【原创】xenomai与VxWorks实时性对比(资源抢占上下文切换对比)
版权声明:本文为本文为博主原创文章,转载请注明出处。如有问题,欢迎指正。博客地址:https://www.cnblogs.com/wsg1100/
(下面数据,仅供个人参考)
可能大部分人一直好奇VxWorks与xenomai对比,实时性孰优孰劣,正好笔者最近要做一个这方面的对比。声明:下面数据,仅供个人参考,有不对的地方还请指出。
本文继上一篇文章【原创】xenomai与VxWorks实时性对比(Jitter对比),主要对比VxWorks与xenomai两个硬实时操作系统在对各类资源操作时,任务抢占切换的耗时。
一、环境
简单介绍一下环境:
硬件平台:双核cortex-A15处理器,CPU频率1.5GHZ,内存2GB。
xenomai:Linux-4.19+xenomai 3.1,具体配置:略;
VxWorks:VxWorks 7,具体配置:略;
注:
- 由于VxWorks benchmark测试包含很多测试项,以下数据为其中包含的几项,每项测试2万次;xenomai与其一致。
- 既然对比,那么测试方法、数据处理就得和VxWorks一致,所以xenomai测试用例实现参考VxWorks benchmark测试用例。
- xenomai的数据为用户态测试,VxWorks数据为内核态测试,测试本身xenomai就处于劣势,哈哈,有兴趣的小伙伴可以将测试用例在xenomai内核态写一份看看。
