1DadaFrame和Series创建
通过GroupBy创建DF对象
sn_group=data.groupby('SN')
purchase_count=sn_group.count().Price
average_purchase_price=sn_group.mean().Price.round(2)
total_purchase_price=sn_group.sum().Price
spender_summary=pd.DataFrame({"Purchase Count":purchase_count,
"Average Purchase":average_purchase_price,
"Total Purchase Value":total_purchase_price})
spender_summary.sort_values('Total Purchase Value',ascending=False,inplace=True)
spender_summary.head(10)
注意:purchase_count和average_purchase_price、total_purchase_price都是Series对象,并且它们的index都是一样的
第二种处理Series组成一个DF
#Age Demographics
age_bins = [0, 9, 14, 19, 24, 29, 34, 39, 100]
group_labels = ["<10", "10-14", "15-19", "20-24", "25-29", "30-34", "35-39", "40+"]
#9个数字 8个区间
data['Age_group']=pd.cut(data.Age,age_bins,labels=group_labels) #后面增加一列Age_group 原始数据780行就增加780个年龄区间
age_groupy=data.groupby('Age_group')
age_df=age_groupy["SN"].nunique()
age_df.name='Total Count' #age_df和age_percent_df的name都是SN所以要改为不同的名字作为列名
age_df #Series类型
age_percent_df=round((age_df/age_df.sum())*100,2)
age_percent_df.name='%Percentage of Players' avg_purchase_price=age_groupy['Price'].mean()#等价avg_purchase_price=age_groupy.mean().Price avg_purchase_price=age_groupy.mean()是一个DF对象
avg_purchase_price.name='avg_purchase_price'
total_purchase_price=age_groupy['Price'].sum()
total_purchase_price.name='total_purchase_price' summary_age_df=pd.concat([age_df,age_percent_df,avg_purchase_price,total_purchase_price],axis=1) #列拼接
summary_age_df.reset_index(inplace=True)
任意举出一个age_groupy.nunique()就是DF的例子 。age_groupy.mean();age_groupy.count()...都是一个DF

把不同的字段组成一个DF,各项之间没有关系,字段用[]阔起来,外面是一个字典{}
#Number of Unique Items
unique_items=data['Item ID'].nunique() #Average Purchase Price
avg_purchase=data.Price.mean() #Total Number of Purchases
total_purchases=data.SN.count() #Total Revenue
total_revenue=data.Price.sum() summary_df = pd.DataFrame({"Number of Unique Items":[unique_items],
"Average Price":[avg_purchase],
"Number of Purchases":[total_purchases],
"Total Revenue":[total_revenue]})
summary_df

列表list[]转为DF 形如[(),(),(),]列表里面套元组形式
#Gender Demographics 性别特征
def gender_Percentage1(gender,):
gender_count=data.loc[data.Gender==gender,'SN'].nunique()
gender_perc = ((gender_count/total_count)*100)
return gender,gender_count,gender_perc gender_laberls=np.sort(data.Gender.unique()).tolist()
total_count=data.SN.nunique()
result=[]
for gender in gender_laberls:
result.append(gender_Percentage1(gender))
gender_df1=pd.DataFrame(result,columns = ["Gender", "Total Count", "%Percentage of Players"])
gender_df1

最简单的通过字典创建DF
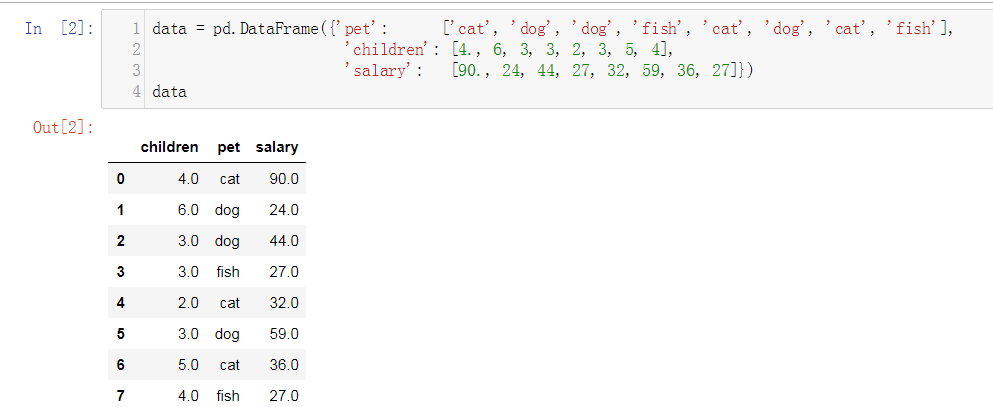
单个字典创建一个DF
Genre_temp=data.Genre.str.split(',').tolist() #[[],[],[]...]
genre_list=[i for j in Genre_temp for i in j] #里面有重复的但是没关系
import nltk
fdist=nltk.FreqDist(genre_list)
df=pd.DataFrame(fdist,index=[0]) #index=[0]一定要加一个索引是不是0无所谓
#df.T转置看起来更舒服一点
#genre=pd.Series(fdist).sort_values(ascending=False) #dist-->pd.Series 其实单个字典转为Series好一点

