Hbase ——Not only SQL
HBase —— NoSQL_Not Only SQL
NoSQL数据库:
- 不遵循传统的RDBMS模型
- 解决数据库的可伸缩性和可用性(多机器)
- 数据是非关系的(可切分),不使用sql语句
- 不针对原子性或一致性(定时同步数据)问题
——————————————————————————————
传统关系型数据库存在瓶颈
- 高并发读写,每秒上万次读写请求
- 高存储量,分库分表难以维护
- 高扩展性,无法简单地通过增加硬件提升性能
- 高可用性,不能保证服务长时间运行时的稳定性
NoSQL的优势
- 优异的海量数据读写性能
- 灵活的数据模型
- 数据间无关系,易于切割、扩展
SQL与NOSQL对比
| 对比 | NoSQL | 关系型数据库 |
|---|---|---|
| 常用数据库 | HBase、MongoDB、Redis | Oracle、DB2、MySQL |
| 存储格式 | 文档、键值对、图结构 | 表格式,行和列 |
| 存储规范 | 鼓励冗余 | 规范性,避免重复 |
| 存储扩展 | 横向扩展,分布式 | 纵向扩展(横向扩展有限) |
| 查询方式 | 非结构化查询 | 结构化查询语言SQL |
| 事务 | 不支持事务一致性 | 支持事务 |
| 性能 | 读写性能高 | 读写性能差 |
| 成本 | 简单易部署,开源,成本低 | 成本高 |
NoSQL的特点
- 最终一致性,数据并非实时一致,但最终会一致
- 应用程序可以增加一致性
- 鼓励冗余数据存储
NoSQL 不等于 大数据
- nosql是为了帮助解决大数据的数据存储问题
- 但大数据不仅仅包含数据的存储问题(存储、分析)
NoSQL基本概念
一、三大基石
1、CAP理论
分布式系统最多支持3个中的两个(AC、AP、CP)
- Consistency 一致性
- Availability 可用性
- Partition Tolerance 分区容错性
NoSQL 不保证ACID,提供最终一致性(HBase是强一致性的,支持CP,因为其基于HDFS的,分区多副本)
2、BASE
Basically Availble 基本可用
- 允许部分失效, 但保证核心可用
Soft-state 软状态
- 状态可以有一段时间不同步
Eventual Consistency 最终一致性
- 系统经过一定时间后,数据最终能达到一致的状态
3、最终一致性
- 最终一致性是弱一致性的特列,系统会保证在一定时间内,能达到一个数据一致的状态,而不是时时一致
- Hbase是强一致性数据库,不是最终一致性。因为HBase基于HDFS存储系统的,而HDFS是实时备份的,备份完成后才返回操作结果,因此Hbase是强一致性的。
二、索引和查询
1、Indexing(索引)
大多数NoSQL是按key进行索引
部分NoSQL允许二级索引
HBase使用HDFS,append-only(读写很快)
- 批处理写入Logged
- 重新创建并排序文件
2、Query(查询)
- 没有专门的查询语言,通常使用脚本语言查询
- 有些开始支持SQL查询
- 有些可以使用MapReduce代码查询
三、MapReduce、Sharding
1、MapReduce 概念相关,map预处理映射,reduce分析/聚合(并非hadoop的mr)
2、sharding 分片 ,一种分区模式,可以复制分片
NoSQL分类
| 分类 | 举例 | 典型应用场景 |
|---|---|---|
| 键值存储数据库 (key-value) | Redis, MemcacheDB, Voldemort | 内容缓存等(减少检索数据库的次数) |
| 列存储数据库 (WIDE COLUMN STORE) | Cassandra, HBase | 应对分布式存储的海量数据 |
| 文档型数据库 (DOCUMENT STORE) | CouchDB, MongoDB | Web应用(可看做键值数据库的升级版) |
| 图数据库 (GRAPH DB) | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等,专注于构建关系图谱 |
- 通常大数据场景采用列存储数据库
HBase概述
1)hbase是一个分布式的,基于列式存储的数据库,基于hadoop的hdfs存储,zookeeper进行管理。
