https://mp.weixin.qq.com/s/kNQrhlf33AErK7IzalnUDw
简单介绍Fragmenter的实现。

1. 基本介绍
用于把上游节点地址空间范围比较大的访问请求,拆分成下游支持的多个地址空间范围较小的访问请求。

1) 类参数
a. minSize:向下游节点发起的最小的访问大小;
b. maxSize:上游节点可以下发的最大的访问大小;
c. alwaysMin:是否把所有上游节点的请求,都拆分成minSize大小的访问请求:
- 如果为真:把所有上游节点的请求,都拆分成minSize大小的访问请求;
- 如果为假:根据下游节点的能力大小来拆分上游节点的访问请求;
d. earlyAck:针对一个Put burst,是在第一个beat回复响应消息,还是再最后一个beat回复响应消息;
e. holdFirstDeny:针对一个Get burst,在出现denied时就一直保持,直到整个burst结束;
2) 参数限制
要求minSize/maxSize都是2的幂,并且minSize小于等于maxSize:

3) minSize/maxSize
a. 实例
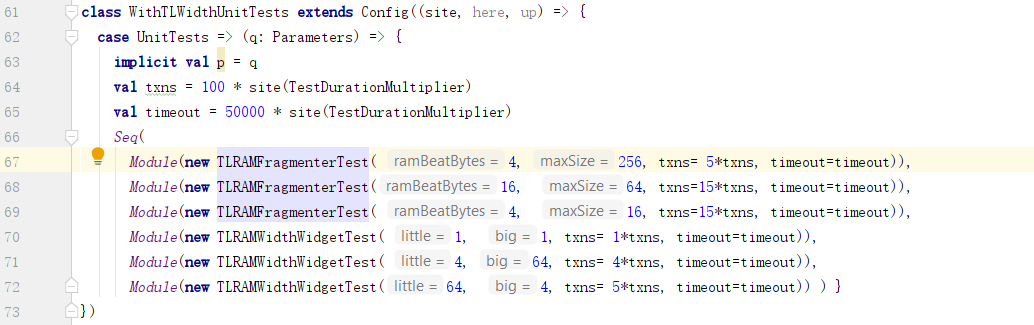
其中:ramBeatBytes是RAM支持的访问大小的物理能力。而maxSize是Fragmenter能拆分的最大访问请求的大小。
b. minSize
minSize实际上更多的指代下游节点的物理能力,比如说总线宽度。
c. 实际访问大小
但上游节点的访问请求,可能会小于minSize。此时不需要拆分,直接以原请求大小透传即可。
比如:minSize = ramBeatBytes = 4,而Get请求的大小为2,即读取两个字节。
2. diplomacy node
1) 添加的编码位

a. fragmentBits:分片编号所需要占用的比特数;
b. fullBits:是否需要earlyAck所需要占用的比特数,All和None都不需要这个比特:

c. toggleBits:用于区分两个连续的burst请求的比特位;
d. addedBits:上面加在一起就是需要添加的全部比特位的数目;
2) expandTransfer
扩展Transfer x的大小:

a. 如果x为none,则不进行扩展;
b. 把x.max扩展为maxSize,即Fragmenter支持的最大传输大小;
c. x.min不变;
3) shrinkTransfer
缩小transfer x的大小:

A. 如果不要求把所有的请求都拆分成minSize大小,则不需要缩小x;
B. 如果要求把所有的请求都拆分成minSize大小:
a. 如果x.min大于minSize,那么该传输不支持;
b. 如果x.min小于等于minSize,则把x.max限定在不大于minSize;
总结:缩小的意思是把传输大小的最大值限定在minSize以下。
4) mapManager
放大或缩小manager支持的各项操作的传输大小:

a. 对Atomic操作的大小进行缩小;
b. 对Get/Put/Hint操作的大小进行放大;
根据注释:

a. Arithmetic操作透传:数学运算需要提供操作数,而操作数不能分片,所以只能透传;
b. Get/Put/Hint/Logical操作可以分片:相较之下,位运算的结果只与当前位相关,所以可以分片进行运算;
c. 不支持Acquire操作;
Arithmetic操作要把传输大小缩小可以理解,因为其不支持分片。Logical操作呢?可以把传输大小放大吗?我认为是可以的,所以这里针对supportsLogical,应该是expandTransfer,而不是shrinkTransfer。
但考虑到Logical操作是原子操作,分片后的多个Logical请求之间,是否会被插入其他的请求消息呢?有可能,为了避免这种情况,还是shrinkTransfer较为妥当,毕竟Fragmenter不处理这种同步问题。
5) diplomacy node

