Beautiful用法总结








Beautiful用法总结的更多相关文章
- Python之Beautiful Soup的用法
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- python beautiful soup库的超详细用法
原文地址https://blog.csdn.net/love666666shen/article/details/77512353 参考文章https://cuiqingcai.com/1319.ht ...
- python爬虫(7)--Beautiful Soup的用法
1.Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据. Beautiful Soup提供一些简单的.python式的函数用来 ...
- Beautiful Soup库基础用法(爬虫)
初识Beautiful Soup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/# 中文文档:https://www.crumm ...
- Beautiful Soup的用法
BEAUTIFUL SOUP的介绍 就是一个非常好用.漂亮.牛逼的第三方库,是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree). 它提供简 ...
- python 爬虫5 Beautiful Soup的用法
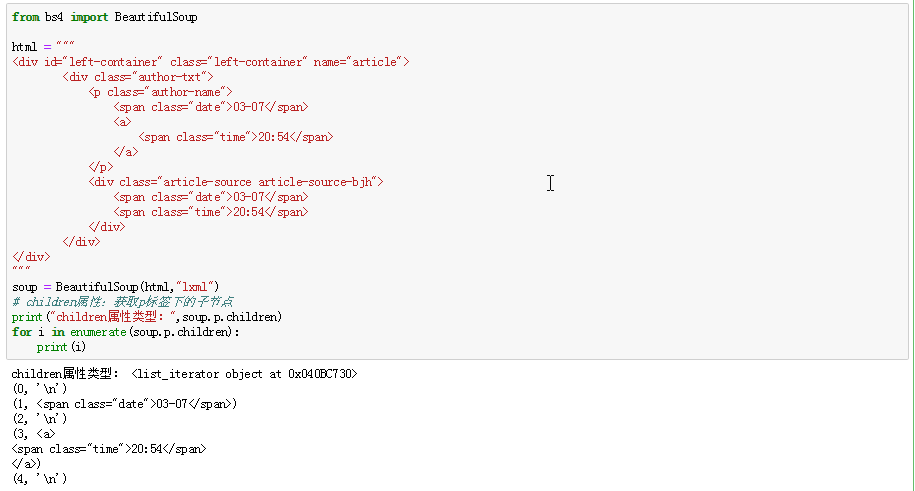
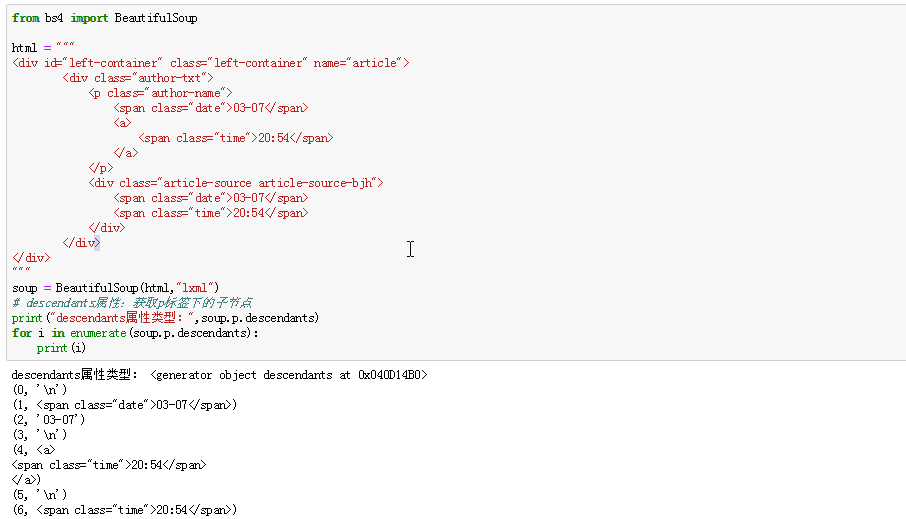
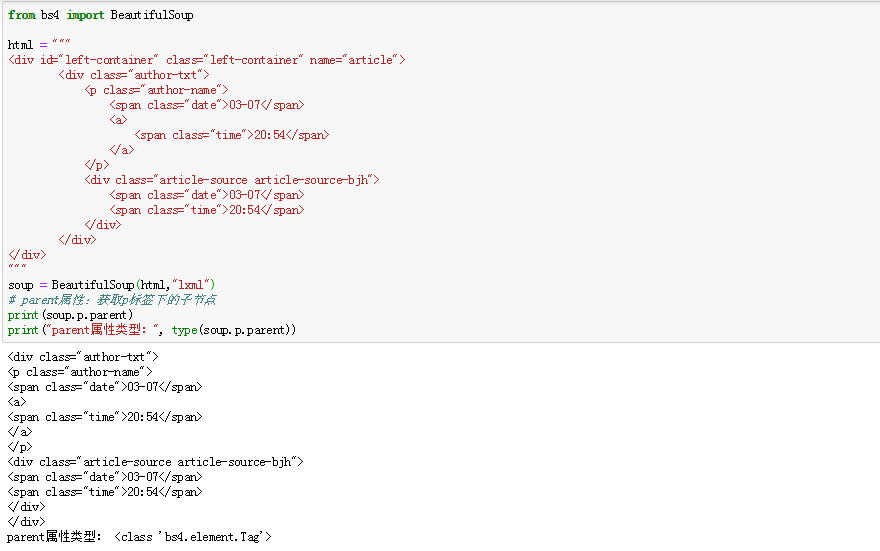
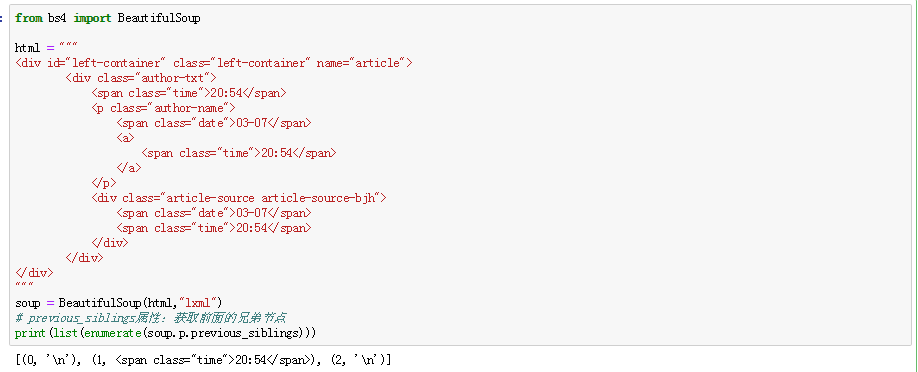
1.创建 Beautiful Soup 对象 from bs4 import BeautifulSoup html = """ <html><head& ...
- Python爬虫利器之Beautiful Soup,Requests,正则的用法(转)
https://cuiqingcai.com/1319.html https://cuiqingcai.com/2556.html https://cuiqingcai.com/977.html
- Beautiful Soup的用法(五):select的使用
原文地址:http://www.bugingcode.com/blog/beautiful_soup_select.html select 的功能跟find和find_all 一样用来选取特定的标签, ...
随机推荐
- idea 转载
