spark开窗函数
源文件内容示例:
http://bigdata.beiwang.cn/laoli
http://bigdata.beiwang.cn/laoli
http://bigdata.beiwang.cn/haiyuan
http://bigdata.beiwang.cn/haiyuan
实现代码:
object SparkSqlDemo11 {
/**
* 使用开窗函数,计算TopN
* @param args
*/
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local")
.getOrCreate()
import session.implicits._
//原数据:http://bigdata.beiwang.cn/laoli
val sourceData = session.read.textFile("E:\\北网学习\\K_第十一个月_Spark 2(2019.8)\\8.5\\teacher.log")
val df = sourceData.map(line => {
val index = line.lastIndexOf("/")
val t_name = line.substring(index + 1)
val url = new URL(line.substring(0, index))
val subject = url.getHost.split("\\.")(0)
(subject, t_name)
}).toDF("subject", "t_name")
操作01:得到所有专业下所有老师的访问数:
df.createTempView("temp")
//获得所有学科下老师的访问量:
val middleData: DataFrame = session.sql("select subject,t_name,count(*) cnts from temp group by subject,t_name")
//middleData.show()
+-------+--------+----+
|subject| t_name|cnts|
+-------+--------+----+
|bigdata| laoli| 2|
|bigdata| haiyuan| 15|
| javaee|chenchan| 6|
| php| laoliu| 1|
| php| laoli| 3|
| javaee| laoshi| 9|
|bigdata| lichen| 6|
+-------+--------+----+
操作02:row_number() over()【按照老师的访问数,降序开窗】
//再将中间值middleData注册成一张表
middleData.createTempView("middleTemp") //执行第二部查询,使用row_number()开窗函数,对所有的老师的访问数进行排序并添加编号
//开窗后生成的编号列 rn 是一个伪列,只能用于展示,不能用于查询
//row_number() over() 函数是按照某种规则对数据进行编号,需要我们在over()中指定一个排序规则,无规则将会报错
//此处是按照cnts列降序开窗
session.sql(
"""
|select subject,t_name,cnts,row_number() over(order by cnts desc) rn from middleTemp
""".stripMargin).show()
+-------+--------+----+---+
|subject| t_name|cnts| rn|
+-------+--------+----+---+
|bigdata| haiyuan| 15| 1|
| javaee| laoshi| 9| 2|
| javaee|chenchan| 6| 3|
|bigdata| lichen| 6| 4|
| php| laoli| 3| 5|
|bigdata| laoli| 2| 6|
| php| laoliu| 1| 7|
+-------+--------+----+---+
注意:over()内必须指定开窗规则,否则会抛出解析异常:
session.sql(
"""
|select subject,t_name,cnts,row_number() over() rn from middleTemp
""".stripMargin).show()
Exception in thread "main" org.apache.spark.sql.AnalysisException: Window function row_number() requires window to be ordered, please add ORDER BY clause. For example SELECT row_number()(value_expr) OVER (PARTITION BY window_partition ORDER BY window_ordering) from table;
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$class.failAnalysis(CheckAnalysis.scala:39)
at org.apache.spark.sql.catalyst.analysis.Analyzer.failAnalysis(Analyzer.scala:91)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveWindowOrder$$anonfun$apply$31$$anonfun$applyOrElse$12.applyOrElse(Analyzer.scala:2173)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveWindowOrder$$anonfun$apply$31$$anonfun$applyOrElse$12.applyOrElse(Analyzer.scala:2171)
操作03:row_number() over(partition by.. 【根据学科进行分区后为每个分区开窗】
//根据学科进行分区后为每个分区开窗
session.sql(
"""
|select subject,t_name,cnts,row_number() over(partition by subject order by cnts desc) rn from middleTemp
""".stripMargin).show()
+-------+--------+----+---+
|subject| t_name|cnts| rn|
+-------+--------+----+---+
| javaee| laoshi| 9| 1|
| javaee|chenchan| 6| 2|
|bigdata| haiyuan| 15| 1|
|bigdata| lichen| 6| 2|
|bigdata| laoli| 2| 3|
| php| laoli| 3| 1|
| php| laoliu| 1| 2|
+-------+--------+----+---+
注意:开窗生成的列是伪列,不能用于实际操作:
//开窗形成的列是伪列,不能用于实际操作
session.sql(
"""