- xenomai测试用例使用Alchemy API编写,Alchemy API是一层posix接口的封装,所以Alchemy API性能可能弱于POSIX接口。
二、 指标概念
任务切换时间(task switching time),定义为系统在两个独立的、处于就绪态并且具有相同优先级的任务之间切换所需要的时间。
切换所需的时间主要取决于保存任务上下文所用的数据结构以及操作系统采用的调度算法的效率。产生任务切换的原因可以是资源可得,信号量的获取等。任务切换是任一多任务系统中基本效率的测量点,它是同步的,非抢占的。影响任务切换的因素有:主机CPU的结构,指令集以及CPU特性等
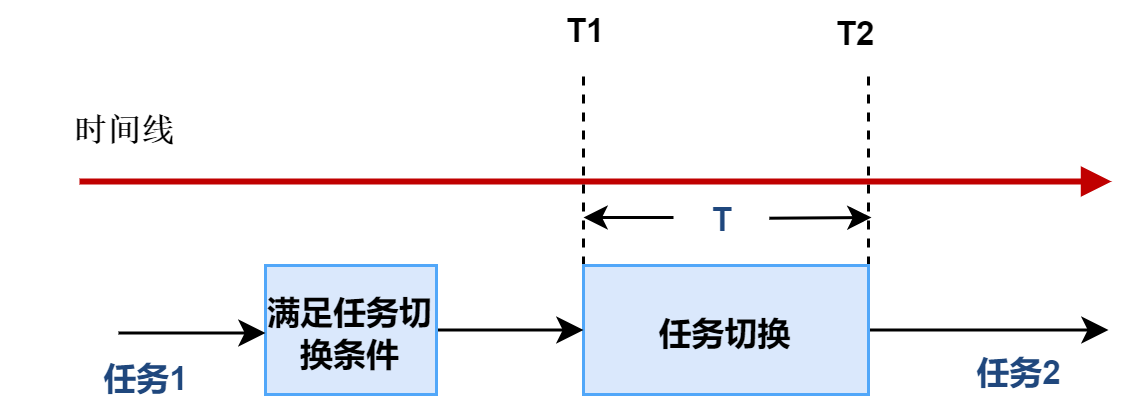
2.1 单核CPU
即测试相关的任务运行在同一CPU核上,这里表示单核上的上下文切换。
2.1.1 信号量响应上下文切换时间
信号量响应时间是指从一个任务释放信号量到另一个等待该信号量的任务被激活的时间延迟。 在RTOS中,通常有许多任务同时竞争某一共享资源,基于信号量的互斥访问保证了任一时刻只有一个任务能够访问公共资源。信号量响应时间反映了与互斥有关的时间开销,因此也是衡量RTOS实时性能的一个重要指标。
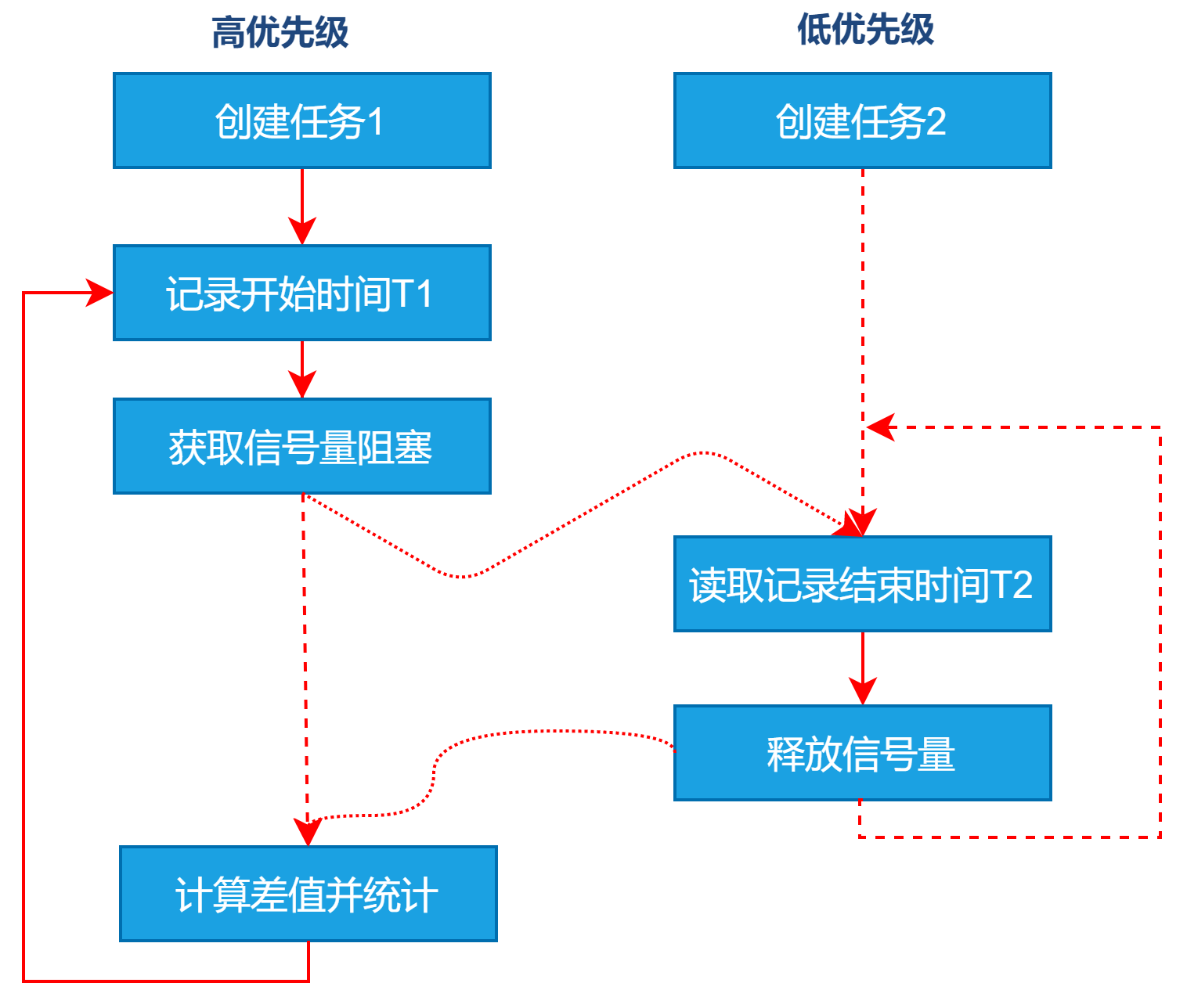
- bmCtxSempend
① 创建两个任务:高优先级任务$Task1$ 和 优先级任务$Task2$;
②$Task1$先非阻塞获取信号量,确保信号量为空。
③$Task1$记录当前时间T1,再次获取信号量导致挂起;