转载:https://blog.csdn.net/qq_34033853/article/details/77448431 摘要:在创建类时,自动生成代码的注释模板 本篇内容为大家提供的是Intell ...
- IntelliJ IDEA中Mapper接口通过@Autowired注入报错的正确解决方式
转载请注明来源:四个空格 » IntelliJ IDEA中Mapper接口通过@Autowired注入报错的正确解决方式: 环境 ideaIU-2018.3.4.win: 错误提示: Could no ...
- Making every developer more productive with Visual Studio 2019
Today, in the Microsoft Connect(); 2018 keynote, Scott Guthrie announced the availability of Visual ...
- Windows 上连接本地 Linux虚拟机上的 mysql 数据库
查看本机ip ifconfig 查看当前的 3306 端口状态 netstat -an|grep 3306 当前是外部无法连接状态 修改访问权限 默认的 mysql 是只能本机连接, 因此需要修改配 ...
- THUWC2019滚粗记
Day-1 今年年初,留坑,以后补,多多关注. Day0 上午吃了碗粉,就坐地铁到了高铁站. 做高铁从长沙到了广州,最大的感受就是热热热热热热热热. 所以太热了不说了.(雾 汉堡王真香 Day1 上午 ...
- 清北学堂4.28Day1(重大更新详见贪心例一)
枚举 用题目中给定的检验条件判定哪些是无用的,哪些是有用 的.能使命题成立的即为其解 . 例一 一棵苹果树上有n个苹果,每个苹果长在高度为Ai的地方.小明的身高为x 他想知道他最多能摘到多少苹果 数据 ...
- Ceph rdb
Ceph 独一无二地用统一的系统提供了对象.块.和文件存储功能,它可靠性高.管理简便.并且是自由软件. Ceph 的强大足以改变公司的 IT 基础架构.和管理海量数据. Ceph 可提供极大的伸缩性— ...
- 各类聚类(clustering)算法初探
1. 聚类简介 0x1:聚类是什么? 聚类是一种运用广泛的探索性数据分析技术,人们对数据产生的第一直觉往往是通过对数据进行有意义的分组.很自然,首先要弄清楚聚类是什么? 直观上讲,聚类是将对象进行分组 ...
- Hbase-site.xml
生产环境基于 HA HDFS 的Hbase 基本优化后配置(无安全版本) hbase.rest.port 60050 hbase.cluster.distributed true hbase.root ...
- HDU 2717(* bfs)
题意是在一个数轴上,每次可以一步到达当前位置数值的 2 倍的位置或者数值 +1 或数值 -1 的位置,给定 n 和 k,问从数值为 n 的位置最少多少步可以到达数值为 k 的位置. 用广搜的方法,把已 ...