【数据结构与算法笔记04】对图搜索策略的一些思考(包括DFS和BFS)
图搜索策略
这里的“图搜索策略”应该怎么理解呢?
首先,是“图搜索”,所谓图无非就是由节点和边组成的,那么图搜索也就是将这个图中所有的节点和边都访问一遍。
其次是“策略”:
==> 如果就直接给你一个图,要怎么样才能将所有的节点和边都访问一遍呢?
这里可以考虑一个非常非常大并且结构复杂的图,那么当拿到这个图的时候信息庞杂无比,你不知道里面有多少个节点,有多少条边,不知道节点和边之间是怎样错综复杂的关系,不知道有多少连通子图......
对这样的图进行搜索会让人一下子摸不着头绪,这时候肯定会想到,得有一个入手点才行!这是一个很通用的解决问题的策略,当整体过于复杂的时候不如试着从一个很小的局部开始一点点梳理脉络。
这个入手点一般是某个节点。
==> 有了一个入手点之后,要怎样继续去搜索其他的节点和边呢?
这时候会考虑,从我已有的知识来说,我目前只知道一个搜索的起点(记为source),以及关于这个起点的一些信息:与source相连的边的集合,与source相邻的节点集合。不过这两个信息其实是重合的,如果我现在从source出发去访问一条与source相连的边,其实也就是访问了这条边另一头的节点(source的一个邻居)。
当我走了这一条边之后,到达source的这个邻居节点之后,又会得到与这个邻居节点相邻的边以及它的邻居......
也就是说,在每一个时间截面(或者说选择节点)上,我都有很多选择——我有一个可以访问但还没有访问的节点的集合,此时我会从这个节点集合中选出一个节点,想前走一步,每探索一步,我对这个图的了解就更深一步(如果说有一个已经访问过的节点的集合,那么这个集合中节点的个数就可以理解为深入的程度),但这样的深入并非永无止境,这个图总会遍历完(总会到达这样一个选择节点:此时没有任何可以继续访问的节点了),所以这个探索会像一个先膨胀再收缩的过程(或者说像一个回力镖?),总会回到已经访问过的节点上来,这时候就不必再继续下去了,再继续下去对 “遍历更多的节点和边” 这一目标没有任何价值。
于是我得到了一个初步的搜索思路:
我有一个可以访问但还没有访问的节点的集合(记为Package),初始时这个集合中只有我一个节点。
每访问一个节点,都有可能会向这个Package中装入一些新的节点(当前访问的节点的邻居中,还没有访问过的那些节点),当然也可能不会。
我每次从这个Package中取一个节点,然后更新一下Package的内容,然后再取一个节点......就这样一直重复直到Package为空,这时就已经将从source所在的那个连通子图全部遍历完了。
==> 每次取出一个节点?
对于刚刚得出的搜索策略,还有一个值得思考的地方:每次取一个节点?每次取哪个节点?
而如何决定每一次取出哪一个节点这个问题就是所谓的“策略”。
当确定了“策略”之后,还需要考虑Package用什么数据结构来存储,要选择一个最适合于搜索策略的数据结构。
画外音:不能狭隘地认为一说到图搜索或者遍历图,不是DFS就是BFS,虽然确实这两种是最最常用而且能高效地解决很多问题的搜索策略。但是我也可以简单地每次就随机取一个节点进行访问,或者说每次先把剩余未访问邻居最多的节点拿出来访问,或者说每次把距离source最近的节点拿出来访问等等。我这里只是随便举一些例子,我想说的是,图搜索的策略有千千万万种,我们不能局限自己的思路,当拿到一个问题时,应该想着,怎么样为这个问题服务,而不是直接就开始想“这题用DFS能不能做?不能就用BFS”。
深度优先搜素(DFS)& 广度优先搜索(BFS)
跟着上面的思路来考虑DFS和BFS的搜索策略:
- DFS:每次从Package中选出距离source最远的节点进行访问。
- BFS:每次从Package中选出距离source最近的节点进行访问。
如果在某一个选择节点有多个距离source最近/远的节点,选哪一个都可以,具体选哪个现在暂时无法决定,这个问题先留着之后再考虑。
在前面的“初步搜索思路”中有一个很重要的细节,回顾一下我们是如何更新Package的?
