吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙。



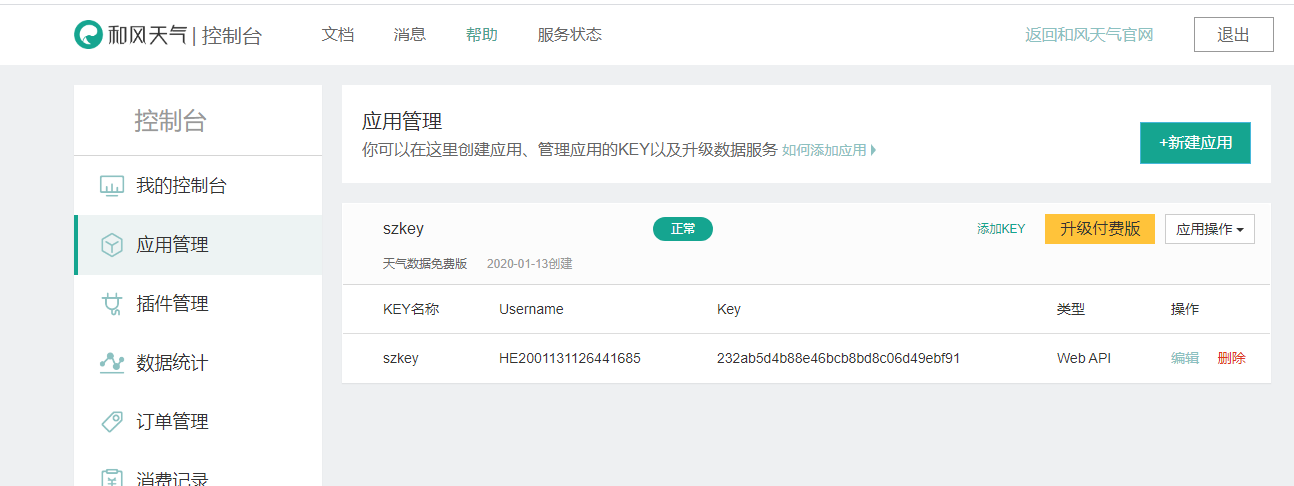
这个key现在是要自己创建的,名称自己写,key值可以不写,创建的时候会自动生成。
接下来就是要阅读这个API文档。