|select subject,t_name,cnts,row_number() over(partition by subject order by cnts desc) rn from middleTemp
|where rn <=2
""".stripMargin).show()

操作04:伪列的使用:
由于开窗形成的伪列不能被直接用于查询,那么我们可以将整个开窗语句的操作作为一个子查询使用,那么开窗语句的结果集对于父查询来说就是一张完整的表,这时候伪列就是一个有效的列,可以用于查询:
//开窗生成的伪列不能用于直接查询,但是我们可以将开窗语句的结果集作为一张表或者说一个子查询,这时候伪列就是一个有效的列,可以进行再次嵌套查询,
session.sql(
"""
|select * from (
|select subject,t_name,cnts,row_number() over(partition by subject order by cnts desc) rn from middleTemp
|) where rn <= 2
""".stripMargin).show()
+-------+--------+----+---+
|subject| t_name|cnts| rn|
+-------+--------+----+---+
| javaee| laoshi| 9| 1|
| javaee|chenchan| 6| 2|
|bigdata| haiyuan| 15| 1|
|bigdata| lichen| 6| 2|
| php| laoli| 3| 1|
| php| laoliu| 1| 2|
+-------+--------+----+---+
操作05:【开窗嵌套开窗】rank() over() 函数
在row_number() over() 分区+开窗的基础上,再次进行rank() over() 按照cnts进行全部数据的开窗
//开窗嵌套开窗:
//rank() over() 函数
session.sql(
"""
|select t.*,rank() over(order by cnts desc) rn1 from (
|select subject,t_name,cnts,row_number() over(partition by subject order by cnts desc) rn from middleTemp
|) t
|where rn <= 2
""".stripMargin).show()
+-------+--------+----+---+---+
|subject| t_name|cnts| rn|rn1|
+-------+--------+----+---+---+
|bigdata| haiyuan| 15| 1| 1|
| javaee| laoshi| 9| 1| 2|
| javaee|chenchan| 6| 2| 3|
|bigdata| lichen| 6| 2| 3|
| php| laoli| 3| 1| 5|
| php| laoliu| 1| 2| 6|
+-------+--------+----+---+---+
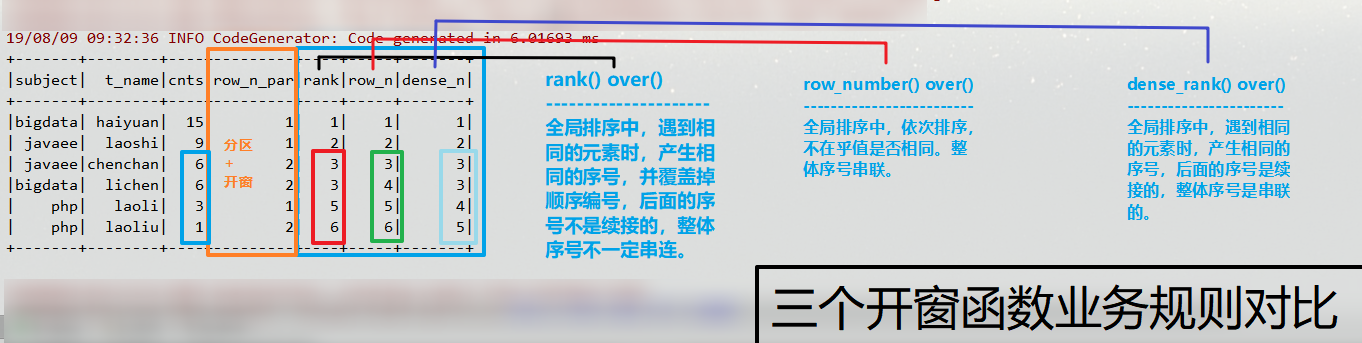
操作06:dense_rank() over() 函数 【三个开窗函数的业务对比】:
//dense_rank() over() 函数
//三个开窗函数的业务对比:
session.sql(
"""
|select t.*,rank() over(order by cnts desc) rank,
|row_number() over(order by cnts desc) row_n,
|dense_rank() over(order by cnts desc) dense_n
|from (
|select subject,t_name,cnts,row_number() over(partition by subject order by cnts desc) row_n_par from middleTemp
|) t
|where row_n_par <= 2
""".stripMargin).show()
+-------+--------+----+---------+----+-----+-------+
|subject| t_name|cnts|row_n_par|rank|row_n|dense_n|
+-------+--------+----+---------+----+-----+-------+
|bigdata| haiyuan| 15| 1| 1| 1| 1|
| javaee| laoshi| 9| 1| 2| 2| 2|
| javaee|chenchan| 6| 2| 3| 3| 3|
|bigdata| lichen| 6| 2| 3| 4| 3|
| php| laoli| 3| 1| 5| 5| 4|
| php| laoliu| 1| 2| 6| 6| 5|
+-------+--------+----+---------+----+-----+-------+
操作07:整合为一句SQL完成:
//合并两个SQL语句:
session.sql(
"""
|select t.*,rank() over(order by cnts desc) rank,
|row_number() over(order by cnts desc) row_n,
|dense_rank() over(order by cnts desc) dense_n
|from
|(select subject,t_name,cnts,row_number() over(partition by subject order by cnts desc) row_n_par from
|(select subject,t_name,count(*) cnts from temp group by subject,t_name)) t
|where row_n_par <= 2
""".stripMargin).show()
+-------+--------+----+---------+----+-----+-------+
|subject| t_name|cnts|row_n_par|rank|row_n|dense_n|
+-------+--------+----+---------+----+-----+-------+
|bigdata| haiyuan| 15| 1| 1| 1| 1|
| javaee| laoshi| 9| 1| 2| 2| 2|
| javaee|chenchan| 6| 2| 3| 3| 3|
|bigdata| lichen| 6| 2| 3| 4| 3|
| php| laoli| 3| 1| 5| 5| 4|
| php| laoliu| 1| 2| 6| 6| 5|
+-------+--------+----+---------+----+-----+-------+
spark开窗函数的更多相关文章
- 【Spark篇】---SparkSQL中自定义UDF和UDAF,开窗函数的应用
一.前述 SparkSQL中的UDF相当于是1进1出,UDAF相当于是多进一出,类似于聚合函数. 开窗函数一般分组取topn时常用. 二.UDF和UDAF函数 1.UDF函数 java代码: Spar ...
