Beautiful用法总结





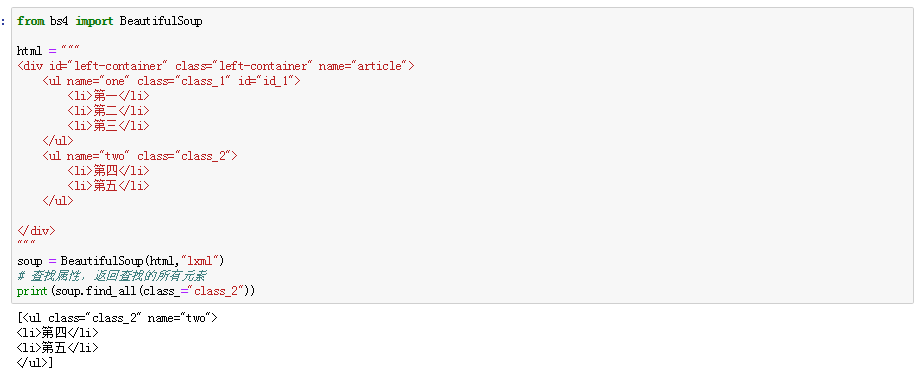
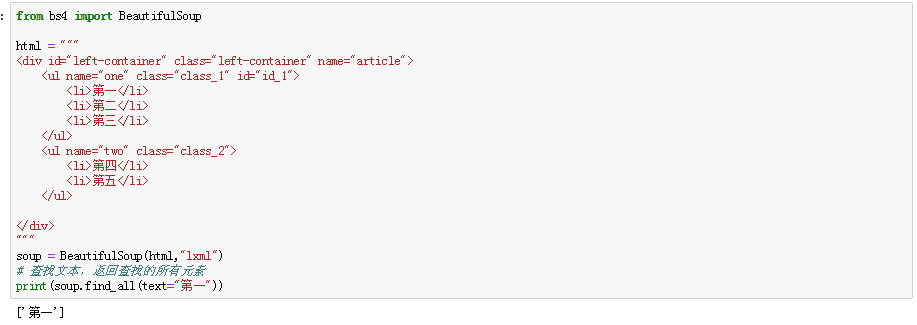



Beautiful用法总结的更多相关文章
- Python之Beautiful Soup的用法
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- python beautiful soup库的超详细用法
原文地址https://blog.csdn.net/love666666shen/article/details/77512353 参考文章https://cuiqingcai.com/1319.ht ...
- python爬虫(7)--Beautiful Soup的用法
1.Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据. Beautiful Soup提供一些简单的.python式的函数用来 ...
- Beautiful Soup库基础用法(爬虫)
初识Beautiful Soup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/# 中文文档:https://www.crumm ...
- Beautiful Soup的用法
BEAUTIFUL SOUP的介绍 就是一个非常好用.漂亮.牛逼的第三方库,是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree). 它提供简 ...