每访问一个节点,都有可能会向这个Package中装入一些新的节点(当前访问的节点的邻居中,还没有访问过的那些节点)...
如果在访问某个节点A时对Package进行了更新:
- DFS:A离source的距离(记为k)大于等于当前Package中的所有节点
==> A的邻居中,还没有被访问过的那些节点离source的距离(k+1)一定大于当前Package中的所有节点
==> 下一次访问的节点一定是这次刚刚加入Package的节点中的某一个
==> 典型的“后入先出”
==> Package用栈来存
==> 每次从栈顶取出一个节点,对其进行访问,并将它的 邻居中还没有被访问过的节点 压栈
- BFS: 假设当前Package中距离source最近的节点构成一个集合S_k,假设它们离source为k
==> 每次从这个集合中选出一个节点,并将该节点的邻居中还没有被访问过的那些节点(离source的距离为k+1)放入Package中
==> 在访问S_k时加入到Package中的节点构成集合 S_k+1,以此类推
==> 这就意味着节点是按照他们和source的距离加入Package的,也是按照他们和source的距离离开Package的
==> 加入的顺序 = 离开的顺序
==> 典型的“先入先出”
==> Package用队列来存
==> 每次从队首取出一个节点,对其进行访问,并将它的 邻居中还没有被访问过的节点 放入队尾
再回头看刚才遗留的那个问题:如果在某一个选择节点有多个距离source最近/远的节点时,应该选哪一个?
在DFS中,显然是选最后加入的那一个;在BFS中,是选最先加入的那一个。因为选哪一个其实都可以,按照这样的方式取是最方便的,所以这个问题也就解决了。
到这里就可以开始编码实现了。
编码实现
这里采用《算法(第4版)》中的图处理算法的设计模式:
1. DFS
因为DFS是用 “栈” 来控制顺序的,所以有两种写法:一种是显示地使用一个栈,用迭代的方式来实现;另一种是隐式地使用栈,用递归的方式实现。
1 #pragma once
2 #include <stack>
3 #include "Graph.h"
4 using namespace std;
5
6 class DepthFirstSearch {
7 private:
8 bool* mymarked; //在递归写法中:某一个时间截面记录已经访问过的节点
9 //在迭代写法中:某一个时间截面记录已经压过栈的节点
10 //在dfs结束后记录与s节点连通的所有节点
11
12 public:
13 DepthFirstSearch(Graph G, int s) {
14 //初始化辅助数组mymarked
15 mymarked = new bool[G.v()];
16 for (int i = 0; i < G.v(); i++)
17 mymarked[i] = false;
18
19 //深度优先搜索
20 //dfs_recursion(G, s);
21 dfs_iteration(G, s);
22 }
23
24 void dfs_recursion(Graph G, int s) {
25 //Step1: 访问当前节点
26 mymarked[s] = true;
27
28 //Step2: 对于S的所有邻居,如果没有访问过的话,调用dfs自身来访问它
29 for (int i = 0; i < G.adj(s).size(); i++) {
30 if (mymarked[G.adj(s)[i]] == false)
31 dfs_recursion(G, G.adj(s)[i]);
32 }
33 }
34
35 void dfs_iteration(Graph G, int s) {
36 stack<int> S;
37
38 //Step0: 初始化栈:放入source节点
39 S.push(s);
40 mymarked[s] = true;
41
42 while (!S.empty()) {
43 //Step1: 取出栈顶元素进行访问
44 int cur = S.top();
45 S.pop();
46
47 //Step2: 将cur节点的邻居节点中,尚未被访问过的节点压栈
48 for (int i = 0; i < G.adj(cur).size(); i++) {
49 if (mymarked[G.adj(cur)[i]] == false) {
