Kruskal-Wallis test
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

项目联系QQ:231469242
https://github.com/thomas-haslwanter/statsintro_python/tree/master/ISP/Code_Quantlets/08_TestsMeanValues/kruskalWallis
# -*- coding: utf-8 -*-
import numpy as np
# additional packages
from scipy.stats.mstats import kruskalwallis
'''
.. currentmodule:: scipy.stats.mstats
This module contains a large number of statistical functions that can
be used with masked arrays.
Most of these functions are similar to those in scipy.stats but might
have small differences in the API or in the algorithm used. Since this
is a relatively new package, some API changes are still possible.
'''
# Get the data
'''
#These data could be a comparison of the smog levels in four different cities.
city1 = np.array([68, 93, 123, 83, 108, 122])
city2 = np.array([119, 116, 101, 103, 113, 84])
city3 = np.array([70, 68, 54, 73, 81, 68])
city4 = np.array([61, 54, 59, 67, 59, 70])
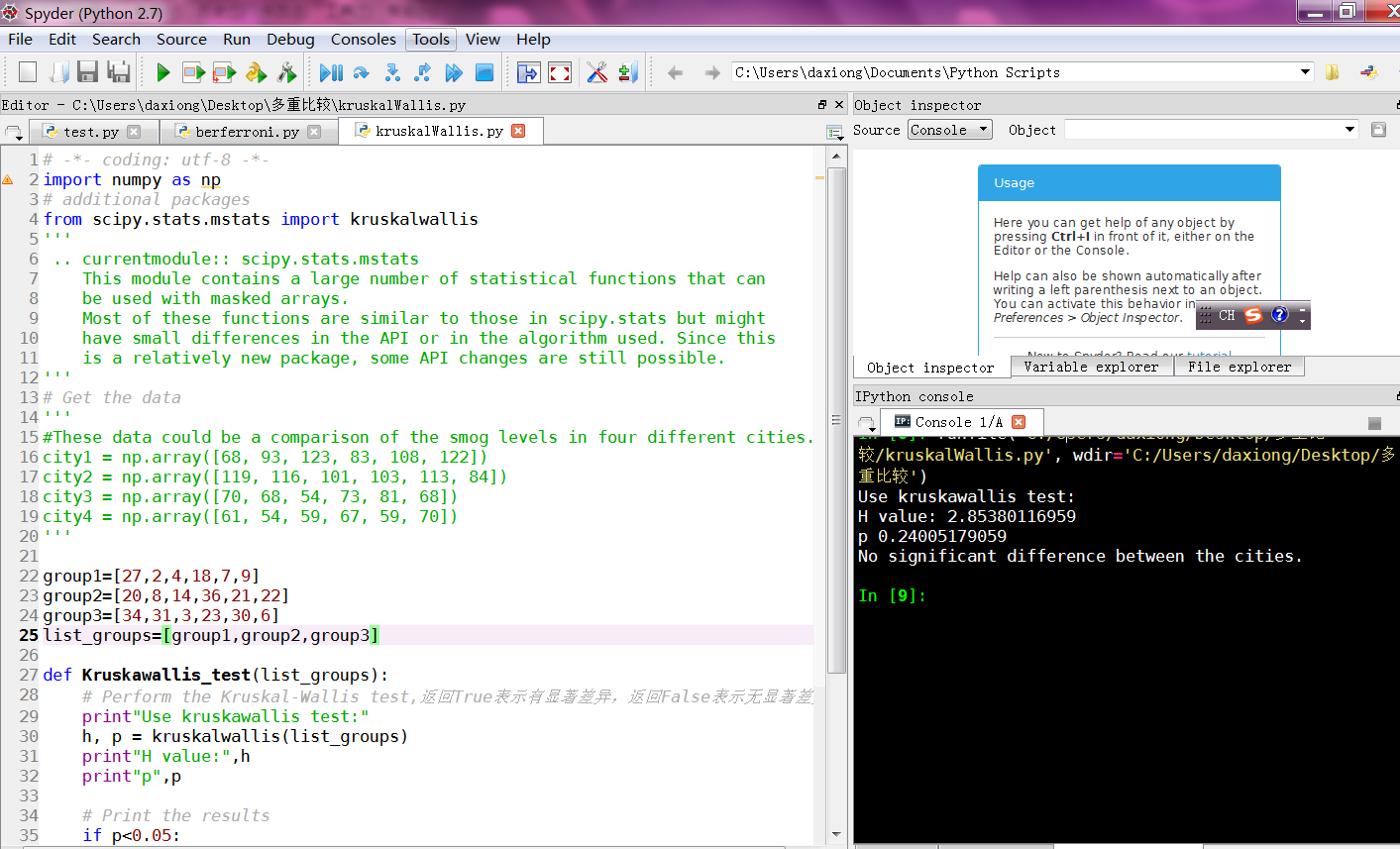
''' group1=[27,2,4,18,7,9]
group2=[20,8,14,36,21,22]
group3=[34,31,3,23,30,6]
list_groups=[group1,group2,group3] def Kruskawallis_test(list_groups):
# Perform the Kruskal-Wallis test,返回True表示有显著差异,返回False表示无显著差异
print"Use kruskawallis test:"
h, p = kruskalwallis(list_groups)
print"H value:",h
print"p",p # Print the results
if p<0.05:
print('There is a significant difference between the cities.')
return True
else:
print('No significant difference between the cities.')
return False Kruskawallis_test(list_groups)
当样本数据非正态分布,两组数对比时用mann-whitney检验,三组或更多时用kruskal-wallis检验