- python 爬虫5 Beautiful Soup的用法
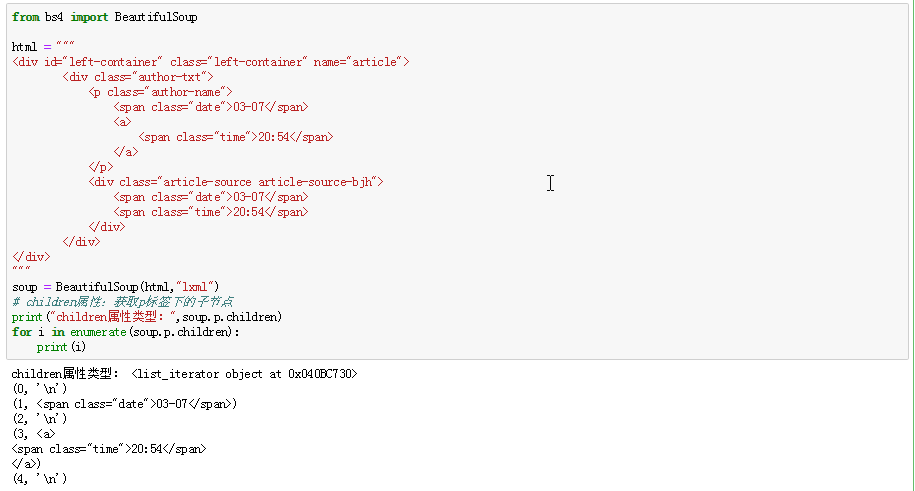
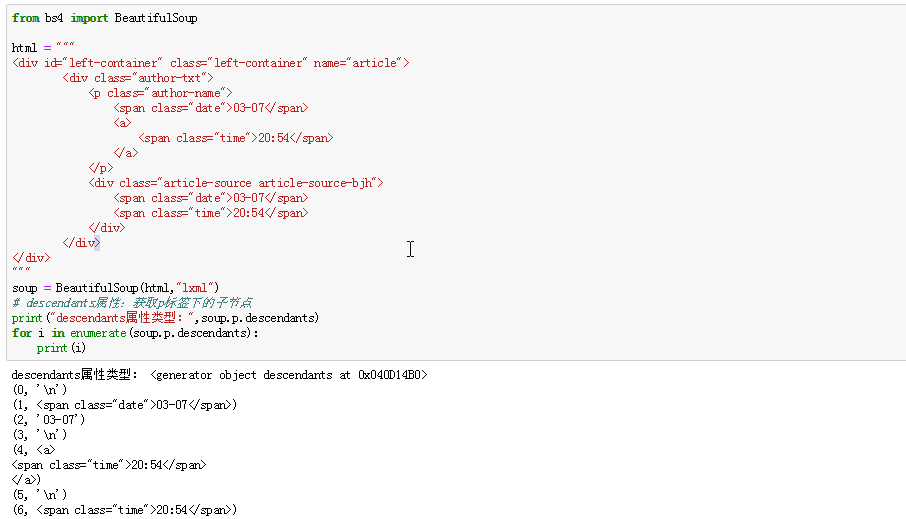
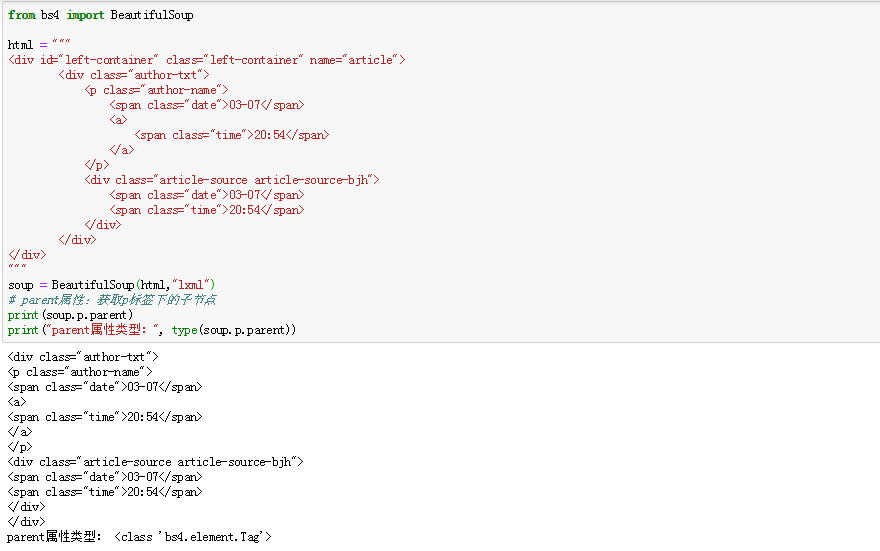
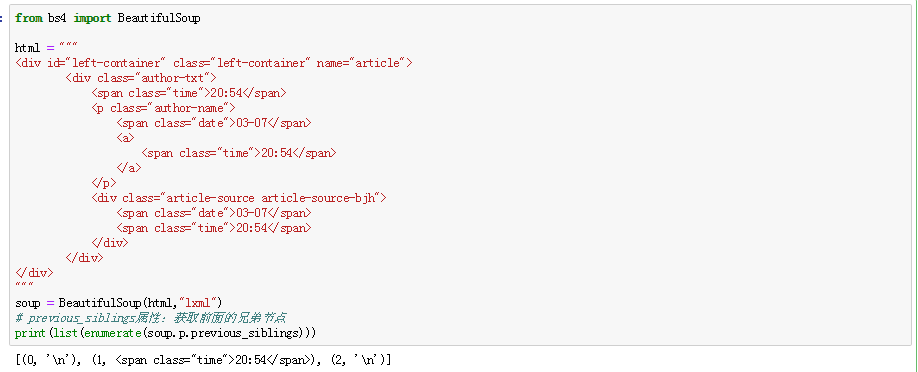
1.创建 Beautiful Soup 对象 from bs4 import BeautifulSoup html = """ <html><head& ...
