Selenium&Pytesseract模拟登录+验证码识别
验证码是爬虫需要解决的问题,因为很多网站的数据是需要登录成功后才可以获取的.
验证码识别,即图片识别,很多人都有误区,觉得这是爬虫方面的知识,其实是不对的.
验证码识别涉及到的知识:人工智能,模式识别,机器视觉,图像处理.
主要流程:
1 图像采集:就直接通过HTTP抓HTML,然后分析出图片的url,然后下载保存就可以了
2 预处理: 检测是正确的图像格式,转换到合适的格式,压缩,剪切出ROI,去除噪音,灰度化,转换色彩空间这些
3 检测: 验证码识别呢,主要是找出文字所在的主要区域
4 前处理: 验证码识别,“一般”要做文字的切割
5 训练: 通过各种模式识别,机器学习算法,来挑选和训练合适数量的训练集
6 识别: 输入待识别的处理后的图片,转换成分类器需要的输入格式,然后通过输出的类和置信度,来判断大概可能是 哪个字母
Pytesseract--验证码识别
1 简介
Python-tesseract是一款用于光学字符识别(OCR)的python工具,即从图片中识别出其中嵌入的文字。Python-tesseract是对Google Tesseract-OCR的一层封装。它也同时可以单独作为对tesseract引擎的调用脚本,支持使用PIL库(Python Imaging Library)读取的各种图片文件类型,包括jpeg、png、gif、bmp、tiff和其他格式,。作为脚本使用它将打印出识别出的文字而非写入到文件。所以安装pytesseract前要先安装PIL和tesseract-orc这俩依赖库
2 安装
PIL安装 Python平台的图像处理标准库
pip3 install pillow
pytesseract安装,文字识别库
pip3 install pytesseract
tesseract-ocr安装,识别引擎
windows:
https://digi.bib.uni-mannheim.de/tesseract/
下载
tesseract-ocr-setup-3.05.02 或者 tesseract-ocr-setup-4.0.0-alpha
linux:
github上面下载对应版本
https://github.com/tesseract-ocr/tesseract
遇到问题及解决:
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path
解决方法:(我是win环境)
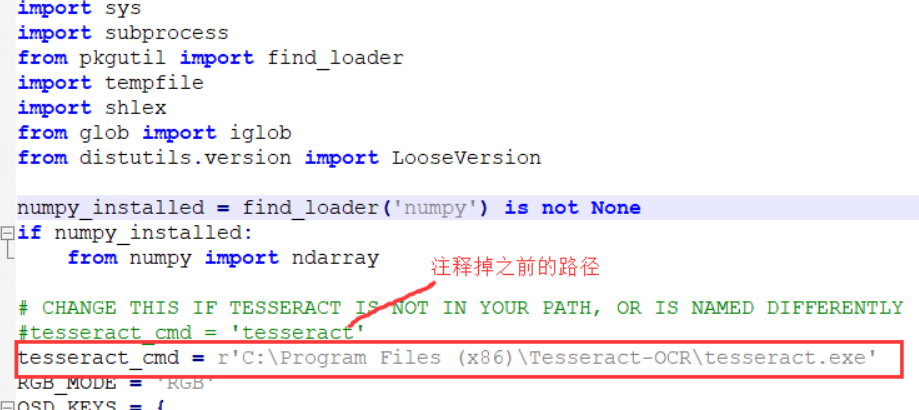
找到tesseract-ocr安装目录,复制路径如: C:\Program Files (x86)\Tesseract-OCR\tesseract.exe
找到pytesseract.py文件,修改tesseract_cmd的路径,如下:
环境安装完后,分析目标网站:
华中科技大学 http://www.hust-snde.com/cms/
需求,每天登陆一次保持活跃度
可以看到这个登陆是需要输入验证码的
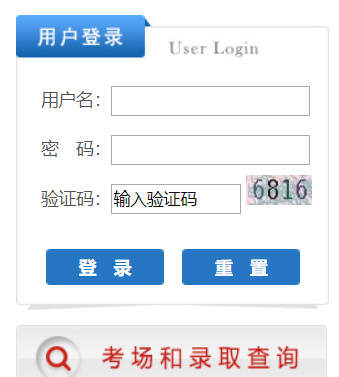
下面将利用Selenium&Pytesseract模拟登陆+验证码识别
完整代码如下:
#!/usr/bin/env python
# coding: utf-8 import time
from selenium import webdriver
from PIL import Image
import pytesseract class LoginSchool(object):
def __init__(self, username, password, url):
self.username = username
self.password = password
self.url = url
self.browser = self.getbrowser()
self.login_school(self.browser) def getbrowser(self):
chrome_options = webdriver.ChromeOptions()
# 去除警告
chrome_options.add_argument('disable-infobars')
# 无头模式
# chrome_options.set_headless()
browser = webdriver.Chrome(options=chrome_options,
executable_path=r'D:\chromedriver_2.41\chromedriver.exe')
return browser def login_school(self, browser):
browser.get(self.url)
time.sleep(3)
# 打开目标网站,并截取完整的图片
browser.get_screenshot_as_file('login.png')