④ 上下文切换到低优先级任务$Task2$运行,$Task2$读取时间T2,再释放信号量;
⑤$Task1$得到信号量恢复运行。计算切换时间$T = T2 - T1$,反复进行②~⑤操作。
⑥最终统计最大值、最小值、平均值。
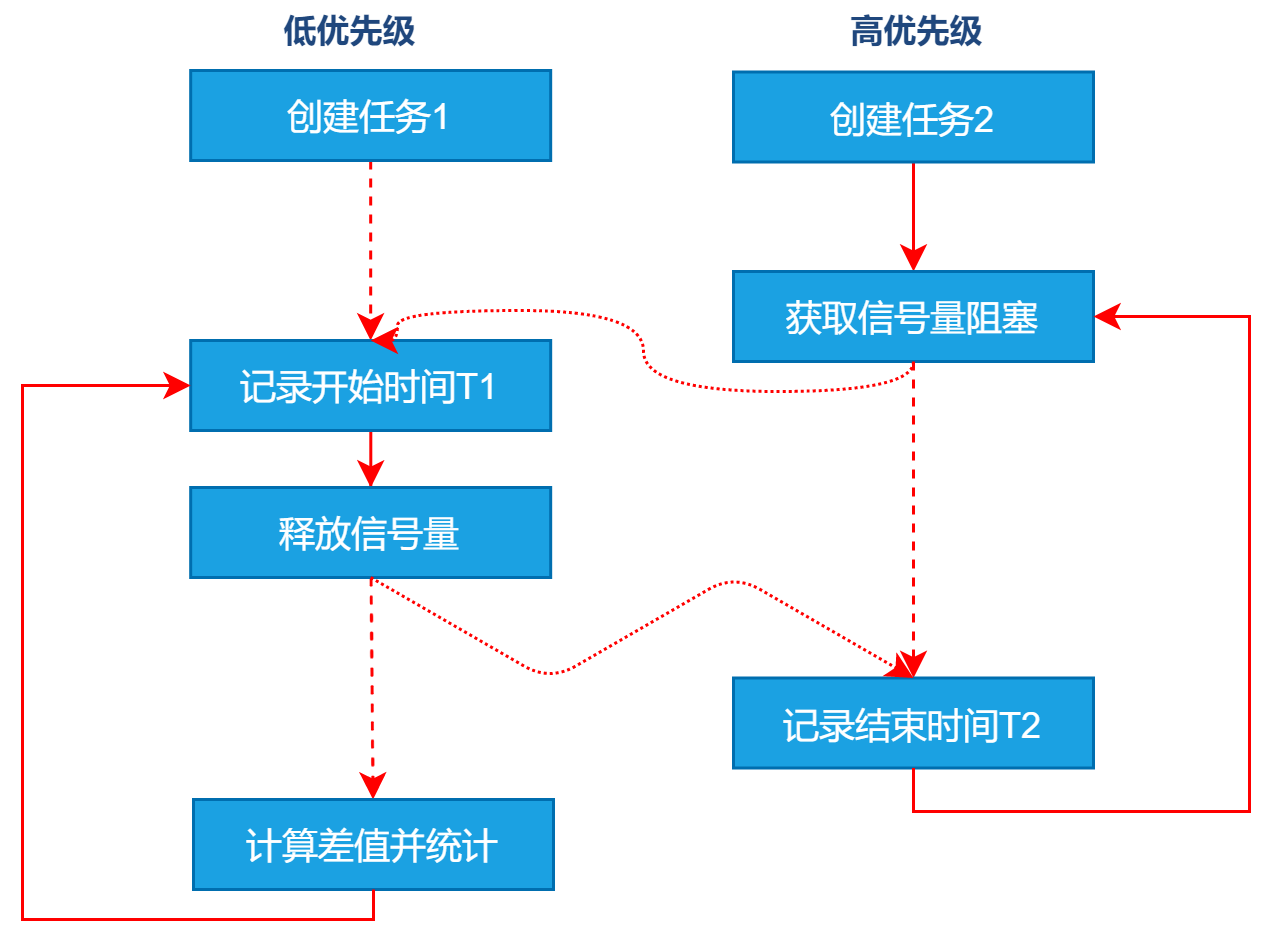
- bmCtxSemunpend
① 创建两个任务:高优先级任务$Task1$ 和 优先级任务$Task2$;
②$Task1$获取信号量导致挂起;
③上下文切换到低优先级任务$Task2$运行,$Task2$读取时间$T_1$,再释放信号量;
④ 高优先级$Task1$得到信号量恢复运行,读取时间$T_2$。进入下一次循环,反复进行②~⑤操作。
⑤ 最终统计最大值、最小值、平均值。
2.1.2 消息队列响应上下文切换时间
与信号量响应时间类似,是指从一个任务发送消息队列到另一个等待该消息队列的任务被激活的时间延迟。
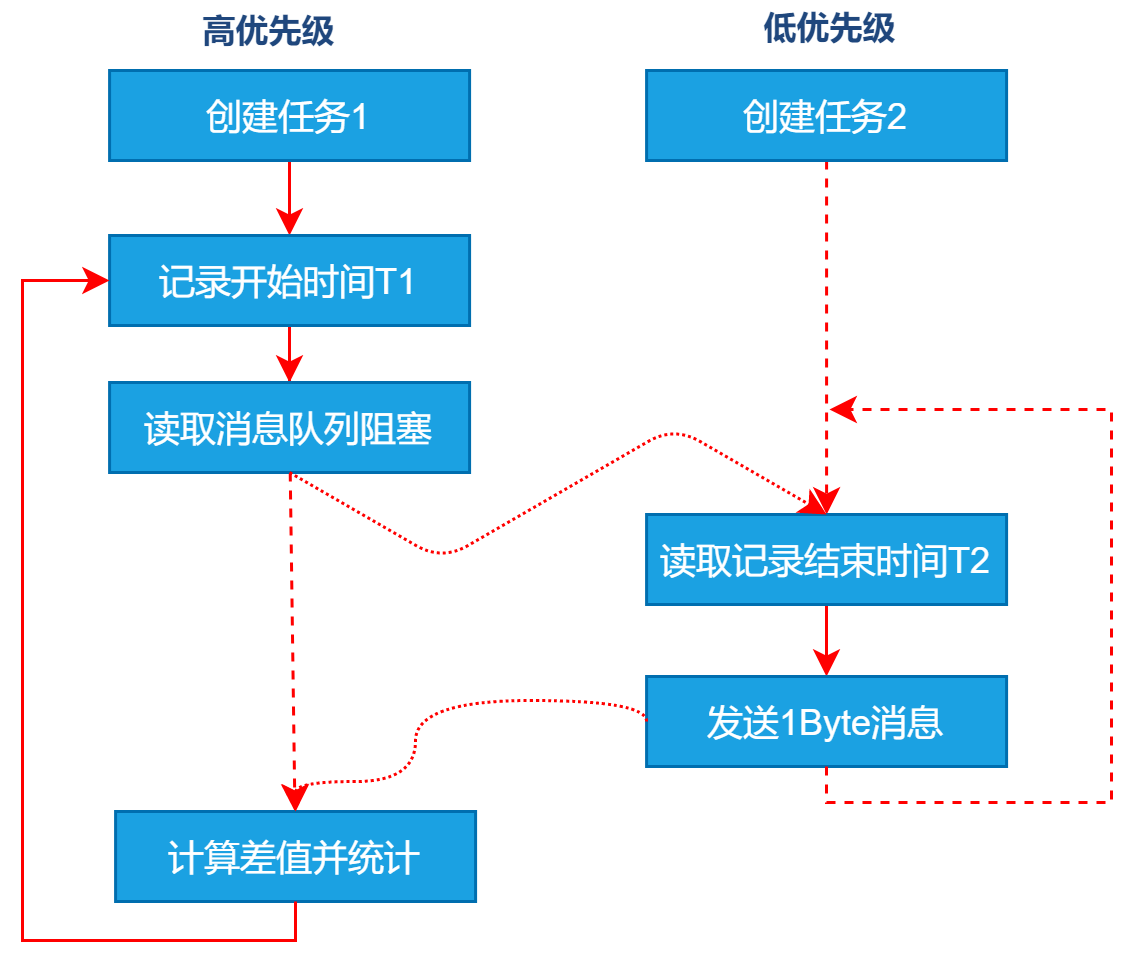
- bmCtxMsgQPend
① 创建两个任务:高优先级任务$Task1$ 和 优先级任务$Task2$;
② $Task1$记录当前时间T1,获取读取消息队列导致阻塞挂起;
③ 上下文切换到低优先级任务$Task2$运行,$Task2$读取时间T2,再向消息队列发送Byte数据,发送后阻塞;
④ $Task1$消息可用恢复运行。计算切换时间$T = T2 - T1$,反复进行②~⑤操作。
⑤ 最终统计最大值、最小值、平均值。