kruskal-wallis 是一个独立单因素方差检验的版本
kruskal-wallis能用于排序计算

样本数据
流程

H0和H1假设

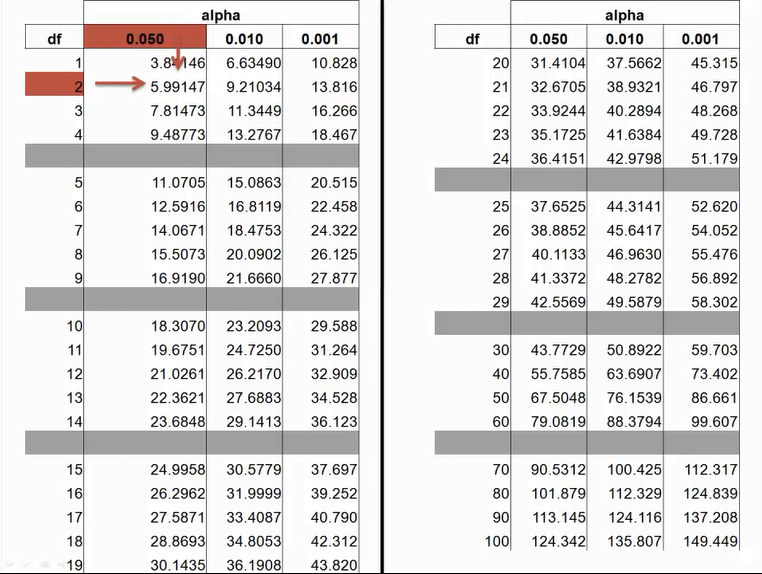
自由度:组数-1,这里有三组,自由度为3-=2

自由度为2,a=0.05,对应得关键值5.99,如果计算的值大于5.99,拒绝原假设

对数据排序,然后把对应得排序填入表内

计算公式:
T为一组的排序之和
n为一组的个数

计算的H值2.854小于5.99,不拒绝原假设

python信用评分卡建模(附代码,博主录制)