A. clientFn:把Fragmenter看到的上游节点的参数,转换为下游节点看到的Fragmenter的参数。
这里进行了如下调整:
a. name:名称为TLFragmenter;
b. sourceId:需要把分片号等信息编码进sourceId中,所以其范围扩大了;
c. requestFifo:需要下游节点实现按请求顺序返回响应信息;
B. managerFn:把Fragmenter看到的下游节点的参数,转换为上游节点看到的Fragmenter的参数。
这里把下游节点各manager支持的传输能力大小进行了转换。
3. lazy module
1) 成对的输入边和输出边

2) 如果不需要分片,则直连即可:

3) 限定条件
a. 所有manager的fifoId都相同,因为需要manager按顺序返回响应消息:

b. manager不支持cache:

c. minSize >= beatBytes

这里的beatBytes是真正的总线宽度,虽然minSize经常被设置为与beatBytes相同,但也可以比其大。如果minSize = 2 * beatBytes,那么Fragmenter拆分后的请求基本上都是包含2个beat的burst。
d. 上下游节点都不支持Cache:

e. 如果可能拒绝Get请求,那么需要保持deny信号:

f. 如果可能拒绝Put请求,那么不能提早对其进行响应:

4) beat数目

beatBytes是Fragmenter与下游节点之间的总线宽度,maxSize是上游节点向Fragmenter发起的请求的最大传输大小。
两者的商是最大传输大小的请求,最终对应的针对下游节点的请求的beat数。
对比一下:
maxSize/minSize:最大传输大小的请求,转化为针对下游节点的请求的数目。
如果minSize == beatBytes,那么这个请求的数目即是beat的数目。
如果minSize > beatBytes,那么这个请求的数目是指burst请求的数目。每个burst请求中包含多少个beat,则由minSize/beatBytes的值决定。
即:
maxSize/minSize = 分片的数目 = (burst)请求的数目
maxSize/beatBytes = 所有请求中beat的数目之和
5) maxDownSize
向下游发送请求时能使用的最大传输大小:

6) 响应相关的变量

这里不再详细介绍。
7) 响应处理
A. out.d.fire()

记录如下信息:
a. ackNum:如果是第一个响应消息,那么响应编号(ackNum)= dFirst_AckNum,后面逐个递减ack_Decrement;
b. 记录dOrig;
c. 从source中取出编码进去的toggle位;
B. 计算是否要EarlyAck:

其中,如果earlyAck的类型为只针对PutFull,那么则从source中取出相应的编码位;
C. drop
是否丢弃这一个响应消息:

a. 如果有数据,则不能drop;
b. 如果要EarlyAck,那么不是第一个的响应消息,都应该丢弃;
c. 如果非EarlyAck,那么不是最后一个的响应消息,都应该丢弃;
D. 把out.d导向in.d

E. 处理针对Put的denied信号:
若出现denied信号,则保持住:

需要注意的是:这里的保持denied信号,不是指在单个burst请求的多个beat之间保持。而是指在多个分片请求的响应消息之间保持,每个分片请求都有可能是burst请求。
F. 处理针对Get的denied信号:

8) 请求分片
A. 计算每个manager针对每种操作的最大传输能力

并转换为lg值:

这里如果manager支持的最大能力为0,也就是manager不支持这种操作,使用lgMinSize代替。注释里的意思是:我们寄希望于client不对某个manager发出他不支持的request,所以这里无论是使用lgMinSize代替或者其他任何值,都没有意义。
根据请求访问的地址,确定地址所属的manager,进而确定支持的最大传输大小:

B. 确定分片的最大大小:

C. 请求分片相关的变量

这里不做详细介绍。
D. 使用repeater重复in.a的请求
a. 从in.a输入,输出到in_a:

b. 何时重复in.a?

