吴裕雄--天生自然 R语言开发学习:高级数据管理












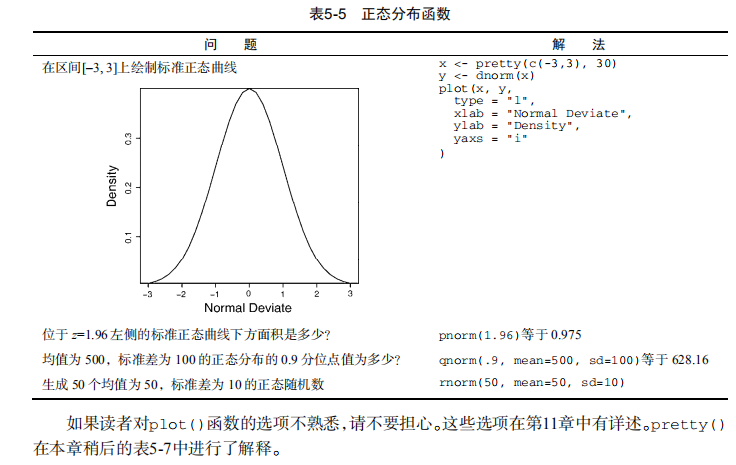




#-----------------------------------#
# R in Action (2nd ed): Chapter 5 #
# Advanced data management #
# requires that the reshape2 #
# package has been installed #
# install.packages("reshape2") #
#-----------------------------------# # Class Roster Dataset
Student <- c("John Davis","Angela Williams","Bullwinkle Moose",
"David Jones","Janice Markhammer",
"Cheryl Cushing","Reuven Ytzrhak",
"Greg Knox","Joel England","Mary Rayburn")
math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
english <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18)
roster <- data.frame(Student, math, science, english,
stringsAsFactors=FALSE) # Listing 5.1 - Calculating the mean and standard deviation
x <- c(1, 2, 3, 4, 5, 6, 7, 8)
mean(x)
sd(x)
n <- length(x)
meanx <- sum(x)/n
css <- sum((x - meanx)**2)
sdx <- sqrt(css / (n-1))
meanx
sdx # Listing 5.2 - Generating pseudo-random numbers from
# a uniform distribution
runif(5)
runif(5)
set.seed(1234)
runif(5)
set.seed(1234)
runif(5) # Listing 5.3 - Generating data from a multivariate
# normal distribution
library(MASS)
mean <- c(230.7, 146.7, 3.6)
sigma <- matrix( c(15360.8, 6721.2, -47.1,
6721.2, 4700.9, -16.5,
-47.1, -16.5, 0.3), nrow=3, ncol=3)
set.seed(1234)
mydata <- mvrnorm(500, mean, sigma)
mydata <- as.data.frame(mydata)
names(mydata) <- c("y", "x1", "x2")
dim(mydata)
head(mydata, n=10) # Listing 5.4 - Applying functions to data objects
a <- 5
sqrt(a)
b <- c(1.243, 5.654, 2.99)
round(b)
c <- matrix(runif(12), nrow=3)
c
log(c)
mean(c) # Listing 5.5 - Applying a function to the rows (columns) of a matrix
mydata <- matrix(rnorm(30), nrow=6)
mydata
apply(mydata, 1, mean)
apply(mydata, 2, mean)
apply(mydata, 2, mean, trim=.4) # Listing 5.6 - A solution to the learning example
options(digits=2)
Student <- c("John Davis", "Angela Williams", "Bullwinkle Moose",
"David Jones", "Janice Markhammer", "Cheryl Cushing",
"Reuven Ytzrhak", "Greg Knox", "Joel England",
"Mary Rayburn")
Math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
Science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
English <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18) roster <- data.frame(Student, Math, Science, English,
stringsAsFactors=FALSE) z <- scale(roster[,2:4])
score <- apply(z, 1, mean)
roster <- cbind(roster, score) y <- quantile(score, c(.8,.6,.4,.2))
roster$grade[score >= y[1]] <- "A"
roster$grade[score < y[1] & score >= y[2]] <- "B"
roster$grade[score < y[2] & score >= y[3]] <- "C"
roster$grade[score < y[3] & score >= y[4]] <- "D"
roster$grade[score < y[4]] <- "F" name <- strsplit((roster$Student), " ")
Lastname <- sapply(name, "[", 2)
Firstname <- sapply(name, "[", 1)
roster <- cbind(Firstname,Lastname, roster[,-1])
roster <- roster[order(Lastname,Firstname),] roster # Listing 5.4 - A switch example
feelings <- c("sad", "afraid")
for (i in feelings)
print(
switch(i,
happy = "I am glad you are happy",
afraid = "There is nothing to fear",
sad = "Cheer up",
angry = "Calm down now"
)
) # Listing 5.5 - mystats(): a user-written function for
# summary statistics
mystats <- function(x, parametric=TRUE, print=FALSE) {
if (parametric) {
center <- mean(x); spread <- sd(x)
} else {
center <- median(x); spread <- mad(x)
}
if (print & parametric) {
cat("Mean=", center, "\n", "SD=", spread, "\n")
} else if (print & !parametric) {
cat("Median=", center, "\n", "MAD=", spread, "\n")
}
result <- list(center=center, spread=spread)
return(result)
} # trying it out
set.seed(1234)
x <- rnorm(500)
y <- mystats(x)
y <- mystats(x, parametric=FALSE, print=TRUE) # mydate: a user-written function using switch
mydate <- function(type="long") {
switch(type,
long = format(Sys.time(), "%A %B %d %Y"),
short = format(Sys.time(), "%m-%d-%y"),
cat(type, "is not a recognized type\n"))
}
mydate("long")
mydate("short")
mydate()
mydate("medium") # Listing 5.9 - Transposing a dataset
cars <- mtcars[1:5, 1:4]
cars
t(cars) # Listing 5.10 - Aggregating data
options(digits=3)
attach(mtcars)
aggdata <-aggregate(mtcars, by=list(cyl,gear),
FUN=mean, na.rm=TRUE)
aggdata # Using the reshape2 package
library(reshape2) # input data
mydata <- read.table(header=TRUE, sep=" ", text="
ID Time X1 X2
1 1 5 6
1 2 3 5
2 1 6 1
2 2 2 4
") # melt data
md <- melt(mydata, id=c("ID", "Time")) # reshaping with aggregation
dcast(md, ID~variable, mean)
dcast(md, Time~variable, mean)
dcast(md, ID~Time, mean) # reshaping without aggregation
dcast(md, ID+Time~variable)
dcast(md, ID+variable~Time)
dcast(md, ID~variable+Time)
吴裕雄--天生自然 R语言开发学习:高级数据管理的更多相关文章
- 吴裕雄--天生自然 R语言开发学习:R语言的安装与配置
下载R语言和开发工具RStudio安装包 先安装R
- 吴裕雄--天生自然 R语言开发学习:数据集和数据结构
数据集的概念 数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量.表2-1提供了一个假想的病例数据集. 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和 ...