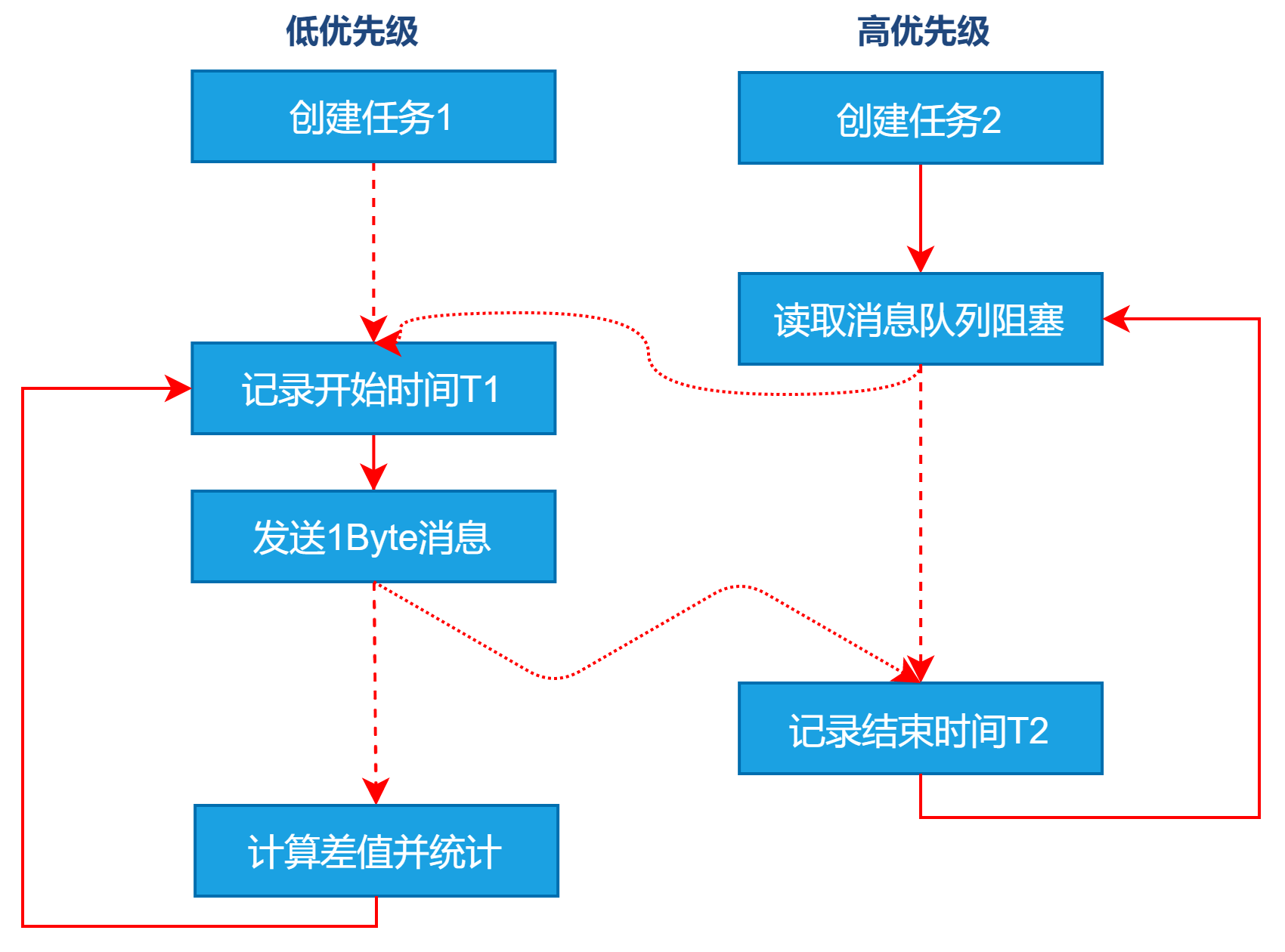
- bmCtxMsgQunPend
① 创建两个任务:高优先级任务$Task1$ 和 优先级任务$Task2$;
②$Task1$接收消息导致挂起;
③上下文切换到低优先级任务$Task2$运行,$Task2$读取时间T1,发送1Byte消息;
④ 高优先级$Task1$消息可用恢复运行,读取时间T2。进入下一次循环,反复进行②~⑤操作。
⑤ 最终统计最大值、最小值、平均值。
2.1.3 事件响应上下文切换时间
也就是对于event操作的上下文切换,与上面两种类似不再说明。
2.1.4 任务上下文切换时间
以上测试中,在资源上任务切换,下面是单纯的优先级调度下的任务切换。
需要注意的是:VxWorks中priority数值越高,优先级越低,xenomai相反。
① 优先级为50的任务$Task1$ 创建更高优先级40的任务$Task2$;
② $Task2$创建后立即抢占,$Task2$运行后立即降低自身优先级为60,比$Task1$优先级低
③$Task1$此时为最高优先级得到运行,读取时间T1,提升$Task2$优先级为40;
④ $Task2$此时为最高优先级抢占运行,发生一次上下文切换;
⑤ $Task2$运行后立即降低自身优先级为60;
⑥$Task1$此时为最高优先级得到运行,发生一次上下文切换;
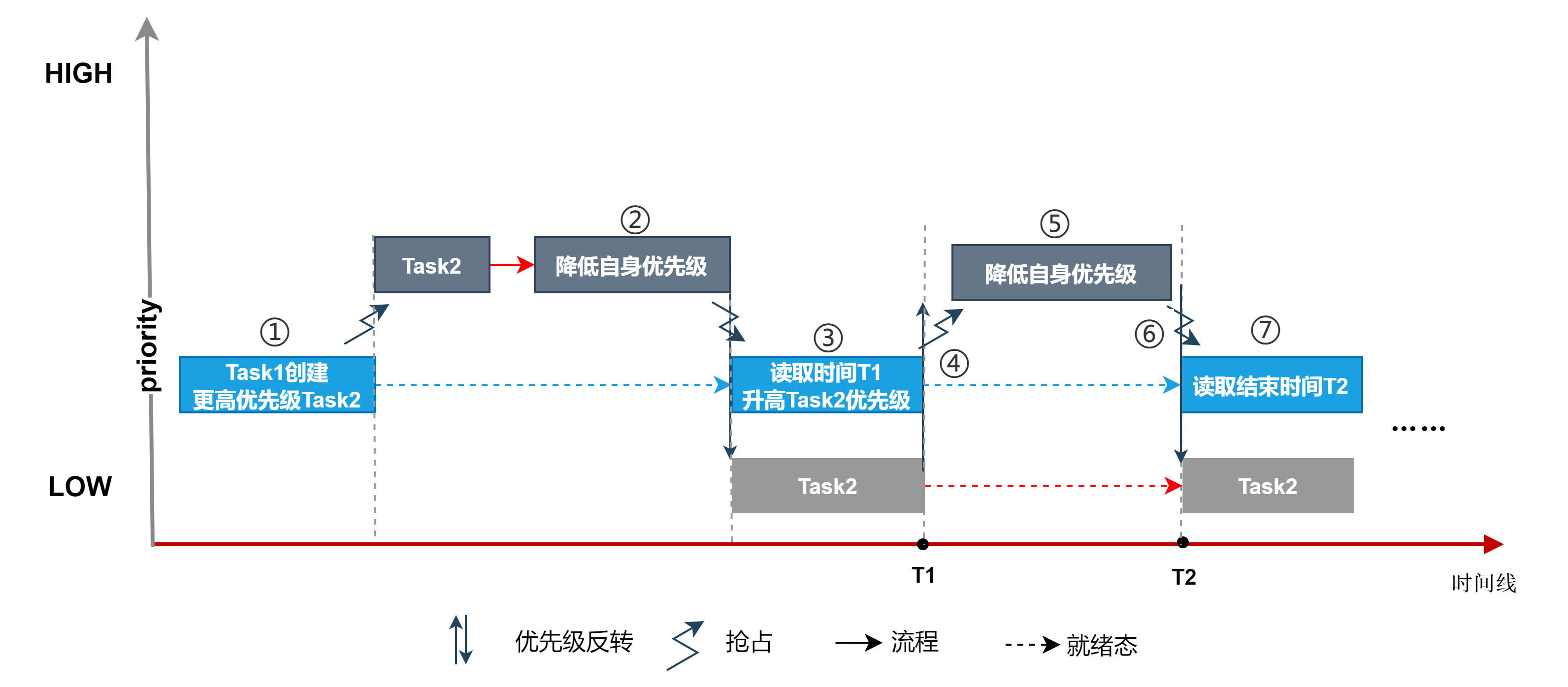