- Python爬虫利器之Beautiful Soup,Requests,正则的用法(转)
https://cuiqingcai.com/1319.html https://cuiqingcai.com/2556.html https://cuiqingcai.com/977.html
- Beautiful Soup的用法(五):select的使用
原文地址:http://www.bugingcode.com/blog/beautiful_soup_select.html select 的功能跟find和find_all 一样用来选取特定的标签, ...
随机推荐
- delphi7 编译的程序在win7下请求获得管理员权限的方法
网上找到的,记下来方便查找,亲测此方法可用.附带把编译好的uac.res上传. 首先,用记事本新建一文本文档,内容如下: 1 24 UAC.manifest 然后另存为uac.rc 另外新建一文本档, ...
- JDK 新特性
Jdk8新特性 一:接口默认方法和静态方法: 我们可以在接口中定义默认方法,使用default关键字,并提供默认的实现.所有实现这个接口的类都会接受默认方法的实现,除非子类提供的自己的实现. 我们还可 ...
- HTML一
什么是前端: 前端,也称web前端对于网站来说,通常是指网站的前台部分,通俗点就是用户可以看到的部分, 浏览器.APP.应用程序的界面展现和用户交互就是前端 前端要学习那些技术:html+css+ja ...
- Mint-UI Picker 三级联动
Mint-UI Picker组件的三级联动 HTML: <mt-picker :slots="slots" value-key="name" @chang ...
- [leetcode] 5.Longest Palindromic Substring-1
开始觉得挺简单的 写完发现这个时间超限了: class Solution: def longestPalindrome(self, s: str) -> str: # longest palin ...
- 洛谷P2179 骑行川藏
什么毒瘤... 解:n = 1的,发现就是一个二次函数,解出来一个v的取值范围,选最大的即可. n = 2的,猜测可以三分.于是先二分给第一段路多少能量,然后用上面的方法求第二段路的最短时间.注意剩余 ...
- Css(常用的特殊效果)
一.前言 不得不说css真强大,总结了几个常用的css特殊效果 二.主要内容 1.几个特殊效果 $green = #02a774; $yellow = #F5A100; $bc = #e4e4e4; ...
- 贝叶斯A/B测试 - 一种计算两种概率分布差异性的方法过程
1. 控制变量 0x1:控制变量主要思想 科学中对于多因素(多变量)的问题,常常采用控制因素(变量)的方法,吧多因素的问题变成多个单因素的问题.每一次只改变其中的某一个因素,而控制其余几个因素不变,从 ...
- SpringCloud笔记七:Zuul
目录 什么是Zull 为什么需要Zuul 新建Zuul项目 运行Zuul Zuul的基本配置 忽略微服务的真实名称 设置统一公共前缀 总结 什么是Zull Zuul就是一个网关,实现的功能:代理.路由 ...
- 08--STL关联容器(set/multiset)
一:set/multiset的简介 set是一个集合容器,其中所包含的元素是唯一的,集合中的元素按一定的顺序排列.元素插入过程是按排序规则插入,所以不能指定插入位置. set采用红黑树变体的数据结构实 ...