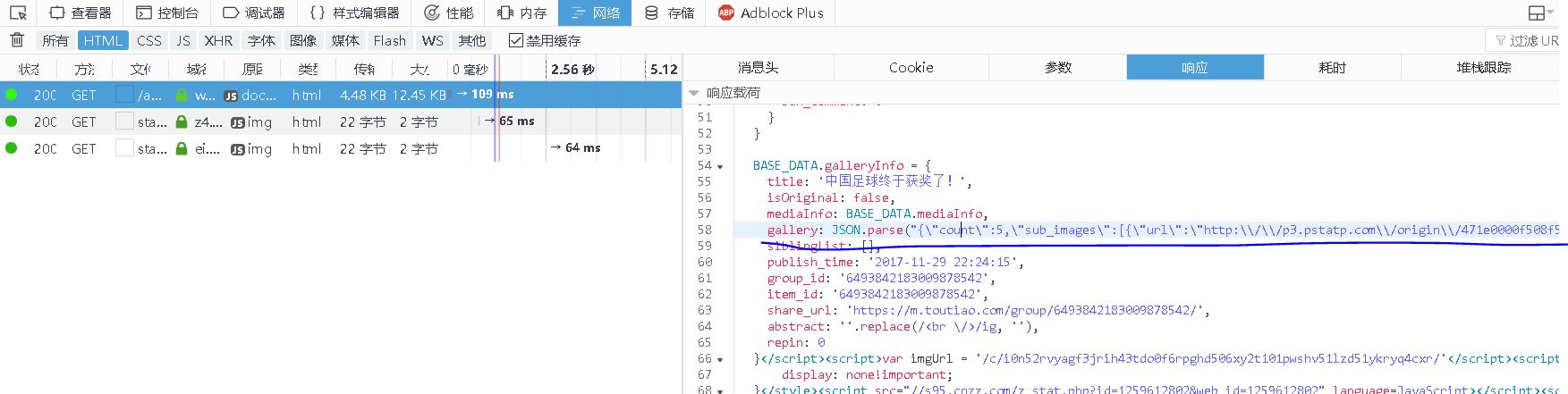
我们在响应内容中竟然发现了一个gallery,里面包含了5张图片的url。
既然在响应中可以找到内容,我们就可以使用requests的get方法来请求到这些响应,但是如何将每张图片的url提取出来?
从响应中提取URL
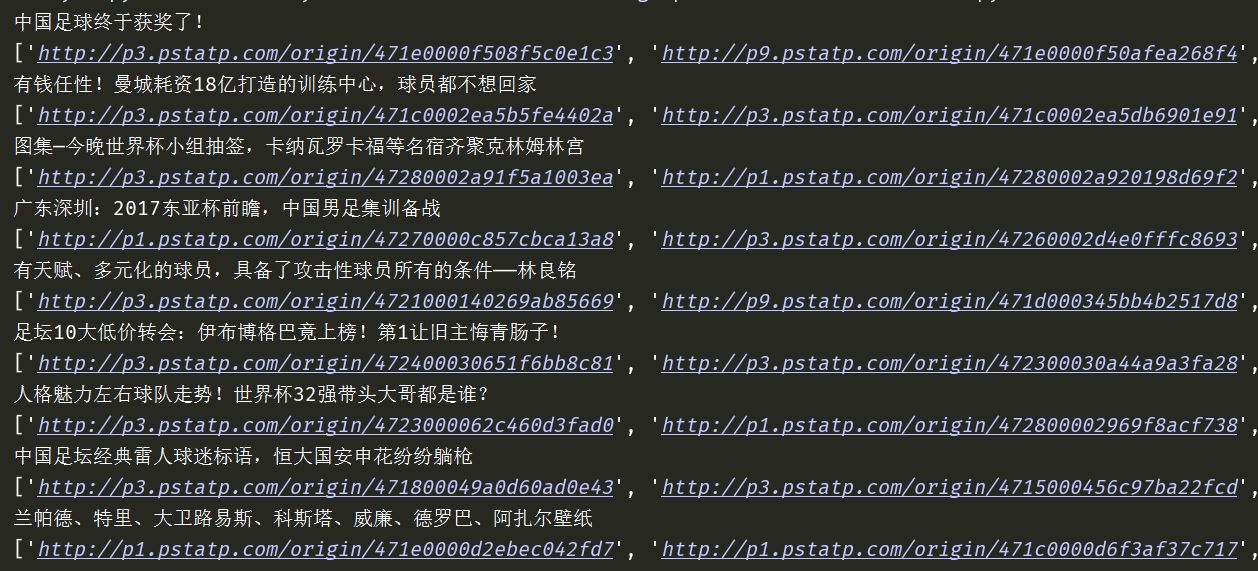
【插入图片,gallery内容】

我们仔细看一下,gallery里面,使用json.parse命令,将一个json字符串转换成了对象。里面包含了url信息,但是挺难提取出来。
尤其是在url中存在很多\,相信很多读者都搞不清楚了。我们简单讲解一下:
要匹配字符串中1个反斜杠\怎么写正则表达式?"\",这样可以吗?我们经过尝试,出现异常了。因为在正则表达式中,"\"就是一个反斜杠,对于正则表达式解析式来说,就是一个转义字符,后面啥匹配内容没有,自然报错。我们应该用四个反斜杠"\\"这样就可以了。
代码如下:
import re
re_str_patt = "\\"#这里指的是要匹配一个反斜杠
reObj = re.compile(re_str_patt)
str_test = "abc\cd\hh"#这里的意思是abc\cd\hh
print reObj.findall(str_test)
输出:['\', '\']
如果我们使用r,也就是原生字符串,举个例子;
import re
re_str_patt = r"\\"#匹配"\"
reObj = re.compile(re_str_patt)
str_test = "abc\cd\hh"#abc\cd\hh
print reObj.findall(str_test)
输出:[]#啥也没找到。
所以各位读者应该能感觉到,我还是想使用re正则来把url匹配出来的。
当然,图集的title我们也要获取,这时尝试用beautifulsoup来解析吧,省得忘记用法。
3、获取图集页的源代码
def get_page_detail(url):
try:
response = requests.get(url)
if response.status_code==200:
return response.text
else:
return None
except Exception:
print('请求索引页出错!')
return None
很简单,使用requests很容易就得到了源代码。
4、获取某个图集的所有图片url