测试时间$T=T_2-T_1$,包含了1次提升优先级操作耗时$T_r$、1次降低优先级操作耗时$T_l$、2次任务切换$T_{sw}$、2次读取时间戳耗时$T_{rt}$。所以上下文切换时间$T_{sw}=\frac{T-T_r-T_l-2T_{rt}}{2}$。
2.1 SMP
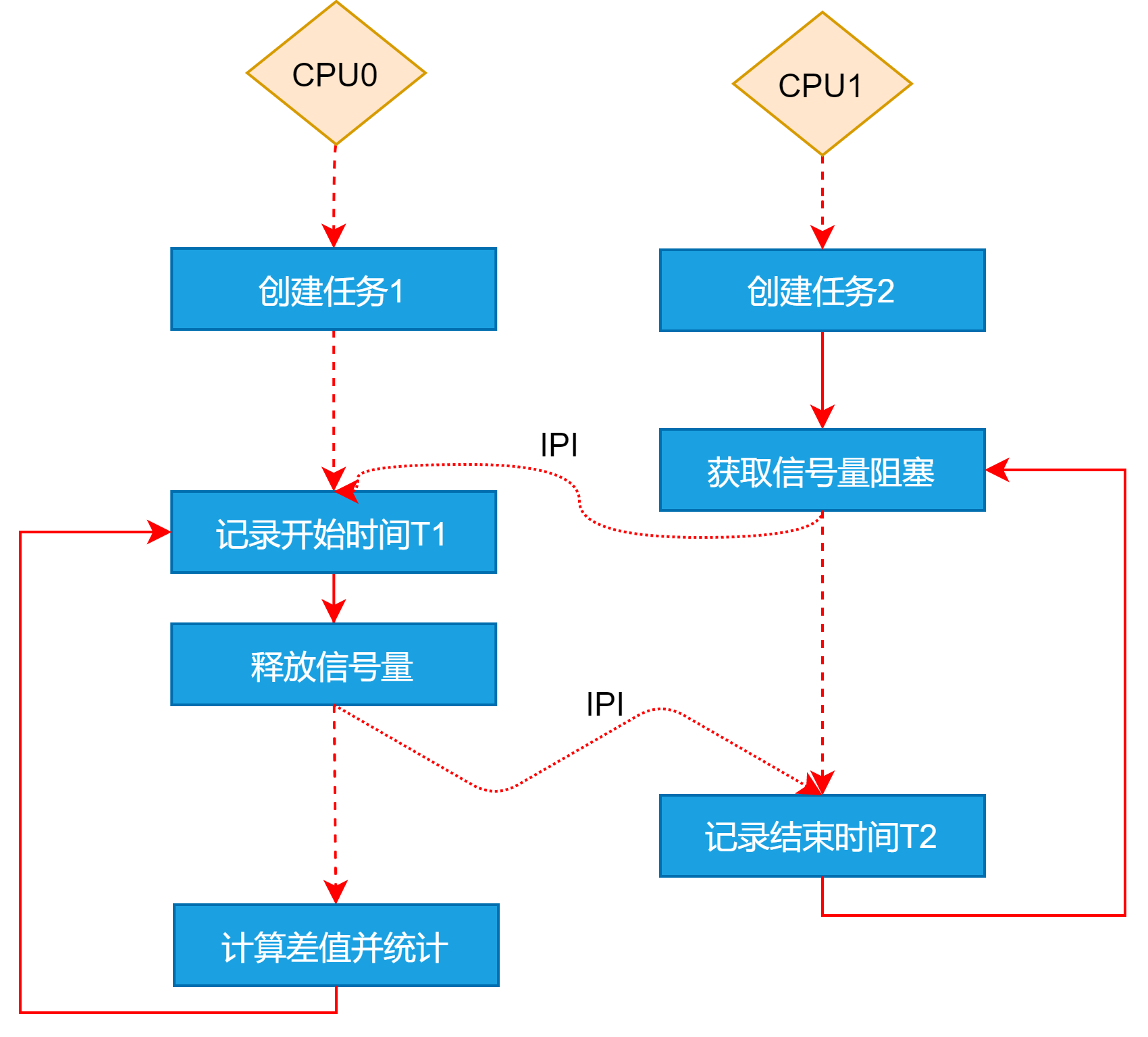
实时任务分别运行在不同CPU上,其任务切换在上述的基础上,还包含了多核间IPI 通信(Interrupt-Procecesorr Interrupt处理器间的中断)耗时。
以bmCtxSemunpend示例如下,其余的类似不再赘述。
三、 结果对比
3.1 单核
| Vxworks | avg | min | max |
|---|---|---|---|
| bmCtxSemPend | 1.387 | 0.162 | 5.205 |
| bmCtxSemUnpend | 1.389 | 0.162 | 5.205 |
| bmCtxMsgQPend | 1.719 | 0.325 | 6.181 |
| bmCtxMsgQUnpend | 2.183 | 0.487 | 7.807 |
| bmCtxEventPend | 1.349 | 0.000 | 5.042 |
| bmCtxEventUnpend | 1.466 | 0.162 | 5.367 |
| bmCtxTaskSwitch | 0.975 | 0.000 | 4.635 |
| Xenomai | avg | min | max |