需要同时满足一下条件:
- 请求消息中没有数据:如果有数据就透传;
- 分片编号不为0,为0代表最后一个分片;
如果没有数据的请求,即Get/Hint请求消息,则把in.a的数据保存到最后一个分片发出为止。
Arithmetic/Logical都带有数据,但是他们的传输大小是被缩小了的,所以下游节点可以支持透传。如果是Put请求呢?其传输大小是被放大了的。这个问题下面单独研究。
E. 组装各个编码位:

F. 两点优化

a. 直连in.a.bits.data到out.a.bits.data,不需要repeater中转
这个问题会在下面单独研究。
b. 如果repeater.io.full为真,则out.a.bits.mask应当为全1
意思是说,如果当前正在发送一个分片,那么这个分片的大小包含下游节点支持的beatBytes中的所有字节。
9) 不支持Cache

4. Put请求
首先,下游节点支持的Put请求的大小,被Fragmenter放大了。
其次,Put请求不经过repeater,而直接传递给out.a。
那么问题来了:
a. Put请求是否分片?如果分片,原始请求在哪里缓存或者说阻塞以等待所有分片请求发完?
b. 如果in.a.bits.data直连out.a.bits.data会不会丢失数据?

进而,针对Get请求:

c. out.d.bits.data直连in.d.bits.data,会不会丢失数据?
直接说结论:这三个问题,实际上都牵涉到数据的传输。数据的传输是由beatBytes也就是总线位宽限定的(而不是请求中的size域)。
那么Fragmenter改变了上游节点和下游节点的总线宽度了吗?答案是没有。
跟一下代码:
a. channel a的data域的宽度由参数params.dataBits决定:
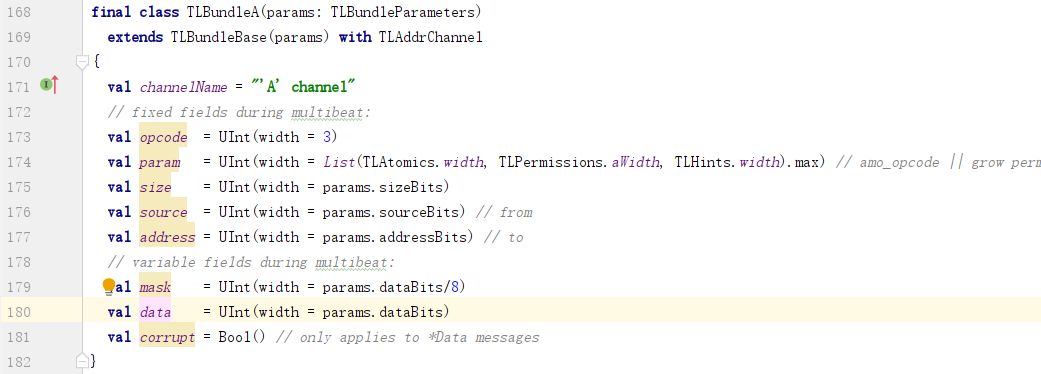
b. params在创建TLBundle时传入:

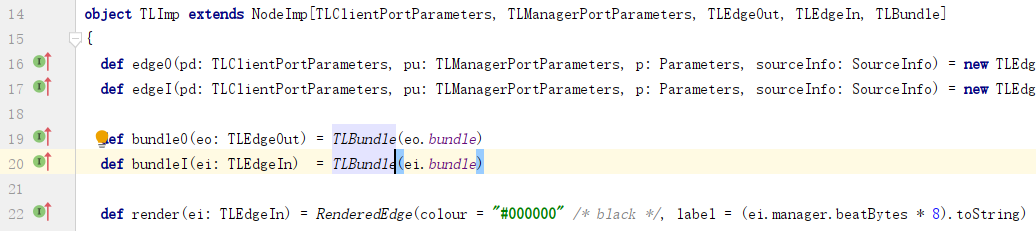
c. 创建输入边和输出边的TLBundle,分别使用输入边和输出边中的bundle参数:
d. TLBundleParameters中的dataBits取决于manager的beatBytes:
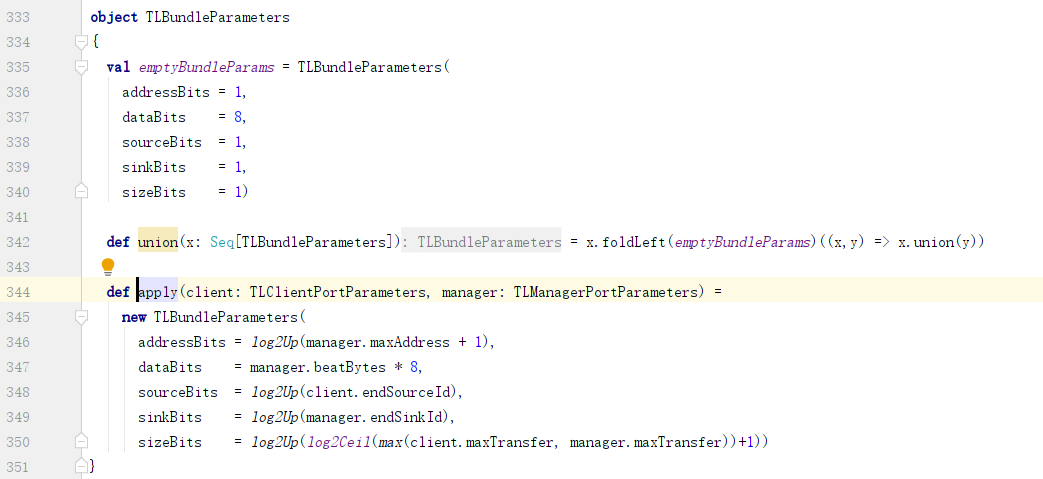
e. 这个manager是指TLManagerPortParameters:

