python登录网易163邮箱,爬取邮件
from common import MyRequests,LoggerUntil,handle_exception
myRequests.update_headers({ 'Accept':'text/javascript',}) ##这个地方加入accept了,主要是在邮件提取那里,不加入这个返回的是xml格式,加入后返回json格式,这样在提取方面更容易一些。
url = 'https://mail.163.com/entry/cgi/ntesdoor?funcid=loginone&language=-1&passtype=1&iframe=1&product=mail163&from=web&df=email163&race=-2_262_-2_hz&module=&uid={0}&style=-1&net=t&skinid=null'.format('13148804507@163.com')
datax = {
'username':'13148804507@167.com',
'url2':'http://email.163.com/errorpage/error163.htm',
'savalogin':'',
'password':'123456789abcd',
}
text= myRequests.post(url,data = datax)
#到这一步已经登录ok了,可以打印cookie看看就能知道了。
抓取邮件,
请求完成后,打印text 得到
<html><head><script type="text/javascript">top.location.href = "http://mail.163.com/js6/main.jsp?sid=iCApYbICzSWVFIFqHTCCdtntXqDYrVhB&df=email163";</script></head><body></body></html>
sid =re.search('sid=(.*?)&',resp.text).group(1) #使用正则把sid取出来
url = 'http://mail.163.com/js6/s?sid={sid}&func=mbox:listMessages&LeftNavfolder1Click=1&mbox_folder_enter=1'.format(sid=sid)
datax = {'var':'<?xml version="1.0"?><object><int name="fid">1</int><string name="order">date</string><boolean name="desc">true</boolean><int name="limit">20</int><int name="start">0</int><boolean name="skipLockedFolders">false</boolean><string name="topFlag">top</string><boolean name="returnTag">true</boolean><boolean name="returnTotal">true</boolean></object>'}
print myRequests.post(url, data=datax)
#这样就打印出所有邮件了。然后筛选邮件,找出与信用卡相关的邮件,做征信风控用。
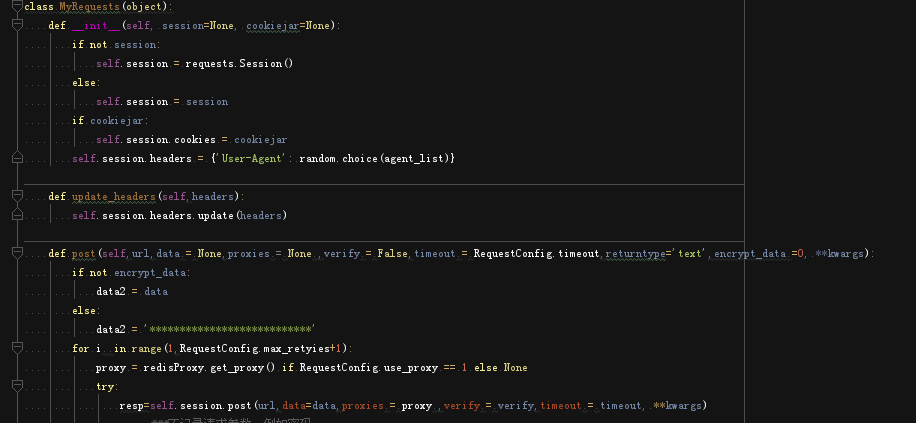
其中myrequests是从MyRequests类实例化的,因为经常要进行网络请求,所以里面封装了 请求 重试 日志打印 异常处理 下载验证码 验证码重命名 cookiejar和cookie dict的相互转换 更新headers 网页编码格式处理 和内容检查这些实例方法或者静态方法。读者可以自己用requests的session类来代替我这个。 MyRequests大概就是这样。
然后还要鄙视一下有的人,他做好了这个163登录,叫他发出来,我已经表示愿意掏100元作为报酬,他居然想讹诈1000元。那就让他发霉吧,如果是一个新东西,你没做过给更多的钱,这还差不多,自己做好了不分享还不是发霉。
本人分享这个方法,简单直接,登录只用请求一次。今天是2017年11月8日,可以用这登录163邮箱,给怕过期的网友说明下代码的时间。
重点说明一下,我这使用的是email163.com登录的。
不是使用mail163.com登陆的,一定要注意这个,千万不要用这个mail163.com登录,弄了好几个小时还没登陆上,加上有网易网盾验证码。
python登录网易163邮箱,爬取邮件的更多相关文章
- python实现人人网用户数据爬取及简单分析
这是之前做的一个小项目.这几天刚好整理了一些相关资料,顺便就在这里做一个梳理啦~ 简单来说这个项目实现了,登录人人网并爬取用户数据.并对用户数据进行分析挖掘,终于效果例如以下:1.存储人人网用户数据( ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
[学习笔记]Python 3.6模拟输入并爬取百度前10页密切相关链接 问题描述 通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接. me ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- HTTP 响应头信息(Http Response Header) Content-Length 和 Transfer-Encoding
Tomcat 中响应头信息(Http Response Header) Content-Length 和 Transfer-Encoding 客户端(PC浏览器或者手机浏览器)在接受到Tomcat的响 ...
- linux 安装 vsftpd服务
yum install vsftpd 修改配置文件 vim /etc/vsftpd/ftpusers vim /etc/vsftpd/user_list 简单起见,注释掉两个配置文件中的所有用户.
- 在springmvc中无法使用@value()注解
折腾了一下午,试了很多解决办法,就是死活不能扫描到properties文件.本来打算使用软编码的,尝试更改了全部jar包版本,还是无法解决. 后面想到了,spring和springmvc容器的加载顺序 ...
- DFS-深度优先遍历
#include <iostream> /* 5 4 0 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 1 0 0 4 1 Total: 9 7 5 Min: 5 ...
- Struts2技术详解
1, 当Action设置了某个属性后,Struts将这些属性封装一个叫做Struts.valueStack的属性里.获取valueStack对象: ValueStack vs = (ValueStac ...
- 在R中运行Shell命令脚本(Call shell commands from R)
aaa.R Args <- commandArgs()cat("Args[1]=",Args[1],"\n")cat("Args[2]=&quo ...
- 产品需求文档 PRD
第一轮: 1,文档使用方:UI设计师 2.内容: 根据战略层定义出来产品功能范围, 说明此产品的目的,方便UI设计人员更好的理解产品 产品基本流程 详细 ...
- 自定义python web框架
-- Bootstrap http://www.bootcss.com/ -- Font Awesome http://fontawesome.io/ -- bxslider http://bxsli ...
- Numpy 的通用函数:快速的元素级数组函数
通用函数: 通用函数(ufunc)是一种对ndarray中的数据执行元素级运算的函数.你可以将其看作简单函数(接受一个或多个标量值,并产生一个或度过标量值)的矢量化包装器. 简单的元素级变体,如sqr ...
- (笔记)Linux下C语言实现静态IP地址,掩码,网关的设置
#include <sys/ioctl.h> #include <sys/types.h> #include <sys/socket.h> #include < ...