|---|---|---|---|
| bmCtxSemPend | 3.597 | 3.252 | 6.345 |
| bmCtxSemUnpend | 3.735 | 3.415 | 7.482 |
| bmCtxMsgQPend | 4.228 | 3.903 | 6.833 |
| bmCtxMsgQUnpend | 5.368 | 5.042 | 8.622 |
| bmCtxEventPend | - | - | - |
| bmCtxEventUnpend | - | - | - |
| bmCtxTaskSwitch | 8.365 | 0.326 | 63.522 |
可以看到xenomaibmCtxTaskSwitch数据比较差,为什么什么会这样呢?VxWorks测试程序与内核都处于内核态(同一地址空间),而xenomai测试则是在用户态测试,可以回到2.1.4小节,其中$T=T_2-T_1$这段时间内的每一个操作都是必须发起实时系统调用来完成的,其中修改优先级还涉及Linux线程部分,除此之外由于系统调用路径复杂,每个系统调用时间不是确定的,比如前后两次修改优先级操作的时间是不等的,这就造成计算出的$T_{sw}$失真。通俗的说这个测试方法不适合xenomai用户态,将该测试放到xenomai内核态才与VxWorks具有可比性。
另外,本测试基于xenomai 3.1。xenomai任务对event资源不会发生阻塞唤醒(非抢占)了,xenomai3.0.8不存在这个问题,所以这两项没有测试数据。有兴趣的小伙伴可以研究一下,顺便还能向社区提个issue或patch,呵呵~~。