1DadaFrame和Series创建的更多相关文章
- Series 入门(创建和增删改查)
Series 是pandas两大数据结构中(DataFrame,Series)的一种.使用pandas 前需要将pandas 模块引入,因为Series和DataFrame用的次数非常多,所以将其引入 ...
- Pandas 数据结构Series:基本概念及创建
Series:"一维数组" 1. 和一维数组的区别 # Series 数据结构 # Series 是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象 ...
- Pandas 0 数据结构Series
# -*- encoding:utf-8 -*- # Copyright (c) 2015 Shiye Inc. # All rights reserved. # # Author: ldq < ...
- 02. Pandas 1|数据结构Series、Dataframe
1."一维数组"Series Pandas数据结构Series:基本概念及创建 s.index . s.values # Series 数据结构 # Series 是带有标签的一 ...
- pandas.Series
1.系列(Series)是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组.轴标签统称为索引. Pandas系列可以使用以下构造函数创建 - pandas.Series ...
- Pandas之Series
# Series 数据结构 # Series 是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象等),轴标签统称为索引 import numpy as np impor ...
- Python笔记7----Pandas中变长字典Series
1.Series概念 类似一维数组的对象,由数据和索引组成 2.Series创建 用Series()函数创建,0,1,2为series结构自带的索引. 可以自己指定索引值,用index,也可以直接用字 ...
- pandas基础:Series与DataFrame操作
pandas包 # 引入包 import pandas as pd import numpy as np import matplotlib.pyplot as plt Series Series 是 ...
- pandas-21 Series和Dataframe的画图方法
pandas-21 Series和Dataframe的画图方法 ### 前言 在pandas中,无论是series还是dataframe都内置了.plot()方法,可以结合plt.show()进行很方 ...
随机推荐
- 027_go语言中的通道选择器
代码演示 package main import "fmt" import "time" func main() { c1 := make(chan strin ...
- ReentrantLock与synchronized 源码解析
一.概念及执行原理 在 JDK 1.5 之前共享对象的协调机制只有 synchronized 和 volatile,在 JDK 1.5 中增加了新的机制 ReentrantLock,该机制的诞生并 ...
- golang 浮点型
目录 前言 1.三要素 2.表现形式 3.类型 4.精度 5.格式化 6.使用细节 跳转 前言 不做文字的搬运工,多做灵感性记录 这是平时学习总结的地方,用做知识库 平时看到其他文章的相关知识,也会增 ...
- 如何隐藏win32 控制台程序的console窗口 2011-06-17 17:59
加上 即可 // 隐藏窗口#pragma comment(linker, "/subsystem:\"windows\" /entry:\"mainC ...
- eric4 中pyqt 字符串 输入 获取
在eric4中使用pyqt需要注意: 输入 中文 时,前面加 u ,例如: from PyQt4.QtGui import * from PyQt4.QtCore import * QMessageB ...
- python去除 数据的 重复行
原文链接:https://www.cnblogs.com/loren880898/p/11303672.html
- elasticsearch java工具类
docker运行elasticsearch docker pull elasticsearch:7.8.1 docker run -p 9200:9200 -p 9300:9300 -e " ...
- java+opencv实现图像灰度化
灰度图像上每个像素的颜色值又称为灰度,指黑白图像中点的颜色深度,范围一般从0到255,白色为255,黑色为0.所谓灰度值是指色彩的浓淡程度,灰度直方图是指一幅数字图像中,对应每一个灰度值统计出具有该灰 ...
- Swing记事本项目
具备记事本功能:文件保存.文件打开.复制.黏贴.撤销.全选.字体修改.字体颜色修改.背景颜色修改
- redis 过期策略你知道多少,看完文章你会不自觉说喔哦
Redis 所有的数据结构都可以设置过期时间,时间一到,就会自动删除.你可以想象 Redis 内部有一个死神,时刻盯着所有设置了过期时间的 key,寿命一到就会立即收割. 你还可以进一步站在死神的角度 ...