吴裕雄--天生自然PYTHON爬虫:爬虫攻防战

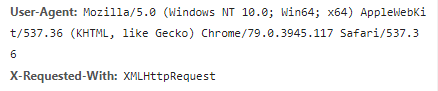

我们在开发者模式下不仅可以找到URL、Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己。服务器识别浏览器访问的方法就是判断keywor是否为Request headers下的User-Agent,因此我们只需要构造这个请求头的参数。创建请求头部信息即可。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'
}
response = requests.get(url,headers=headers)
写到这里,或许许多人认为修改User-Agent很简单,也确实是简单,但是正常人1秒看一张图片,而如果是代码爬虫的话1秒就可以抓取好多张图,比如1秒就抓取了一百张图片,那么服务器的压力必然会增大。也就是说如果在一个IP下批量访问下载图片,这个行为不符合正常人类的行为,这个访问IP肯定要被封的。其原理也很简单,就是统计每个IP的访问率,该频率超过了阈值,就会返回一个验证码,如果真的是用户访问的话,用户就会填写,然后继续访问,如果是代码访问的话,就会封IP。
这个问题的解决方案有两个,第一个就是常用的增设延时,每三秒抓取一次,代码如下:
import time
time.sleep(3)
不管如何访问,服务器的目的就是要查出哪些访问是代码访问,然后封IP,解决避免被封IP,在数据采集时经常会使用代理。当然,requests也有相应的proxies属性。首先,构建自己的代理IP池,将其以字典的形式赋值给proxies,然后传输给requests,代码如下:
proxies = {
'http':'http://10.10.1.10:3128',
'https':'http://10.10.1.10:1080'
}
response = requests.get(url,proxies=proxies)
吴裕雄--天生自然PYTHON爬虫:爬虫攻防战的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然python学习笔记:编写网络爬虫代码获取指定网站的图片
我们经常会在网上搜索井下载图片,然而一张一张地下载就太麻烦了,本案例 就是通过网络爬虫技术, 一次性下载该网站所有的图片并保存 . 网站图片下载并保存 将指定网站的 .jpg 和 .png 格式的图片 ...
- 吴裕雄--天生自然python学习笔记:python爬虫PM2.5 实时监测显示器
PM2.5 对人体的健康影响很大,所以空气中的 PM2.5 实时信息受到越来越多的关注. Python 的 Pandas 套件不但可以自动读取网页中的表格 数据 , 还可对数据进行修改.排序等处理,也 ...
- 吴裕雄--天生自然python学习笔记:python爬虫与网页分析
我们所抓取的网页源代码一般都是 HTML 格式的文件,只要研究明白 HTML 中 的标签( Tag )结构,就很容易进行解析并取得所需数据 . HTML 网页结构 HTML 网 页是由许多标签( Ta ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
随机推荐
- EF 查询表达式 join
数据源: 1.无into,相当于 inner join var query = from p in context.P join s in context.S on p.PID equals s.PI ...
- 计算机二级-C语言-程序修改题-190123记录-对整数进行取余和除以操作。
//函数fun功能:将长整型数中每一位上为偶数的数依次取出,构成一个新数放在t中.高位仍在高位,低位仍在低位. //重难点:思路:因为不是字符串,所以可以把问题变成整数的操作,采用取余和除的操作.对整 ...
- 「SDOI2009」虔诚的墓主人
传送门 Luogu 解题思路 离散化没什么好说 有一种暴力的想法就是枚举每一个坟墓,用一些数据结构维护一下这个店向左,向右,向上,向下的常青树的个数,然后用组合数统计方案. 但是网格图边长就有 \(1 ...
- Linux中命令备份mysql形成文件
基于龙哥(Thomas)的总结: mysqldump -u 用户名 -p密码 数据库名>bbs87.sql | tar -zcvf bbs87.tar.gz bbs87.sql 通过词条命令可以 ...
- ES6简单语法
ES6 简单语法: 变量声明 ES5 var 声明变量为全局变量 会变量提升 ES6 let 声明的变量为块级变量 且不能重复声明 不存在变量提升 # {}一个大括号为一个作用域 ES6 const ...
- Codeforces Global Round 5E(构造,思维)
#define HAVE_STRUCT_TIMESPEC#include<bits/stdc++.h>using namespace std;int main(){ ios::sync_w ...
- 【PAT甲级】1048 Find Coins (25 分)(二分)
题意: 输入两个正整数N和M(N<=10000,M<=1000),然后输入N个正整数(<=500),输出两个数字和恰好等于M的两个数(小的数字尽可能小且输出在前),如果没有输出&qu ...
- 3000 - No Mycat Database selected
今天在linux上搭建好mycat后,用Navicat连接出现如下错误 尝试很多方式发现并没有什么用,后面改用SQLyog连接就可以正常使用了!!!
- StaticLinkList(静态链表)
写这个写了几次,然后都没写完就关掉了,所以也不想多码字了,直接上代码吧(本来还认真自制了一张图片来理解静态链表的cursor与sub之间的关系)但其实也就那么回事:通过游标来找下标通过下标找到对应的数 ...
- 软件架构,WEB - REST架构,RESTful API
参考 https://www.zhihu.com/question/27785028/answer/48096396 wiki太学术化了 http://www.ruanyifeng.com/blog/ ...