- Spark(十三)SparkSQL的自定义函数UDF与开窗函数
一 自定义函数UDF 在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_ ...
- Spark之开窗函数
一.简介 开窗函数row_number()是按照某个字段分组,然后取另外一个字段排序的前几个值的函数,相当于分组topN.如果SQL语句里面使用了开窗函数,那么这个SQL语句必须使用HiveConte ...
- 【Spark-SQL学习之三】 UDF、UDAF、开窗函数
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- SparkSQL开窗函数 row_number()
开始编写我们的统计逻辑,使用row_number()函数 先说明一下,row_number()开窗函数的作用 其实就是给每个分组的数据,按照其排序顺序,打上一个分组内行号 比如说,有一个分组20151 ...
- 开窗函数 First_Value 和 Last_Value
在Sql server 2012里面,开窗函数丰富了许多,其中带出了2个新的函数 First_Value 和 Last Value .现在来介绍一下这2个函数的应用场景. 首先分析一下First_Va ...
- Oracle开窗函数 over()(转)
copy文链接:http://blog.csdn.net/yjjm1990/article/details/7524167#,http://www.2cto.com/database/201402/2 ...
- oracle的分析函数over 及开窗函数
转:http://www.2cto.com/database/201310/249722.html oracle的分析函数over 及开窗函数 一:分析函数over Oracle从8.1.6开 ...
- 开窗函数 --over()
一个学习性任务:每个人有不同次数的成绩,统计出每个人的最高成绩. 这个问题应该还是相对简单,其实就用聚合函数就好了. select id,name,max(score) from Student gr ...
随机推荐
- C# 递归算法获取下级子级 2种方法
第一种 直接实体添加Children 实体类 public class DepartmentItem { /// <summary> /// 部门Id /// </summary&g ...
- 如何使用阿里云云解析API实现动态域名解析,搭建私有服务器
原文地址:http://www.yxxrui.cn/article/116.shtml 未经许可请勿转载,如有疑问,请联系作者:yxxrui@163.com 公司的网络没有固定的公网IP地址,但是能够 ...
- easyui中在formatter: function (value, row,index) {中添加删除方法
{ field : 'abj', title : '操作', align : 'center', resizable:false, width:'10%', formatter: function ( ...
- 后台查询出来的list结果 在后台查询字典表切换 某些字段的内容
list=listEFormat(list, "Class_type", "611");//list查询数据库得到的结果Class_type /** * @Ti ...
- java中游标
package YouBiao; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.Resu ...
- 【目标检测】基于传统算法的目标检测方法总结概述 Viola-Jones | HOG+SVM | DPM | NMS
"目标检测"是当前计算机视觉和机器学习领域的研究热点.从Viola-Jones Detector.DPM等冷兵器时代的智慧到当今RCNN.YOLO等深度学习土壤孕育下的GPU暴力美 ...
- 庐山真面目之十微服务架构 Net Core 基于 Docker 容器部署 Nginx 集群
庐山真面目之十微服务架构 Net Core 基于 Docker 容器部署 Nginx 集群 一.简介 前面的两篇文章,我们已经介绍了Net Core项目基于Docker容器部署在Linux服 ...
- 漫谈JSON Web Token(JWT)
一.背景 传统的单体应用基于cookie-session的身份验证流程一般是这样的: 用户向服务器发送账户和密码. 服务器验证账号密码成功后,相关数据(用户角色.登录时间等)都保存到当前会话中. 服务 ...
- Mirai框架qq机器人教程
Mirai框架qq机器人教程 0.前言 1. 安装Java 2.安装Mirai启动器 3.下载IDEA或其他编译器 4.创建mirai-console插件项目 4.1 通过git创建 4.2 通过插件 ...
- JavaCV更新到1.5.x版本后的依赖问题说明以及如何精简依赖包大小
javaCV全系列文章汇总整理 javacv教程文档手册开发指南汇总篇 前言 JavaCV更新到1.5.x版本,依赖包也迎来了很大变化,体积也变大了不少.很多小伙伴们反馈,之前很多1.3.x和1.4. ...