def parse_page_detail(html):
soup=BeautifulSoup(html,'lxml')
title=soup.select('title')[0].get_text()
print(title)
images_pattern=re.compile(r'url\\":\\"(.*?)\\"}],\\"uri')#url\":\"(url)\"}],\uri
items=re.findall(images_pattern,html)
result=[]
for item in items:
new_item=''.join(item.split('\\'))#将匹配出来的字符串中的所有\都去除掉
#result.append(new_item)
http_pattern=re.compile(r'(http.*?)","width')#匹配所有正常的url地址
a_items=re.findall(http_pattern,new_item)
result.append(a_items[0])#取第一个url即可。
print(result)
return result
主要的难度在于解析上。上面的代码单纯看的话,很难懂,希望大家能动手尝试一下,看看每一步都输出什么样的结果。
这里就不展开讲解了。
5、运行
def main(offset):
html=get_page_index(offset)
for url in parse_page_index(html):
content=get_page_detail(url)
parse_page_detail(content)
if __name__=='__main__':
# p=Pool()
# p.map(main,[i*20 for i in range(3)])
for i in range(3):
main(i*20)
【插入图片,图片结果】
这次没有用多进程来操作,结果慢了很多。。。
昨天和今天的讲解,主要内容还是在于如何对Ajax加载的内容进行分析,如何获取json数据。图片的下载前面我们已经有过实战案例了,这里就不在重复写代码了。
希望大家有所收获。

爬虫实战【7】Ajax解析续-今日头条图片下载的更多相关文章
- 爬虫—分析Ajax爬取今日头条图片
以今日头条为例分析Ajax请求抓取网页数据.本次抓取今日头条的街拍关键字对应的图片,并保存到本地 一,分析 打开今日头条主页,在搜索框中输入街拍二字,打开开发者工具,发现浏览器显示的数据不在其源码里面 ...
