神经网络优化篇:详解正则化(Regularization)
正则化
深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据,这是非常可靠的方法,但可能无法时时刻刻准备足够多的训练数据或者获取更多数据的成本很高,但正则化通常有助于避免过拟合或减少的网络误差。
如果怀疑神经网络过度拟合了数据,即存在高方差问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,这也是非常可靠的办法,但可能无法时时准备足够多的训练数据,或者,获取更多数据的成本很高,但正则化有助于避免过度拟合,或者减少网络误差,下面就来讲讲正则化的作用原理。
用逻辑回归来实现这些设想,求成本函数\(J\)的最小值,它是定义的成本函数,参数包含一些训练数据和不同数据中个体预测的损失,\(w\)和\(b\)是逻辑回归的两个参数,\(w\)是一个多维度参数矢量,\(b\)是一个实数。在逻辑回归函数中加入正则化,只需添加参数λ,也就是正则化参数。
\(\frac{\lambda}{2m}\)乘以\(w\)范数的平方,其中\(\left\| w \right\|_2^2\)是\(w\)的欧几里德范数的平方,等于\(w_{j}\)(\(j\) 值从1到\(n_{x}\))平方的和,也可表示为\(w^{T}w\),也就是向量参数\(w\) 的欧几里德范数(2范数)的平方,此方法称为\(L2\)正则化,因为这里用了欧几里德范数,被称为向量参数\(w\)的\(L2\)范数。
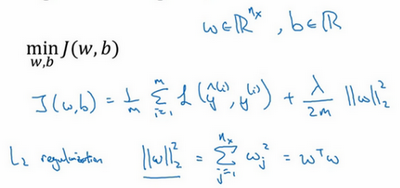
为什么只正则化参数\(w\)?为什么不再加上参数 \(b\) 呢?可以这么做,只是习惯省略不写,因为\(w\)通常是一个高维参数矢量,已经可以表达高偏差问题,\(w\)可能包含有很多参数,不可能拟合所有参数,而\(b\)只是单个数字,所以\(w\)几乎涵盖所有参数,而不是\(b\),如果加了参数\(b\),其实也没太大影响,因为\(b\)只是众多参数中的一个,所以通常省略不计,如果想加上这个参数,完全没问题。

\(L2\)正则化是最常见的正则化类型,们可能听说过\(L1\)正则化,\(L1\)正则化,加的不是\(L2\)范数,而是正则项\(\frac{\lambda}{m}\)乘以\(\sum_{j= 1}^{n_{x}}{|w|}\),\(\sum_{j =1}^{n_{x}}{|w|}\)也被称为参数\(w\)向量的\(L1\)范数,无论分母是\(m\)还是\(2m\),它都是一个比例常量。
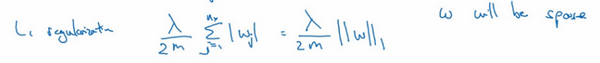
如果用的是\(L1\)正则化,\(w\)最终会是稀疏的,也就是说\(w\)向量中有很多0,有人说这样有利于压缩模型,因为集合中参数均为0,存储模型所占用的内存更少。实际上,虽然\(L1\)正则化使模型变得稀疏,却没有降低太多存储内存,所以认为这并不是\(L1\)正则化的目的,至少不是为了压缩模型,人们在训练网络时,越来越倾向于使用\(L2\)正则化。
来看最后一个细节,\(\lambda\)是正则化参数,通常使用验证集或交叉验证集来配置这个参数,尝试各种各样的数据,寻找最好的参数,要考虑训练集之间的权衡,把参数设置为较小值,这样可以避免过拟合,所以λ是另外一个需要调整的超级参数,顺便说一下,为了方便写代码,在Python编程语言中,\(\lambda\)是一个保留字段,编写代码时,删掉\(a\),写成\(lambd\),以免与Python中的保留字段冲突,这就是在逻辑回归函数中实现\(L2\)正则化的过程,如何在神经网络中实现\(L2\)正则化呢?