包括上面怎么创建获取这个key这个API文档也有介绍的。

选择API这部分来阅读。
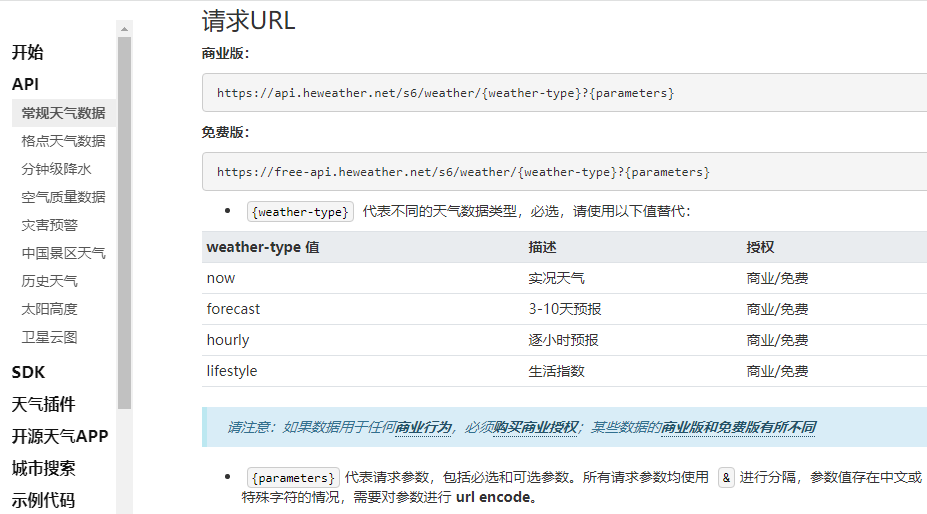
接口地址:
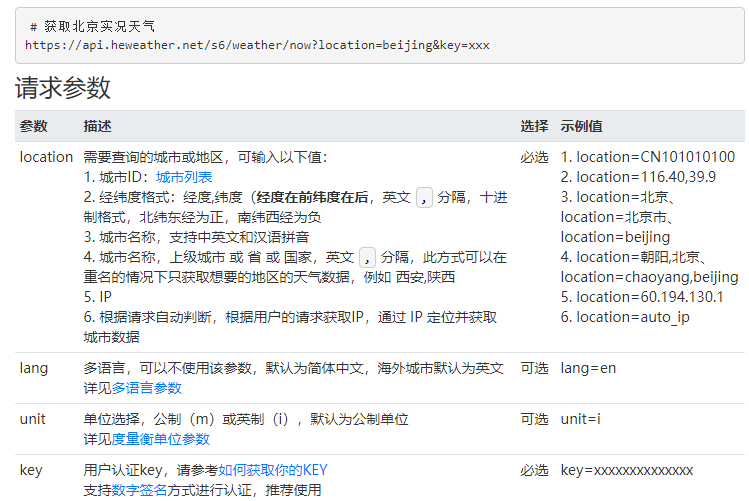
#获取城市列表
import requests url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
response.encoding='utf8'
data = response.text
data_1 = data.split('\n')
print(data_1)
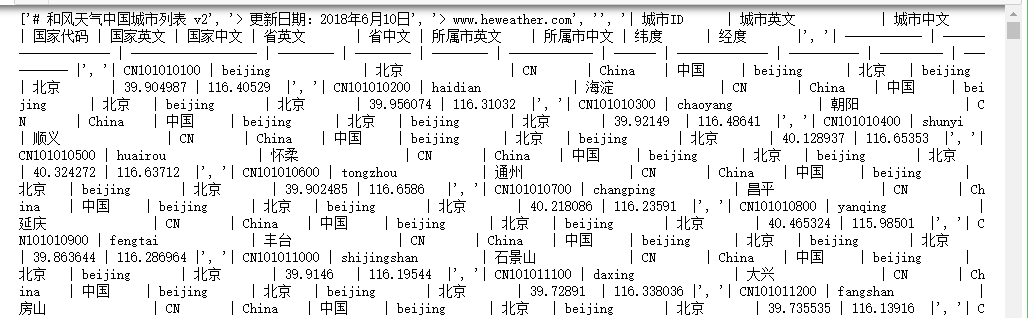

for i in range(3):
data_1.remove(data_1[0])
for item in data_1:
print(item[0:11])

获取城市ID后,下一步就是调用接口获取数据。
#获取城市数据
import time
import requests url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
response.encoding='utf8'
data = response.text
data_1 = data.split('\n')
for i in range(3):
data_1.remove(data_1[0])
for item in data_1:
url = 'https://free-api.heweather.net/s6/weather/forecast?location='+item[1:13]+'&key=232ab5d4b88e46bcb8bd8c06d49ebf91'
strhtml = requests.get(url)
time.sleep(3)
print(strhtml.text)
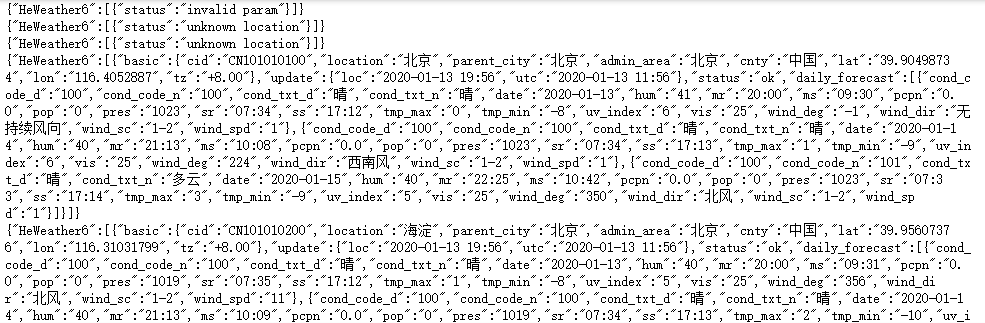
可以看到数据是以json数据格式返回的。如果要将返回的数据解析出来可以使用for循环。
可以使用JSON在线结构化的工具观察数据结构,网址:http://www.json.org.cn/tools/JSONEditorOnline/index.htm