3.2 SMP
VxWorks没有启用SMP,所以这部分没有VxWorks的数据,只有xenomai的。
| Xenomai | avg | min | max |
|---|---|---|---|
| CtxSmpAffinitySemUnPend | 3.826 | 3.578 | 8.296 |
| CtxSmpAffinityMsgQUnPend | 5.262 | 4.879 | 8.133 |
| CtxSmpNoAffinitySemUnPend | 3.766 | 3.415 | 6.181 |
| CtxSmpNoAffinityMsgQUnPend | 5.322 | 5.042 | 9.597 |
【原创】xenomai与VxWorks实时性对比(资源抢占上下文切换对比)的更多相关文章
- 【原创】xenomai与VxWorks实时性对比(Jitter对比)
版权声明:本文为本文为博主原创文章,转载请注明出处.如有问题,欢迎指正.博客地址:https://www.cnblogs.com/wsg1100/ (下面数据,仅供个人参考) 可能大部分人一直好奇Vx ...
- 【原创】有利于提高xenomai 实时性的一些配置建议
版权声明:本文为本文为博主原创文章,转载请注明出处.如有错误,欢迎指正. @ 目录 一.影响因素 1.硬件 2.BISO(X86平台) 3.软件 4. 缓存使用策略与GPU 二.优化措施 1. BIO ...