2)hbase 适合存储半结构化或非结构化的数据,对于数据结构字段不够确定或者杂乱无章很难按照一个概念去抽取的数据。
HBase是一个领先的NoSQL数据库
- 是一个面向列存储的数据库
- 是一个分布式hash map
- 基于Google Big Table论文
- 使用HDFS作为存储并利用其可靠性
HBase特点
- 数据访问速度快,响应时间约2-20毫秒
- 支持随机读写(实质是切片再append),每个节点20k~100k+ ops/s
- 可扩展性,可扩展到20,000+节点
HBase物理架构
1、HBase采用Master/Slaves架构
- HMaster
- RegionServer (salve,部署在datanode上)
- Zookeeper (监管集群)
- HBase Client(java、shell、rest thrift)
- Region (分区)
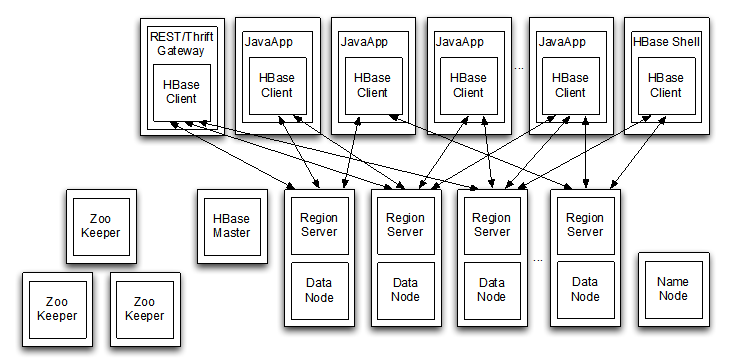
2、HMaster的作用
- 维护Table和Region的原数据信息
- 管理Region和为 RegionServer 分配Region
- 负责RegionServer的负载均衡
- 发现失效的RegionServer并重新分配其上的Region
- 处理 Schema 更新请求(表的创建,删除,修改,列簇的增加等等)
- 是HBase集群的主节点,可以配置多个,用来实现high available 高可用
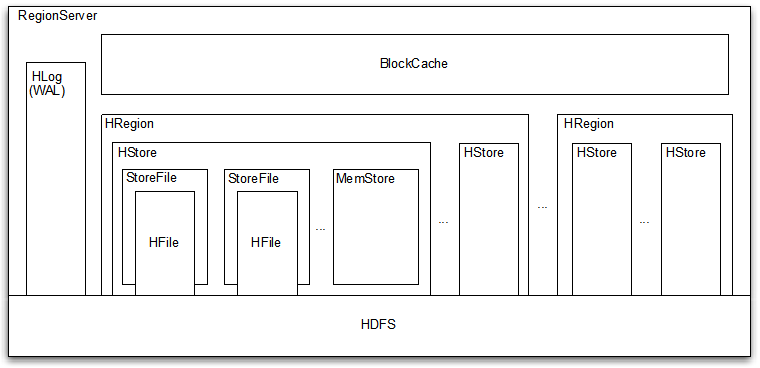
3、RegionServer负责管理维护Region
一个RegionServer包含一个WAL(数据操作日志)、一个BlockCache (读缓存)和多个Region
一个Region包含多个Store存储区,每个存储区对应一个列族
一个存储区由多个StoreFile和MemStore(写缓存,128M,一个Block)组成
一个StoreFile对应于一个HFile和一个列族
负责 Split 在运行过程中变得过大的 Region,负责 Compact 操作
WAL(write ahead log),在数据写入之前将操作写入日志,在灾难后可以最大程度恢复数据
HFile和WAL作为序列文件保存在HDFS上
Client与RegionServer交互

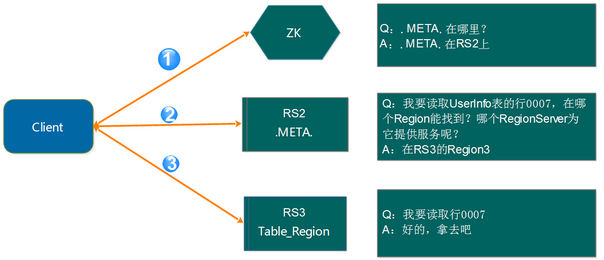
- 流程:clinet -> zookeeper . get meta 的region server->meta .get 要查询的rowkey对应region所在的regionserver地址 ->链接region server,查询
4、Region和Table
- 单表大小最大256M,之后会单个Table(表)被分区成大小大致相同的新Region
- Region是HBase集群分布数据的最小单位,但不是最小的数据存储单元,其下还有Store和HFile,HBase的数据存储是以HFile组织的
- Region由集群中的RegionServer维护,一个RS通常维护多个Region
- 但一个Region只能分配给一个RegionServer
5、Clinet 客户端
- 缓存机制,每次读写会记录地址信息
- 缓存地址信息错误多次后会重新访问ZK服务获取新的地址
HBase逻辑架构--ROW
- Rowkey(行键)是唯一的并按字典排序
- 每个Row都可以定义自己的列,即使其他Row不使用,一定范围具有联系的列的总和为列族
- 使用唯一时间戳维护多个Row版本
- 在不同版本中值类型可以不同
- HBase数据全部以字节存储
- 行键、列族、列键、时间戳、ceil值
- HBase只需要定义列族

HBase 架构特点
强一致性
自动扩展
当Region变大会自动分割
使用HDFS扩展数据并管理空间
写恢复
- 使用WAL(Write Ahead Log)
与Hadoop集成
Hbase ——Not only SQL的更多相关文章
- Phoenix——实现向HBase发送标准SQL语句
写在前面一: 本文总结基于HBase的SQL查询系统--Salesforce phoenix 写在前面二: 环境说明: 一.什么是Phoenix 摘自官网: Phoenix是一个提供hbase的sql ...
