【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述
根据好友列表,推荐好友的好友

数据集
tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive cat hadoop world hello mr hadoop tom hive world hello tom world hive mr
代码
MyFOF.class
package com.hadoop.mr.fof;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyFOF {
public static void main(String[] args) {
try {
//Conf
Configuration conf = new Configuration(true);
Job job = Job.getInstance(conf);
job.setJarByClass(MyFOF.class);
//Map
job.setMapperClass(FMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//Reduce
job.setReducerClass(FReducer.class);
//Input&Output
Path in = new Path("/user/hadoop/input/friends.txt");
FileInputFormat.addInputPath(job, in);
Path out = new Path("/user/hadoop/output/friends/");
if(out.getFileSystem(conf).exists(out)){
out.getFileSystem(conf).delete(out,true);
}
FileOutputFormat.setOutputPath(job, out);
//Submit
job.waitForCompletion(true);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
FMapper.class
package com.hadoop.mr.fof;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
public class FMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text mkey = new Text();
IntWritable mval = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//tom hello hadoop cat
String [] strs = StringUtils.split(value.toString(),' ');
/*
* 找直接、间接关系
* value: 0-直接关系;1-间接关系
* 直接关系:tom:hello tom:hadoop tom:cat
* 间接关系:hello:hadoop hello:cat hadoop:cat
*/
for(int i=1;i<strs.length;i++){
//与好友清单中的好友为直接关系
mkey.set(getFof(strs[0], strs[i]));
mval.set(0);
context.write(mkey, mval);
//在好友列表内 好友之间为间接关系
for(int j = i+1;j < strs.length;j++){
mkey.set(getFof(strs[i],strs[j]));
mval.set(1);
context.write(mkey, mval);
}
}
}
//按字典序进行字符串拼接
public static String getFof(String s1,String s2){
if(s1.compareTo(s2) < 0){
return s1+":"+s2;
}
return s2+":"+s1;
}
}
FReducer.class
package com.hadoop.mr.fof;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FReducer extends Reducer<Text,IntWritable, Text, IntWritable> {
IntWritable rval = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
/*
* 数据如下:
* hello:hadoop 0
* hello:hadoop 1
*/
int flg = 0; //标志
int sum = 0; //共同好友总数
for(IntWritable v :values){
if(v.get() == 0){
flg = 1;
}
sum += v.get();
}
if(flg == 0){
rval.set(sum);
context.write(key, rval);
}
}
}
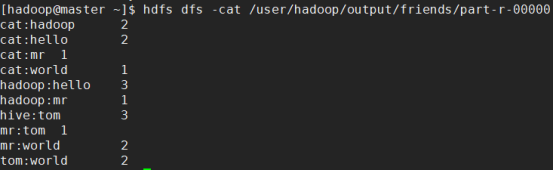
运行结果
本次案例只是处理了两个人之间共同好友的数量。
【尚学堂·Hadoop学习】MapReduce案例2--好友推荐的更多相关文章
- 【尚学堂·Hadoop学习】MapReduce案例1--天气
案例描述 找出每个月气温最高的2天 数据集 -- :: 34c -- :: 38c -- :: 36c -- :: 32c -- :: 37c -- :: 23c -- :: 41c -- :: 27 ...
- 尚学堂xml学习笔记
1.打开eclipse,文件-新建java project,输入文件的名字,比如输入20181112. 2.对着src右键,选择new-file,输入文件名字,比如:book.xml. 3.开始写.x ...
- 大数据学习——mapreduce案例join算法
需求: 用mapreduce实现select order.orderid,order.pdtid,pdts.pdt_name,oder.amount from orderjoin pdtson ord ...
- 尚学堂 hadoop
mr spark storm 都是分布式计算框架,他们之间不是谁替换谁的问题,是谁适合做什么的问题. mr特点,移动计算,而不移动数据. 把我们的计算程序下发到不同的机器上面运行,但是不移动数据. 每 ...
- 尚学堂JAVA基础学习笔记
目录 尚学堂JAVA基础学习笔记 写在前面 第1章 JAVA入门 第2章 数据类型和运算符 第3章 控制语句 第4章 Java面向对象基础 1. 面向对象基础 2. 面向对象的内存分析 3. 构造方法 ...
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 学习java的视频资源(尚学堂)(比较老旧,但是还是挺好用)
本人新手,转入IT,一开始在学校的时候看过尚学堂 马士兵讲过的java基础视频教程,这次深入学习呢,就从百度云盘找了一整套的视频资源.之后越深入的学习呢,发现这些视频资源VeryCD上都发布了,地址 ...
随机推荐
- python接口自动化-Cookie_绕过验证码登录
前言 有些登录的接口会有验证码,例如:短信验证码,图形验证码等,这种登录的验证码参数可以从后台获取(或者最直接的可查数据库) 获取不到也没关系,可以通过添加Cookie的方式绕过验证码 前面在“pyt ...
- gdb cheat sheet
0x01 控制流 r run,运行程序. r < a.txt run,重定向输入 si step instruction 进入函数 ni next instruction 下一 ...
- 禁止Cnario Player启动后自动开始播放
Cnario Player安装激活后, 默认开机后自动启动, 启动加载内容完成后进入10秒倒计时, 10秒后即开始播放关机前播放的内容. 如果不想让其自动开始播放, 可按照如下办法设置其不自动播放. ...
- codeforces 792A-D
先刷前四题,剩下的有空补. 792A New Bus Route 题意:给出x 轴上的n 个点,问两个点之间的最短距离是多少,有多少个最短距离. 思路:排序后遍历. 代码: #include<s ...
- ABP中的Filter(下)
接着上面的一个部分来叙述,这一篇我们来重点看ABP中的AbpUowActionFilter.AbpExceptionFilter.AbpResultFilter这三个部分也是按照之前的思路来一个个介绍 ...
- windows编程 进程的创建销毁和分析
Windows程序设计:进程 进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动,在Windows编程环境下,主要由两大元素组成: • 一个是操作系统用来管理进程的内核对象.操作系统使用内 ...
- 最长公共子序列(POJ1458)
给出两个字符串,求出这样的一个最长的公共子序列的长度:子序列中的每个字符都能在两个原串中找到,而且每个字符的先后顺序和原串中的先后顺序一致. Sample Input: abcfbc abfcabpr ...
- 【NLP】BLEU值满分是100分吗?
为了解决这个问题,首先需要知道BLEU值是如何计算出来的. BLEU全称是Bilingual Evaulation Understudy.其意思是双语评估替补.所谓Understudy(替补),意思是 ...
- MVC autofac 属性注入
Global文件 public class MvcApplication : System.Web.HttpApplication { private static IContainer Contai ...
- java网页爬数据获取class中的空格
<ul class=""> <li class="avatar_img"><img src="http://avatar ...