神经网络含有一个成本函数,该函数包含\(W^{[1]}\),\(b^{[1]}\)到\(W^{[l]}\),\(b^{[l]}\)所有参数,字母\(L\)是神经网络所含的层数,因此成本函数等于\(m\)个训练样本损失函数的总和乘以\(\frac{1}{m}\),正则项为\(\frac{\lambda }{2m}{{\sum\nolimits_{1}^{L}{| {{W}^{[l]}}|}}^{2}}\),称\({||W^{\left[l\right]}||}^{2}\)为范数平方,这个矩阵范数\({||W^{\left[l\right]}||}^{2}\)(即平方范数),被定义为矩阵中所有元素的平方求和,

看下求和公式的具体参数,第一个求和符号其值\(i\)从1到\(n^{[l - 1]}\),第二个其\(J\)值从1到\(n^{[l]}\),因为\(W\)是一个\(n^{[l]}\times n^{[l-1]}\)的多维矩阵,\(n^{[l]}\)表示\(l\) 层单元的数量,\(n^{[l-1]}\)表示第\(l-1\)层隐藏单元的数量。

该矩阵范数被称作“弗罗贝尼乌斯范数”,用下标\(F\)标注”,鉴于线性代数中一些神秘晦涩的原因,不称之为“矩阵\(L2\)范数”,而称它为“弗罗贝尼乌斯范数”,矩阵\(L2\)范数听起来更自然,但鉴于一些大家无须知道的特殊原因,按照惯例,称之为“弗罗贝尼乌斯范数”,它表示一个矩阵中所有元素的平方和。

该如何使用该范数实现梯度下降呢?
用backprop计算出\(dW\)的值,backprop会给出\(J\)对\(W\)的偏导数,实际上是$ W{[l]}$,把$W\(替换为\)W^{[l]}\(减去学习率乘以\)dW$。

这就是之前额外增加的正则化项,既然已经增加了这个正则项,现在要做的就是给\(dW\)加上这一项\(\frac {\lambda}{m}W^{[l]}\),然后计算这个更新项,使用新定义的\(dW^{[l]}\),它的定义含有相关参数代价函数导数和,以及最后添加的额外正则项,这也是\(L2\)正则化有时被称为“权重衰减”的原因。

用$ dW{[l]}$的定义替换此处的$dW\(,可以看到,\)W{[l]}$的定义被更新为$W\(减去学习率\)\alpha$ 乘以backprop 再加上\(\frac{\lambda}{m}W^{[l]}\)。

