常用RDD
只作为我个人笔记,没有过多解释
Transfor
map
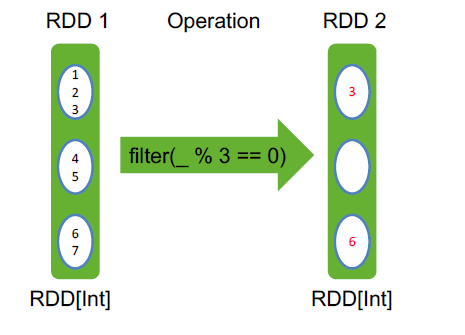
filter filter之后,依然有三个分区,第二个分区为空,但不会消失
flatMap
reduceByKey
groupByKey()
sortByKey()
val pets = sc.parallelize(
List((“cat”, 1), (“dog”, 1), (“cat”, 2))
)
pets.reduceByKey(_ + _) // => {(cat, 3), (dog, 1)}
pets.groupByKey() // => {(cat, Seq(1, 2)), (dog, Seq(1)}
pets.sortByKey() // => {(cat, 1), (cat, 2), (dog, 1)}
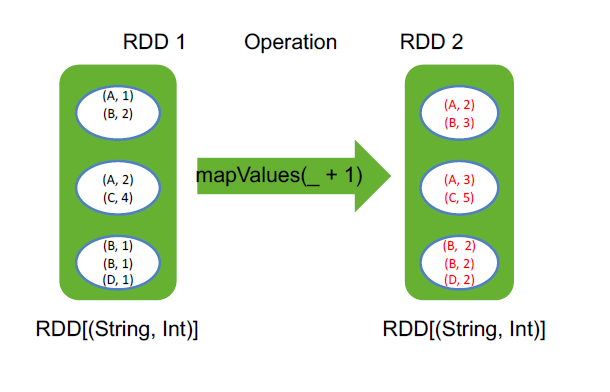
mapValues(_ + 1) mapvalues是忽略掉key,只把value进行操作
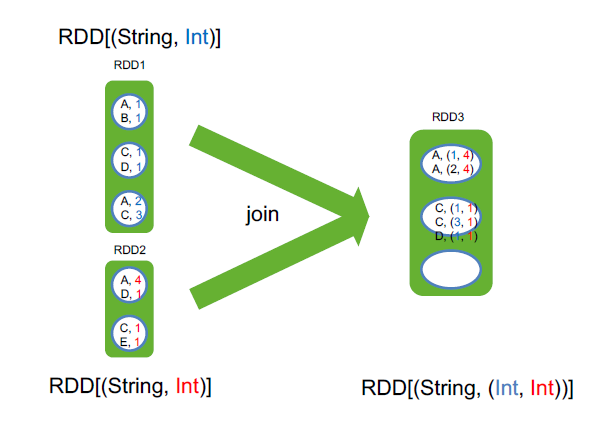
join RDD[(String, Int)].join(RDD[(String, Long)]) => RDD[(String, (Int, Long))]
join这两个rdd的value类型可以不一样,至于分区是根据hash来指定的
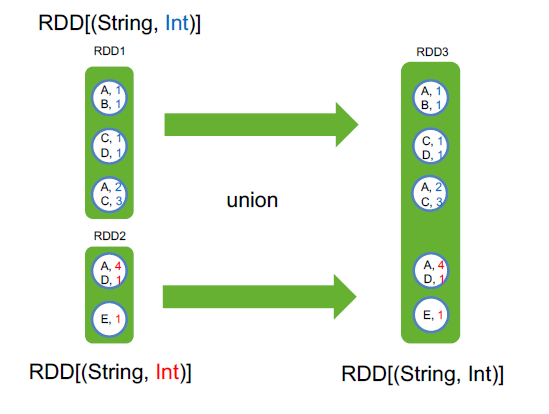
union
cogroup

用 cogroup 实现 join


sample() 从数据集中采样
cartesian() 求笛卡尔积
pipe() 传入一个外部程序
coalesce(口莱斯) 合并一个RDD的分区
rdd4 = rdd1 ++ rdd2 ++ rdd3
rdd4.coalesce(3)
rdd4.coalesce(3,true)
repartition 合并分区 rdd3.repartition(10)
并不是真的将分区合并,而是让一个task处理多个分区,如1k、10k、100k、1m、10m这五种文件,一共10w个,在hdfs上会有10w个block,取数据的时候会有10w个分区,同样有10w个task,这并不合适,如果能将这些分区合并,比如有10个task,每个task读1w个文件,速度会快很多,这个时候,有两种合并方式,coalesce和repartition
coalesce优点是简单粗暴,合并分区速度很快,缺点是很可能每个task所处理的数据不均匀。如果文件天生是比较均匀的,那coalesce合适
repartition优点是合并很均匀,用的是归并排序,缺点是计算开销比较大
举例,repartition合并的方法,10w个文件如何均匀的分成3个分区?