- 吴裕雄--天生自然 R语言开发学习:导入数据
2.3.6 导入 SPSS 数据 IBM SPSS数据集可以通过foreign包中的函数read.spss()导入到R中,也可以使用Hmisc 包中的spss.get()函数.函数spss.get() ...
- 吴裕雄--天生自然 R语言开发学习:使用键盘、带分隔符的文本文件输入数据
R可从键盘.文本文件.Microsoft Excel和Access.流行的统计软件.特殊格 式的文件.多种关系型数据库管理系统.专业数据库.网站和在线服务中导入数据. 使用键盘了.有两种常见的方式:用 ...
- 吴裕雄--天生自然 R语言开发学习:R语言的简单介绍和使用
假设我们正在研究生理发育问 题,并收集了10名婴儿在出生后一年内的月龄和体重数据(见表1-).我们感兴趣的是体重的分 布及体重和月龄的关系. 可以使用函数c()以向量的形式输入月龄和体重数据,此函 数 ...
- 吴裕雄--天生自然 R语言开发学习:基础知识
1.基础数据结构 1.1 向量 # 创建向量a a <- c(1,2,3) print(a) 1.2 矩阵 #创建矩阵 mymat <- matrix(c(1:10), nrow=2, n ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶(续二)
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶(续一)
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:基本图形(续二)
#---------------------------------------------------------------# # R in Action (2nd ed): Chapter 6 ...
随机推荐
- 吴裕雄--天生自然ShellX学习笔记:Shell 输入/输出重定向
大多数 UNIX 系统命令从你的终端接受输入并将所产生的输出发送回到您的终端.一个命令通常从一个叫标准输入的地方读取输入,默认情况下,这恰好是你的终端.同样,一个命令通常将其输出写入到标准输出,默 ...
- Python 中 JSON和dict的转换,json的使用
一. 基础语法 在Python 的 json库中,共有四个方法.分别是: json.load() # 从文件中加载 json.loads() # 数据中加载 json.dump() # 转存到文件 j ...
- Cannot read property 'XXXX' of null/undifined
这个问题可能的原因有很多 1.如果你的js直接写在自执行函数或者head标签内的script里面,那么可以检查一下你的代码有没有用到页面里的节点,因为这样写的代码在页面加载完成之前就会开始执行,如果有 ...
- C语言 指针理解
1.指针 指针全称是指针变量,其实质是C语言的一种变量.这种变量比较特殊,通常他的值会被赋值为某个变量的地址值(p = &a),然后我们可以使用 *p 这样的方式去间接访问p所指向的那个变量. ...
- BBS注册功能
BBS注册功能 一.后端 1.组件校验数据 """ @author RansySun @create 2019-11-03-11:35 """ ...
- python 知识点补充
python 知识点补充 简明 python 教程 r 或 R 来指定一个 原始(Raw) 字符串 Python 是强(Strongly)面向对象的,因为所有的一切都是对象, 包括数字.字符串与 函数 ...
- Covisibility Graph
在Orb-Slam中有三个地图分别是Covisibility Graph,Spanning Graph,以及Essential Graph,它们三个分别是什么意思呢? 首先,图优化是目前视觉SLAM里 ...
- nginx 反向代理学习
目录 nginx 反向代理学习 一.正向代理和反向代理的区别 1.1正向代理 1.2 反向代理 二.nginx反向代理的使用 nginx 反向代理学习 一.正向代理和反向代理的区别 正向代理代理客户端 ...
- 函数(Python)
函数是什么? 计算机的函数,是一个固定的一个程序段,或称其为一个子程序,它在可以实现固定运算功能的同时,还带有一个入口和一个出口,所谓的入口,就是函数所带的各个参数,我们可以通过这个入口,把函数的参数 ...
- 搭建rocketmq
安装maven和java环境,此处省略.如果没有安装,请先安装maven和java环境!或者安装openjdk 首先下载rockermq官方地址:http://rocketmq.apache.org/ ...