Kruskal-Wallis test的更多相关文章
- R in action读书笔记(7)-第七章:基本统计分析(下)
7.3相关 相关系数可以用来描述定量变量之间的关系.相关系数的符号(±)表明关系的方向(正相关或负相关),其值的大小表示关系的强弱程度(完全不相关时为0,完全相关时为1).除了基础安装以外,我们还将使 ...
- R语言-组间差异的非参数检验
R语言-组间差异的非参数检验 7.5 组间差异的非参数检验 如果数据无法满足t检验或ANOVA的参数假设,可以转而使用非参数方法.举例来说,若结果变量在本质上就严重偏倚或呈现有序关系,那么你可能会希望 ...
- PP: Time series clustering via community detection in Networks
Improvement can be done in fulture:1. the algorithm of constructing network from distance matrix. 2. ...
- 吴裕雄--天生自然 R语言开发学习:基本统计分析(续三)
#---------------------------------------------------------------------# # R in Action (2nd ed): Chap ...
- 吴裕雄--天生自然 R语言开发学习:基本统计分析
#---------------------------------------------------------------------# # R in Action (2nd ed): Chap ...
- 图的生成树(森林)(克鲁斯卡尔Kruskal算法和普里姆Prim算法)、以及并查集的使用
图的连通性问题:无向图的连通分量和生成树,所有顶点均由边连接在一起,但不存在回路的图. 设图 G=(V, E) 是个连通图,当从图任一顶点出发遍历图G 时,将边集 E(G) 分成两个集合 T(G) 和 ...
- 最小生成树---Prim算法和Kruskal算法
Prim算法 1.概览 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树.意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (gra ...
- 最小生成树(prim&kruskal)
最近都是图,为了防止几次记不住,先把自己理解的写下来,有问题继续改.先把算法过程记下来: prime算法: 原始的加权连通图——————D被选作起点,选与之相连的权值 ...
- Kruskal 最小生成树算法
对于一个给定的连通的无向图 G = (V, E),希望找到一个无回路的子集 T,T 是 E 的子集,它连接了所有的顶点,且其权值之和为最小. 因为 T 无回路且连接所有的顶点,所以它必然是一棵树,称为 ...
- 权重最小生成树的思想与Kruskal算法
晚上做携程的笔试题,附加题考到了权重最小生成树.OMG,就在开考之前,我还又看过一遍这内容,可因为时间太紧,也从来没有写过代码,就GG了.又吃了眼高手低的亏.这不,就好好总结一下,亡羊补牢. 权重最小 ...
随机推荐
- [T-ARA][너 때문에 미쳐][因为你而疯了]
歌词来源:http://music.163.com/#/song?id=5402880 作曲 : 赵英秀/김태현 [作曲 : 赵英秀/k/gim-Tae-hyeon] 作词 : 辉星 [作词 : 辉星 ...
- java-sun.misc.BASE64Decode AccessException
在使用sun.misc中base64类时,eclipse可能会报找不到Access异常 只需要修改一下访问方式即可,如下: 右键项目->属性->Javabulid path->jre ...
- python实现中文验证码识别方法(亲测通过)
验证码截图如下: # coding:utf-8from PIL import Image,ImageEnhanceimport pytesseract#上面都是导包,只需要下面这一行就能实现图片文字识 ...
- centos上搭建git服务--3
前言:当我们想要实现几个小伙伴合作开发同一个项目,或者建立一个资源分享平台的时候,GIT就是一个很好的选择.当然,既然是一个共有平台,那么把这个平台放到个人计算机上明显是不合适的,因此就要在服务器上搭 ...
- Eclipse/myEclipse 代码提示/自动提示/自动完成设置(转)
一.设置超级自动提示 设置eclipse/myEclipse代码提示可以方便开发者,不用在记住拉杂的单词,只用打出首字母,就会出现提示菜单.如同dreamweaver一样方便. 1.菜单window- ...
- J2EE Oa项目上传服务器出现的乱码解决过程
(= =)搞了许久觉得有必要记下来.. 由于我本地的mysql都设置好了,但是服务器的又不能去改它 毕竟还有其他人要用- -: 所以只能是我建的时候去设置一下了, 首先先建数据库 ,表;; creat ...
- alpha6/10
队名:Boy Next Door 燃尽图 晗(组长) 今日完成 学习了css的一些基本操作. 明日工作 抽空把javascript的基本操作学习一下 还剩下哪些任务 微信API还有京东钱包的API. ...
- 面试Tips
面试Tips 面向对象:准备找工作的同学 内容概述:关于面试的一些经验总结,希望能带给你些许帮助.若有描述不准确的地方,欢迎指点建议. 内容提炼:共分为四阶段 1.面试前之静生慧 (1)课本知识过一遍 ...
- oracle & 的用法!
/*select * from emp_bak where deptno = &"Department number" order by ename; select * f ...
- [cnbeta]微软最强数据中心级操作系统
微软近日发表了一篇介绍Windows系统内核的博文,期间为了展示Windows的强大扩展性,放出了一张非常震撼的Windows任务管理器截图:乍一看似乎没啥特别的,几十甚至上百个逻辑核心的系统并不罕见 ...