- 【原创】ARM平台内存和cache对xenomai实时性的影响
目录 1. 问题概述 2. stress 内存压力原理 2. cache 因素 2.1 未加压 2.2 加压(cpu/io) 3. 内存管理因素 3.1 内存分配/释放 3.2 MMU拥塞 4 总结 ...
- 【原创】xenomai内核解析--实时内存管理--xnheap
目录 一. xenomai内存池管理 1.xnheap 2. xnpagemap 3. xnbucket 4. xnheap初始化 5. 内存块分配 5.1 小内存分配流程(<= 2*PAGE_ ...
- 【原创】xenomai内核解析--实时IPC概述
版权声明:本文为本文为博主原创文章,转载请注明出处.如有问题,欢迎指正.博客地址:https://www.cnblogs.com/wsg1100/ 目录 1.概述 2.Real-time IPC 2. ...
- 为树莓派添加一个强实时性前端[原创cnblogs.com/helesheng]
树莓派是最近流行嵌入式平台,其自由的开源特性以及低廉的价格,吸引了来 自全球的大量极客和计算机大咖的关注.来自各大树莓派社区的幕后英雄,无私地在这个开源硬件平台上做了大量的工作,将其打造成了世界上通用 ...
- Linux操作系统实时性分析
1. 概述 选择一个合适的嵌入式操作系统,可以考虑以下几个因素: 第一是应用.如果你想开发的嵌入式设备是一个和网络应用密切相关或者就是一个网络设备,那么你应该选择用嵌入式Linux或者uCLinux ...
- Linux 2.6 内核实时性分析 (完善中...)
经过一个月的学习,目前对linux 下驱动程序的编写有了入门的认识,现在需要着手实践,编写相关的驱动程序. 因为飞控系统对实时性有一定的要求,所以先打算学习linux 2.6 内核的实时性与任务调 ...
- vxworks 实时操作系统
VxWorks 是美国 Wind River System 公司( 以下简称风河公司 ,即 WRS 公司)推出的一个实时操作系统.Tornado 是WRS 公司推出的一套实时操作系统开发环境,类似Mi ...
随机推荐
- mysql Unknown error 1146
错误提示:Couldn't acquire next trigger: Unknown error 1146 spring +quartz 实现任务调度,由于quartz 默认读取表名为大写,新建数据 ...
- day76 vue框架入门
目录 一.vue.js快速入门使用 1 vue.js库的下载 2 vue.js库的使用 3 vue.js的M-V-VM思想 4 显示数据 二.常用指令 1 操作属性 2 事件的绑定 3 样式操作 3. ...
- day27 面向对象
day27 面向对象 目录 day27 面向对象 一.面相对象介绍 1 什么是对象 2 类于对象 二.实现面向对象编程 1 先定义类 2 属性访问 2.1 调用dict方法 2.2 类.属性 3 调用 ...
- 二、python 中五种常用的数据类型
一.字符串 单引号定义: str1 = 'hello' 双引号定义: str1 = "hello" 三引号定义:""" 人生苦短, 我用python! ...
- python网络编程05 /TCP阻塞机制
python网络编程05 /TCP阻塞机制 目录 python网络编程05 /TCP阻塞机制 1.什么是拥塞控制 2.拥塞控制要考虑的因素 3.拥塞控制的方法: 1.慢开始和拥塞避免 2.快重传和快恢 ...
- python 装饰器(六):装饰器实例(三)内置装饰器
内置的装饰器和普通的装饰器原理是一样的,只不过返回的不是函数,而是类对象,所以更难理解一些. @property 在了解这个装饰器前,你需要知道在不使用装饰器怎么写一个属性. def getx(sel ...
- Shaderlab-10chapter-立方体纹理、玻璃效果
10.1.1天空盒子 window - Lighting - skyMaterial 创建mat,shader选自带的6 side shader 确保相机选skybox 如果某个相机需要覆盖,添加sk ...
- unity-疑难杂症(一)
1.使用odin插件序列化,当出现预制体有引用类型的关联, 拖到scene就没关联时,可右键预制体--Reimport解决. 2.类似问题1,脚本组件关联AudioMixer,拖到scene没有关联, ...
- JVM系列-方法调用的原理
JVM系列-方法调用的原理 最近重新看了一些JVM方面的笔记和资料,收获颇丰,尤其解决了长久以来心中关于JVM方法管理的一些疑问.下面介绍一下JVM中有关方法调用的知识. 目的 方法调用,目的是选择方 ...
- 集训作业 洛谷P1433 吃奶酪
嗯?这题竟然是个绿题. 这个题真的不难,不要被他的难度吓到,我们只是不会计算2点之间的距离,他还给出了公式,这个就有点…… 我们直接套公式去求出需要的值,然后普通的搜索就可以了. 这个题我用的深搜,因 ...