50 mymarked[G.adj(cur)[i]] = true;
51 S.push(G.adj(cur)[i]);
52 }
53 }
54 }
55 }
56
57 bool marked(int w) {
58 return mymarked[w];
59 }
60
61 };
2. BFS
1 #pragma once
2 #include <queue>
3 #include "Graph.h"
4 using namespace std;
5
6 class BreadFirstSearch {
7 private:
8 bool* mymarked; //某一个时间截面记录已经进入过队列的节点
9 //在bfs结束后记录与s节点连通的所有节点
10
11 public:
12 BreadFirstSearch(Graph G, int s) {
13 //初始化辅助数组mymarked
14 mymarked = new bool[G.v()];
15 for (int i = 0; i < G.v(); i++) {
16 mymarked[i] = false;
17 }
18
19 //广度优先搜索
20 bfs(G, s);
21 }
22
23 void bfs(Graph G, int s) {
24 queue<int> Q;
25
26 //Step0: 初始化队列:放入source节点
27 Q.push(s);
28 mymarked[s] = true;
29
30 while (!Q.empty()) {
31 //Step1: 取出队首元素进行访问
32 int cur = Q.front();
33 Q.pop();
34
35 //Step2: 将cur节点的邻居节点中,尚未被访问过的节点放入队尾
36 for (int i = 0; i < G.adj(cur).size(); i++) {
37 if (mymarked[G.adj(cur)[i]] == false) {
38 mymarked[G.adj(cur)[i]] = true;
39 Q.push(G.adj(cur)[i]);
40 }
41 }
42
43 }
44
45 }
46
47 bool marked(int w) {
48 return mymarked[w];
49 }
50
51 };
值得注意的是:
在两个迭代算法中,mymarked[i] == true的含义是:将该节点放入Package这个操作已经执行过了。
将节点i放入Package意味着它之后一定会被访问,而不是现在就被访问了。
从Package中取出节点i才意味着它被访问了。
所以将一个节点对应的mymarked[i]设为True的时机应该是将它放入Package时,而不是从Package中取出时。
DFS和BFS的对比
“深度优先搜索和广度优先搜索是我们首先学习的几种通用的图搜索的算法之一。
在搜索中我们都会先将起点存入数据结构中,然后重复以下步骤直到数据结构被清空:
- 取其中的下一个顶点并标记它;
- 将 v 的所有相邻而又未被标记的顶点加入数据结构。
- 深度优先搜索不断深入图中并在栈中保存了所有分叉的顶点;广度优先搜索则像扇面一般扫描图,用一个队列保存访问过的最前端的顶点。
- 深度优先搜索探索一幅图的方式是寻找离起点更远的顶点,只在碰到死胡同时才访问近处的顶点;广度优先搜索则会首先覆盖起点附近的顶点,只在临近的所有顶点都被访问了之后才向前进。
- 深度优先搜索的路径通常较长而且曲折,广度优先搜索的路径则短而直接。”
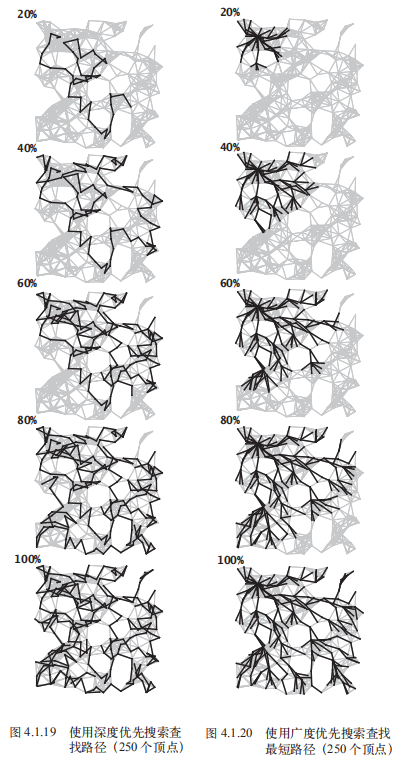
画外音:书中在介绍DFS之前还介绍了一个走迷宫的例子,这个例子对于理解DFS也很有价值。
【数据结构与算法笔记04】对图搜索策略的一些思考(包括DFS和BFS)的更多相关文章
- 数据结构与算法笔记(java)目录
数据结构: 一个动态可视化数据结构的网站 线性结构 数组 动态数组 链表 单向链表 双向链表 单向循环链表 双向循环链表 栈 栈 队列 队列 双端队列 哈希表 树形结构 二叉树 二叉树 二叉搜索树 A ...
- 【4】学习JS 数据结构与算法笔记
第一章 JS 简介 1. 环境搭建的三种方式 1. 下载浏览器 2. 使用 Web 服务器 ( XAMPP ) 3. 使用 Node.js 搭建 Web 服务器 4. 代码地址>> 2. ...