- 用Ajax爬取今日头条图片集
Ajax原理 在用requests抓取页面时,得到的结果可能和浏览器中看到的不一样:在浏览器中可以正常显示的页面数据,但用requests得到的结果并没有.这是因为requests获取的都是原始 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 分析Ajax爬取今日头条街拍美图-崔庆才思路
站点分析 源码及遇到的问题 代码结构 方法定义 需要的常量 关于在代码中遇到的问题 01. 数据库连接 02.今日头条的反爬虫机制 03. json解码遇到的问题 04. 关于response.tex ...
- 分析AJAX抓取今日头条的街拍美图并把信息存入mongodb中
今天学习分析ajax 请求,现把学得记录, 把我们在今日头条搜索街拍美图的时候,今日头条会发起ajax请求去请求图片,所以我们在网页源码中不能找到图片的url,但是今日头条网页中有一个json 文件, ...
- 关于爬虫的日常复习(9)—— 实战:分析Ajax抓取今日头条接拍美图
- Python网络爬虫实战(二)数据解析
上一篇说完了如何爬取一个网页,以及爬取中可能遇到的几个问题.那么接下来我们就需要对已经爬取下来的网页进行解析,从中提取出我们想要的数据. 根据爬取下来的数据,我们需要写不同的解析方式,最常见的一般都是 ...
随机推荐
- ODOO Unable To Find Wkhtmltopdf On This System. Error/Bug ?
If you are using ODOO version 8 and getting some error like – Unable to find Wkhtmltopdf on this sys ...
- [1-4] 把时间当做朋友(李笑来)Chapter 4 【开拓我们的心智】 摘录
1. 获得知识的基本途径 所有的人获取知识的最为基础的手段就是“体验”. 比“体验”再高级一点的获取知识的手段,就是“试错”(Trial and Error). 在“试错”这个手段的基础上,另外一个 ...
- unity, iOS下画面错乱解法
unity版本号为5.1.1f1 Personal 在ipod5,系统为iOS7.1上测试.发现下面两种出现画面错乱的问题: 一,退后台在返回前台时画面发生错乱(错乱持续一两秒,然后变为正常). ...
- centos/rhel下实现nginx自启动脚本实例
1. 建立脚本文件nginxd [root@could]# vi /etc/init.d/nginxd 插入以下内容 #!/bin/bash # # chkconfig: - 85 15 # de ...
- iOS-Gif图片展示N种方式(原生+第三方)
原生方法: 1.UIWebView 特点:载入速度略长,性能更优.播放的gif动态图更加流畅. //动态展示GIF图片-WebView -(void)showGifImageWithWebView{ ...
- Atitit. Async await 优缺点 异步编程的原理and实现 java c# php
Atitit. Async await 优缺点 异步编程的原理and实现 java c# php 1. async & await的来源1 2. 异步编程history1 2.1. 线程池 2 ...
- UVA 11014 - Make a Crystal(容斥原理)
UVA 11014 - Make a Crystal 题目链接 题意:给定一个NxNxN的正方体,求出最多能选几个整数点.使得随意两点PQ不会使PQO共线. 思路:利用容斥原理,设f(k)为点(x, ...
- linux学习之vimrc配置推荐
,gb2312,gbk,gb18030,big5 "去掉vi一致性 set nocompatible ""设置行号 set number "打开文件类型自动检测 ...
- Python内置函数之bytes()
该函数是一个类对象: class bytes([source[,encoding[,errors]]]) 返回值为字节对象,当第一个参数为字符串时,必须提供第二个参数,第二个参数为编码类型的字符串. ...
- random实现验证码功能
直接上代码: #-*- coding: utf-8 -*- #一个简单的验证码程序 import random #定义一个全局变量,初始值为空字符串 checkcode = '' for i in r ...