- 在HBase之上构建SQL引擎
- Phoenix(sql on hbase)简单介绍
Phoenix(sql on hbase)简单介绍 介绍: Phoenix is a SQL skin over HBase delivered as a client-embedded JDBC d ...
- 使用Phoenix将SQL代码移植至HBase
1.前言 HBase是云计算环境下最重要的NOSQL数据库,提供了基于Hadoop的数据存储.索引.查询,其最大的优点就是可以通过硬件的扩展从而几乎无限的扩展其存储和检索能力.但是HBase与传统的基 ...
- Phoenix(SQL On HBase)安装和使用报告
一.为什么使用Phoenix二.安装Phoenix2.1 兼容问题?2.2 编译CDH版本的Phoenix2.3 安装Phoenix到CDH环境中三.Phoenix的使用3.1 phoenix的4种调 ...
- HBase 学习之路(十)—— HBase的SQL中间层 Phoenix
一.Phoenix简介 Phoenix是HBase的开源SQL中间层,它允许你使用标准JDBC的方式来操作HBase上的数据.在Phoenix之前,如果你要访问HBase,只能调用它的Java API ...
- HBase 系列(十)—— HBase 的 SQL 中间层 Phoenix
一.Phoenix简介 Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据.在 Phoenix 之前,如果你要访问 HBase,只能 ...
- 入门大数据---Hbase的SQL中间层_Phoenix
一.Phoenix简介 Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据.在 Phoenix 之前,如果你要访问 HBase,只能 ...
- 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟
使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 Sqoop 大数据 Hive HBase ETL 使用Sqoop从MySQL导入数据到Hive和HBase 及近期感悟 基础环境 ...
随机推荐
- java 验证表单工具类,史上最全
package com.wiker.utils; import java.util.regex.*; /** * * @version 1.0 * @author wiker * @since JDK ...
- Shiro权限项目
目录 环境配置 spring容器 springmvc freemarker mybatis shiro 工具类 TokenManager.java Result.java 功能实现 登录 注册 个人中 ...
- 带撤销并查集 & 可持久化并查集
带撤销并查集支持从某个元素从原来的集合中撤出来,然后加入到一个另外一个集合中,或者删除该元素 用一个映射来表示元素和并查集中序号的关系,代码中用\(to[x]\) 表示x号元素在并查集中的 id 删除 ...
- Codeforces Round #675 (Div. 2)【ABCD】
比赛链接:https://codeforces.com/contest/1422 A. Fence 题意 给出三条边 $a,b,c$,构造第四条边使得四者可以围成一个四边形. 题解 $d = max( ...
- Educational Codeforces Round 90 (Rated for Div. 2) D. Maximum Sum on Even Positions(dp)
题目链接:https://codeforces.com/contest/1373/problem/D 题意 给出一个大小为 $n$ 的数组 $a$,下标为 $0 \sim n - 1$,可以进行一次反 ...
- 吉哥系列故事——完美队形II(马拉车算法)
吉哥又想出了一个新的完美队形游戏! 假设有n个人按顺序站在他的面前,他们的身高分别是h[1], h[2] ... h[n],吉哥希望从中挑出一些人,让这些人形成一个新的队形,新的队形若满足以下三点要求 ...
- Panasonic Programming Contest (AtCoder Beginner Contest 186) E.Throne (数学,线性同余方程)
题意:有围着一圈的\(N\)把椅子,其中有一个是冠位,你在离冠位顺时针\(S\)把椅子的位置,你每次可以顺时针走\(K\)个椅子,问最少要走多少次才能登上冠位,或者走不到冠位. 题解:这题和洛谷那个青 ...
- Atcoder Panasonic Programming Contest 2020
前三题随便写,D题是一道dfs的水题,但当时没有找到规律,直接卡到结束 A - Kth Term / Time Limit: 2 sec / Memory Limit: 1024 MB Score ...
- DOCKER - 构建一个docker镜像并跑起来
一.有个基础镜像 1.基础镜像的选择 当前市场有众多可选择的基础docker镜像,可参考: https://blog.csdn.net/nklinsirui/article/details/80967 ...
- codeforces 878A
A. Short Program time limit per test 2 seconds memory limit per test 256 megabytes input standard in ...