# 找到输入账号的input,并输入账号
browser.find_element_by_id("loginId").send_keys(self.username)
# 找到输入密码的input,并输入密码
browser.find_element_by_id("passwd").send_keys(self.password)
# 找到验证码img标签,切图
img_code = browser.find_element_by_xpath("//div[@class='logif']//img[@id='imgCode']")
time.sleep(3)
# 算出验证码的四个点,即验证码四个角的坐标地址
left = img_code.location['x']
top = img_code.location['y']
right = img_code.location['x'] + img_code.size['width']
bottom = img_code.location['y'] + img_code.size['height']
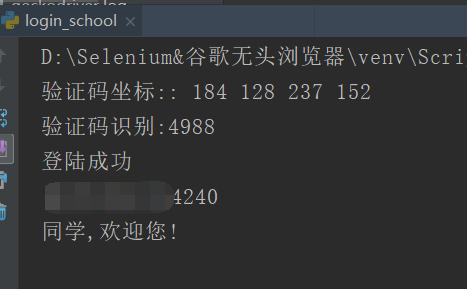
print("验证码坐标::", left, top, right, bottom)
# 利用python的PIL图片处理库,利用坐标,切出验证码的图
im = Image.open('login.png')
im = im.crop((left, top, right, bottom))
im.save('code.png')
# 调用图片识别的函数,得到验证码
code = self.img_to_str()
# 找到验证码的input,并输入验证码
browser.find_element_by_id("authCode").send_keys(code)
# 点击登录按钮
browser.find_element_by_xpath("//div[@class='loga']/a[text()=' 登 录']").click()
time.sleep(2)
try:
msg = browser.find_element_by_xpath("//div[@class='user_name']").text
if msg:
print('登陆成功')
print(msg)
except Exception as e:
print('登陆失败:{}'.format(e))
finally:
time.sleep(1)
browser.quit() def img_to_str(self):
# 打开切出的验证码code.png
img = Image.open('code.png')
# 利用pytesseract识别出验证码
# -psm 8 为识别模式
# -c tessedit_char_whitelist=1234567890 的意思是 识别纯数字(0-9)
code = pytesseract.image_to_string(img, config='-psm 8 -c tessedit_char_whitelist=1234567890')
print('验证码识别:{}'.format(code))
return code if __name__ == '__main__':
username = '账号'
password = '密码'
url = 'http://www.hust-snde.com/center\
/left_hydl.jsp?url=www.hust-snde.com:80/sso/login_centerLogin.action'
st = LoginSchool(username=username, password=password, url=url)
运行程序:
当前目录下会生成两个图片文件
login.png 为登陆时的截图
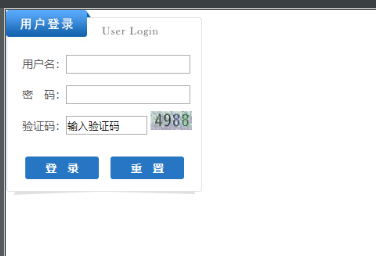
code.png是从上面login.png中切出来的验证码图片

pytesseract识别简单的验证码成功率还行,如果验证码有干扰线,噪点之类的就需要对验证码图片进行去除噪音,灰度化,转换色彩空间这些处理.
如果验证码有字体样式,或者比较复杂,就需要训练,来提高识别的成功率.
转载出处:
http://www.py3study.com/Article/details/id/351.html
Selenium&Pytesseract模拟登录+验证码识别的更多相关文章
- Selenium&Pytesseract模拟登录+验证码识别
验证码是爬虫需要解决的问题,因为很多网站的数据是需要登录成功后才可以获取的. 验证码识别,即图片识别,很多人都有误区,觉得这是爬虫方面的知识,其实是不对的. 验证码识别涉及到的知识:人工智能,模式识别 ...