上图左边是原Json数据,右边显示的是它的保存数据的结构。
#获取城市数据
import os
import time
import requests url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
response.encoding='utf8'
data = response.text
data_1 = data.split('\n')
for i in range(3):
data_1.remove(data_1[0]) temp = 1
for item in data_1:
url = 'https://free-api.heweather.net/s6/weather/forecast?location='+item[1:13]+'&key=232ab5d4b88e46bcb8bd8c06d49ebf91'
strhtml = requests.get(url)
time.sleep(3)
dic = strhtml.json()
if(temp>3):
#获取风向值
print(dic['HeWeather6'][0]['daily_forecast'][0]['wind_dir'])
#获取最低气温
print(dic['HeWeather6'][0]['daily_forecast'][0]['tmp_min'])
#获取最高气温
print(dic['HeWeather6'][0]['daily_forecast'][0]['tmp_max'])
print('================')
else:
temp+=1

吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然PYTHON爬虫:爬虫攻防战
我们在开发者模式下不仅可以找到URL.Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己.服务器识别浏览器访问的方法就是判断keywor是否为Request h ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
- 吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据
import requests url = 'http://www.cntour.cn/' strhtml = requests.get(url) print(strhtml.text) URL='h ...
- 吴裕雄--天生自然python学习笔记:爬取我国 1990 年到 2017年 GDP 数据并绘图显示
绘制图形所需的数据源通常是不固定的,比如,有时我们会需要从网页抓取, 也可能需从文件或数据库中获取. 利用抓取网页数据技术,把我国 1990 年到 2016 年的 GDP 数据抓取出来 ,再利用 Ma ...
- 吴裕雄--天生自然python学习笔记:Python3 错误和异常
语法错误 Python 的语法错误或者称之为解析错,是初学者经常碰到的,如下实例 >>>while True print('Hello world') File "< ...
随机推荐
- placeholder样式
.mdwh_txtmod_tp_inpshad input::-webkit-input-placeholder { /* WebKit browsers */ color: #cccccc; } . ...
- 获取SqlServer存储过程定义的三种方法
declare @p_text varchar(max) SELECT @p_text= text FROM syscomments WHERE id = ( SELECT id FROM sysob ...
- python爬取course课程的信息
目录 1.大模块页面 2.每个大模块中小模块的简单信息 3.每个小课程的详细信息 4.爬取所有评论 @ 这几天爬取了course动态网页的课程信息,有关数据分析,机器学习,还有概率论和数理统计课程 ...
- 使用scrapy-redis 搭建分布式爬虫环境
scrapy-redis 简介 scrapy-redis 是 scrapy 框架基于 redis 数据库的组件,用于 scraoy 项目的分布式开发和部署. 有如下特征: 分布式爬取: 你可以启动多个 ...
- Vue——解决移动端键盘弹起导致的页面fixed定位元素布局错乱
最近做了一个移动端项目,页面主体是由form表单和底部fixed定位的按钮组成,当用户进行表单输入时,手机软键盘弹起,此时页面的尺寸发生变化,底部fixed定位的元素自然也会上移,可能就会覆盖页面中的 ...
- 【原】tcp三次握手和四次挥手
- c#活动目录操作
c#活动目录操作 https://www.cnblogs.com/ahuo/archive/2007/03/16/676853.html 添加引用 System.DirectoryServices导 ...
- vue.js ③
1.组件使用的细节点 H5编码中的规范是tr必须在tbody里所以不能直接套用<row></row>的写法,<ul>标签下支持<li>,select标签 ...
- php 基础知识 常见面试题
1.echo.print_r.print.var_dump之间的区别 * echo.print是php语句,var_dump和print_r是函数 * echo 输出一个或多个字符串,中间以逗号隔开, ...
- Python爬虫连载6-cookie深入使用实例化实现自动登录
一.使用cookie登录 1.直接把cookie复制下去,然后手动放到请求头 2.http模块包含一些关于cookie的模块,通过他们我们可以自动使用cookie (1)cookieJar 管理存储c ...