该正则项说明,不论\(W^{[l]}\)是什么,都试图让它变得更小,实际上,相当于给矩阵W乘以\((1 - \alpha\frac{\lambda}{m})\)倍的权重,矩阵\(W\)减去\(\alpha\frac{\lambda}{m}\)倍的它,也就是用这个系数\((1-\alpha\frac{\lambda}{m})\)乘以矩阵\(W\),该系数小于1,因此\(L2\)范数正则化也被称为“权重衰减”,因为它就像一般的梯度下降,\(W\)被更新为少了\(\alpha\)乘以backprop输出的最初梯度值,同时\(W\)也乘以了这个系数,这个系数小于1,因此\(L2\)正则化也被称为“权重衰减”。
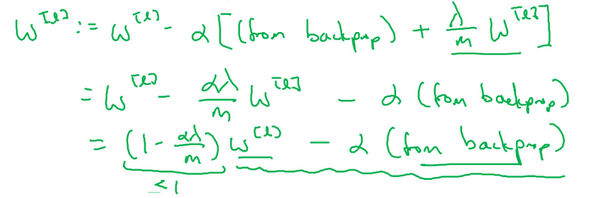
不打算这么叫它,之所以叫它“权重衰减”是因为这两项相等,权重指标乘以了一个小于1的系数。
以上就是在神经网络中应用\(L2\)正则化的过程。
神经网络优化篇:详解正则化(Regularization)的更多相关文章
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- CentOS 7 下编译安装lnmp之PHP篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.PHP下载 官网 http ...
- CentOS 7 下编译安装lnmp之MySQL篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.MySQL下载 MySQL ...
- CentOS 7 下编译安装lnmp之nginx篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:CentOS Linux release 7.5.1804 (Core),ip地址 192.168.1.168 ...
- Canal:同步mysql增量数据工具,一篇详解核心知识点
老刘是一名即将找工作的研二学生,写博客一方面是总结大数据开发的知识点,一方面是希望能够帮助伙伴让自学从此不求人.由于老刘是自学大数据开发,博客中肯定会存在一些不足,还希望大家能够批评指正,让我们一起进 ...
- java提高篇-----详解java的四舍五入与保留位
转载:http://blog.csdn.net/chenssy/article/details/12719811 四舍五入是我们小学的数学问题,这个问题对于我们程序猿来说就类似于1到10的加减乘除那么 ...
- 组件--Fragment(碎片)第二篇详解
感觉之前看的还是不清楚,重新再研究了一次 Fragment常用的三个类: android.app.Fragment 主要用于定义Fragment android.app.FragmentManager ...
- JavaScript基础篇详解
全部的数据类型: 基本数据类型: undefined Number Boolean null String 复杂数据类型: object ①Undefined: >>>声明但未初始化 ...
随机推荐
- Excel中的数值四舍五入方法详解
在日常工作和数据处理中,我们经常需要对数值进行四舍五入操作.Excel作为一款强大的电子表格软件,提供了多种方法来实现数值的四舍五入.本文将介绍Excel中常用的四舍五入函数及其基本使用方法. ROU ...
- 如何利用电商API接口来获取商品数据
要利用电商API接口来获取商品数据,我们可以按照以下步骤实现: 确定电商平台和API接口 不同的电商平台提供不同的API接口,因此我们需要确定我们要获取商品数据的电商平台,并选择相应的API接口进行调 ...
- 拓展kmp
Smiling & Weeping ---- 我从不觉得暗恋是苦涩的, 对一个人的喜欢藏在眼睛里, 透过它, 世界都变得更好看了. 题目:P5410 [模板]扩展 KMP(Z 函数) - 洛谷 ...
- 如何解决IOS 15提示“此App的开发者需要更新APP以在此IOS版本上正常工作”, 无法打开安装的APP的问题
在苹果手机最新的IOS 15 beta的系统上安装自签名或者企业签名的APP时,可能会遇到如下的错误提示: 此App的开发者需要更新APP以在此IOS版本上正常工作 The developer of ...
- Strimzi Kafka Bridge(桥接)实战之一:简介和部署
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 关于<Strimzi Kafka Bridge( ...
- CF276C
题目简化和分析: 属于一种贪心思维,我们想如果要使得和最大,那么就必须保证最大的数乘的次数越多越好,并且排序没有限制,快速累加每个位置出现的次数,所以应该使用线段树差分. 然后排序最大乘最大累加. S ...
- Git小白入坑总结(部分)
本地仓库的创建和初始化 git操作远程仓库 git clone git pull git push 对Git连接GitHub过程的理解 本地仓库的创建和初始化 直接在对应文件夹下用git init可以 ...
- XCODE9.1的一些新问题
自从XCODE7苹果就允许用免费的开发者账号进行真机测试了,但是还是有很多限制的. 在用的过程中发现限制如下: 1.只能生成*.app文件,不能打包成ipa.官方这么说的,但是奇诡的是,我archiv ...
- 针对Jupter Kernel error的问题解决
首先打开Anaconda Prompt 输入jupyter kernelspec list查看安装的内核和位置 到显示的的目录下面找到 kernel.josn这个文件 修改为现在的python环境路径 ...
- Android WebAPIOperator
package com.example.myapplication2.models.CommonClasses; import org.json.JSONObject; import java.io. ...