- linux环境下pytesseract的安装和央行征信中心的登录验证码识别
首先是安装,我参考的是这个 http://blog.csdn.net/xinghun_4/article/details/47860645 我是centos,使用yum yum install pyt ...
- python爬虫模拟登录验证码解决方案
[前言]几天研究验证码解决方案有三种吧.第一.手工输入,即保存图片后然后我们手工输入:第二.使用cookie,必须输入密码一次,获取cookie:第三.图像处理+深度学习方案,研究生也做相关课题,就用 ...
- selenium模拟登录豆瓣和qq空间
selenium模拟登录豆瓣和qq空间今天又重新学习了下selenium,模拟登录豆瓣,发现设置等待时间真的是很重要的一步,不然一直报错:selenium.common.exceptions.NoSu ...
- 豆瓣模拟登录(双层html)
一.豆瓣模拟登录(双层html) #!/usr/bin/env python # -*- coding: utf-8 -*- #author tom import time from selenium ...
- 2 模拟登录_Post表单方式(针对chinaunix有效,针对csdn失效,并说明原因)
参考精通Python网络爬虫实战 首先,针对chinaunix import urllib.request #原书作者提供的测试url url="http://bbs.chinaunix.n ...
- Python之selenium+pytesseract 实现识别验证码自动化登录脚本
今天写自己的爆破靶场WP时候,遇到有验证码的网站除了使用pkav的工具我们同样可以通过py强大的第三方库来实现识别验证码+后台登录爆破,这里做个笔记~~~ 0x01关于selenium seleniu ...
- selenium识别登录验证码---基于python实现
本文主要是通过PIL+pytesseract+Tesseract-OCR实现验证码的识别 其中PIL为Python Imaging Library,已经是Python平台事实上的图像处理标准库了.PI ...
- C#使用tesseract3.02识别验证码模拟登录
一.前言 使用tesseract3.02识别有验证码的网站 安装tesseract3.02 在VS nuget 搜索Tesseract即可. 二.项目结构图 三.项目主要代码 using System ...
随机推荐
- 2019牛客暑期多校训练营(第五场)B.generator 1
传送门:https://ac.nowcoder.com/acm/contest/885/B 题意:给出,由公式 求出 思路:没学过矩阵快速幂.题解说是矩阵快速幂,之后就学了一遍.(可以先去学一下矩阵快 ...
- iOS筛选菜单、分段选择器、导航栏、悬浮窗、转场动画、启动视频等源码
iOS精选源码 APP启动视频 自定义按钮,图片可调整图文间距SPButton 一款定制性极高的轮播图,可自定义轮播图Item的样式(或只... iOS 筛选菜单 分段选择器 仿微信导航栏的实现,让你 ...
- 安装R的h5包
系统 redhat7 安装H5的包, 依赖系统hdf5包,如下安装完, 发现版本不一致, sudo yum install hdf5-devel 解决办法: 移花接木 sudo ln -s /opt/ ...
- python画图例子代码
matplotlib包,使得python可以使用类似matlab的命令 双坐标,子图例子 fig, axes = plt.subplots( 2,1, figsize=(14, 14) ) ax = ...
- 黑马eesy_15 Vue:03.生命周期与ajax异步请求
黑马eesy_15 Vue:02.常用语法 黑马eesy_15 Vue:03.生命周期 黑马eesy_15 Vue:04.Vue案例(ssm环境搭建) vue的生命周期与ajax异步请求 1.Vue的 ...
- DNA methylation|Transcription factors|PTM|Chromosome conformation|表观遗传学测序技术
生物医疗大数据-DNA element functions and identification Genetic vs epigenetic GENETICS 遗传学 DNA Code: 64 tr ...
- redis day02
Redis -带过期时间的key 如何删除掉的? 在redis内部有个 过期字典,所有带过期时间的都有过期字典 默认情况下 redis每秒会进行着10次过期字典的扫描,在每一次扫描过程里,执行如下 ...
- Maven中settings.xml文件各标签含义
原文地址:http://www.cnblogs.com/jingmoxukong/p/6050172.html?utm_source=gold_browser_extension settings.x ...
- s01字符串---蓝桥杯
问题描述 s01串初始为"0" 按以下方式变换 0变1,1变01 输入格式 1个整数(0~19) 输出格式 n次变换后s01串 样例输入 3 样例输出 101 数据规模和约定 0~ ...
- spring cloud解决eureka的client注册时默认使用hostname而不是ip
eureka的client注册到server时默认是使用hostname而不是ip.这样的话使用feign client通过eureka进行服务间相互调用时也会使用hostname进行调用,从而调用失 ...