- 数据结构与算法C++描述学习笔记1、辗转相除——欧几里得算法
前面学了一个星期的C++,以前阅读C++代码有些困难,现在好一些了.做了一些NOI的题目,这也是一个长期的目标中的一环.做到动态规划的相关题目时发现很多问题思考不通透,所以开始系统学习.学习的第一本是 ...
- 数据结构(逻辑结构,物理结构,特点) C#多线程编程的同步也线程安全 C#多线程编程笔记 String 与 StringBuilder (StringBuffer) 数据结构与算法-初体验(极客专栏)
数据结构(逻辑结构,物理结构,特点) 一.数据的逻辑结构:指反映数据元素之间的逻辑关系的数据结构,其中的逻辑关系是指数据元素之间的前后件关系,而与他们在计算机中的存储位置无关.逻辑结构包括: 集合 数 ...
- 《数据结构与算法之美》 <04>链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是 LRU 缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 《java数据结构和算法》读书笔记
大学时并不是读计算机专业的, 之前并没有看过数据结构和算法,这是我第一次看. 从数据结构方面来说: 数组:最简单,遍历.查找很快:但是大小固定,不利于扩展 ...
- 【Java数据结构学习笔记之二】Java数据结构与算法之栈(Stack)实现
本篇是java数据结构与算法的第2篇,从本篇开始我们将来了解栈的设计与实现,以下是本篇的相关知识点: 栈的抽象数据类型 顺序栈的设计与实现 链式栈的设计与实现 栈的应用 栈的抽象数据类型 栈是 ...
- 【Java数据结构学习笔记之二】Java数据结构与算法之队列(Queue)实现
本篇是数据结构与算法的第三篇,本篇我们将来了解一下知识点: 队列的抽象数据类型 顺序队列的设计与实现 链式队列的设计与实现 队列应用的简单举例 优先队列的设置与实现双链表实现 队列的抽象数据类型 ...
- java数据结构和算法学习笔记
第一章 什么是数据结构和算法 数据结构的概述 数据结构是指 数据再计算机内存空间或磁盘空间中的组织形式 1.数据结构的特性 数据结构 优点 缺点 数组 插入快,如果知道下标可以快速存取 查找和删除慢 ...
随机推荐
- HTML5 & canvas fingerprinting
HTML5 & canvas fingerprinting demo https://codepen.io/xgqfrms/full/BaoMWMp window.addEventListen ...
- ruby & rvm
ruby & rvm https://rvm.io/ Ruby Version Manager (RVM) RVM is a command-line tool which allows yo ...
- SDK & 埋点 & user behavior tracker
SDK & 埋点 & user behavior tracker 同一个 SDK ,根据不同的应用市场, 分别进行统计分析 ? https://www.umeng.com/ user ...
- 万链互联时代,NGK DeFi项目如何在牛市中崭露头角!
众所周知,中心化交易所存在技术风险.道德风险与法律风险.去中心化交易所像是NGK以其匿名性.安全性.私钥独立掌控的特点,弥补了中心化交易所的不足,我们看到Uniswap日成交量均超过1亿美元,甚至接近 ...
- PBN进场程序保护区图例分析
疫情仍在持续,除了待家里不给祖国添乱之外,过去没有时间去完成的事情,现在可以静下心来认真面对,充实过好每一天. 今天想跟大家聊一下ICAO 8168第二卷PBN进场程序的图例. 就是下面这张图: ...
- iframe重定向问题
sandbox="allow-forms allow-scripts allow-same-origin allow-popups"
- 二分图最小点覆盖构造方案+König定理证明
前言 博主很笨 ,如有纰漏,欢迎在评论区指出讨论. 二分图的最大匹配使用 \(Dinic\) 算法进行实现,时间复杂度为 \(O(n\sqrt{e})\),其中, \(n\)为二分图中左部点的数量, ...
- SpringBoot 整合 hibernate 连接 Mysql 数据库
前一篇搭建了一个简易的 SpringBoot Web 项目,最重要的一步连接数据库执行增删改查命令! 经过了一天的摸爬滚打,终于成功返回数据! 因为原来项目使用的 SpringMVC + Hibern ...
- IDEA中引用不到HttpServlet的解决方案
原文链接:https://blog.csdn.net/xiaozaizi666/article/details/87805564
- oracle ora-01114 IO error writing block to file 207 (block # )
oracle ORA-01114 IO error writing block to file 207 (block # ) Reference: https://stackoverflow.com/ ...