将每个文件均匀分成3分份,然后每一个分区从每个文件中拿一份
zip 将两个RDD的元素一一映射,合在一起
Action
collect()
take(2)
count()
reduce
foreach(println)
常用RDD的更多相关文章
- 08、Spark常用RDD变换
08.Spark常用RDD变换 8.1 概述 Spark RDD内部提供了很多变换操作,可以使用对数据的各种处理.同时,针对KV类型的操作,对应的方法封装在PairRDDFunctions trait ...
- 04、常用RDD操作整理
常用Transformation 注:某些函数只有PairRDD只有,而普通的RDD则没有,比如gropuByKey.reduceByKey.sortByKey.join.cogroup等函数要根据K ...
- Spark常用RDD操作总结
aggregate 函数原型:aggregate(zeroValue, seqOp, combOp) seqOp相当于Map combOp相当于Reduce zeroValue是seqOp每一个par ...
- 033 Java Spark的编程
1.Java SparkCore编程 入口是:JavaSparkContext 基本的RDD是:JavaRDD 其他常用RDD: JavaPairRDD JavaRDD和JavaPairRDD转换: ...
- Spark常用函数讲解之键值RDD转换
摘要: RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集RDD有两种操作算子: Trans ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark 系列(四)—— RDD常用算子详解
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
- spark学习(10)-RDD的介绍和常用算子
RDD(弹性分布式数据集,里面并不存储真正要计算的数据,你对RDD的操作,他会在Driver端转换成Task,下发到Executor计算分散在多台集群上的数据) RDD是一个代理,你对代理进行操作,他 ...
- sparkRDD:第3节 RDD常用的算子操作
4. RDD编程API 4.1 RDD的算子分类 Transformation(转换):根据数据集创建一个新的数据集,计算后返回一个新RDD:例如:一个rdd进行map操作后生了一个新的rd ...
随机推荐
- 让iOS应用支持不同版本的系统与设备
本文转载至 http://blog.csdn.net/pucker/article/details/11980811 最近一直在做app的iOS 6和7的同时适配工作,所以在此介绍一下系统与设备的兼 ...
- height:calc(100% - 40px)
在移动端开发的过程中,常常会遇到头部高度是40px,而内容页是除去头部,占满视窗的整个高度,有时候是用js来处理,现在用css的calc是非常方便的: .container{ height: calc ...
- fopen与读写的标识r,r+,rb+,rt+,w+.....
FILE * fopen(const char * path,const char * mode); 参数mode字符串则代表着流形态. mode有下列几种形态字符串: r 打开只读文件,该文件必须存 ...
- PMP十大知识领域整理
2018-7-28至2018-12-8历时4个多月,学写了PMP(拍马屁),感觉自己经历了,哇-唉-哦-嗯这四个阶段 刚开始觉得如遇圣经,被PMP的知识体系和老师的精彩课程深深震撼! 后来觉得很多东西 ...
- 【BZOJ1495】[NOI2006]网络收费 暴力+DP
[BZOJ1495][NOI2006]网络收费 Description 网络已经成为当今世界不可或缺的一部分.每天都有数以亿计的人使用网络进行学习.科研.娱乐等活动.然而,不可忽视的一点就是网络本身有 ...
- angular 4 路由变化的时候实时监测刷新组件
当路由变化的时候刷新组件 比如说要刷新header组件 在header.ts里 import {Router, NavigationEnd} from "@angular/router&qu ...
- MongoDB插入多条数据
刚开始学mongodb,只知道几个命令,insert插入也只能一条一条插入,而在实际情况下数据一般都非常多,刚开始想直接上传json文件,网上搜了n多方法发现这种方法不好弄,然后就想着要么一下子把多条 ...
- HDU 1866 A + B forever!
A + B forever! Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) T ...
- IIS6中给Framework2,。0站点的虚拟目录(2.0版本)下发布Web API项目(4.0版本)问题处理
Web-API项目以虚拟目录形式部署到IIS6/IIS7 若原有站点为Framework2.0版本,在此站点(或虚拟目录站点)下,新增API虚拟目录,然后选择Framework4.0版本,IIS6和I ...
- hdu4686 简单的矩阵快速幂求前n项和
HDU4686 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4686 题意:题目说的很清楚了,英语不好的猜也该猜懂了,就是求一个表达式的前n项和,矩阵 ...