也就是说:
a. Fragmenter与下游节点之间数据总线的宽度,由下游节点的beatBytes参数决定;
b. Fragmenter与上游节点之间数据总线的宽度,由Fragmenter的beatBytes参数决定;
Fragmenter的beatBytes参数由下游节点使用managerFn转换而来:

这个managerFn只改变了支持的能力的大小,并没有改变beatBytes的大小:

也就是说,改变了可以填到channel a的size域的值的大小,并没有改变数据总线的宽度。
这下就好理解了:
a. Put请求,无论size多大,数据终究需要受数据总线的限制,一个beat一个beat的传输。在这种情况下Fragmenter逐个beat透传没有问题。
b. Get请求,无论size多大,返回的数据也终究需要收数据总线的限制,一个beat一个beat的传输。
- Rocket - tilelink - RegisterRouter
https://mp.weixin.qq.com/s/DaJhf7hEoWsEi_AjwSrOfA 简单介绍RegisterRouter的实现. 1. 基本介绍 实现挂在Tile ...
- Rocket - tilelink - HintHandler
https://mp.weixin.qq.com/s/MHW_aBSL72YNee9bVWWeaw 简单介绍HintHandler的实现. 1. 基本功能 实现Hint请求的处理 ...
- Rocket - tilelink - Nodes
https://mp.weixin.qq.com/s/KJ8pVH76rdxPOZ1vE3QlKA 简单介绍tilelink对Diplomacy Nodes的实现. 1. TLImp ...
- Rocket - tilelink - AsyncCrossing
https://mp.weixin.qq.com/s/v8plWCBD8vZkxykjJe4TCg 介绍AsyncCrossing的实现,主要介绍如何实现diplomacy Node和LazyMo ...
- Rocket - tilelink - mask
https://mp.weixin.qq.com/s/Gqv09RIgSSg5VKe-wb4aGg 讨论tilelink中使用MaskGen生成mask的用法. 1. tilelink中的ma ...
- Rocket - tilelink - Parameters
https://mp.weixin.qq.com/s/1I6DcONr0Mg7xiX8F1C7SQ 简单介绍TileLink相关的参数实现(具体问题暂时不展开,后续用到时再做分析). ...
- Rocket - tilelink - Bundles
https://mp.weixin.qq.com/s/jrqBg2AIpQogBrpwNXjmwg 简单介绍Bundles文件中对TileLink规范(1.7.1)的定义. 参考链接:https: ...
- Rocket - tilelink - TLBusWrapper.to
https://mp.weixin.qq.com/s/jSnhBzU5_ayQCg5fWAcx-g 简单介绍TLBusWrapper.to()的实现.主要介绍确定this{...}对应代码的过程. 1 ...
- Rocket - tilelink - BusWrapper
https://mp.weixin.qq.com/s/03BvgTNQtD75Guco6gUGQg 简单介绍BusWrapper的实现. 1. HasTLBusParams 定义SoC的挂 ...
随机推荐
- D. Equalize the Remainders set的使用+思维
D. Equalize the Remainders set的学习::https://blog.csdn.net/byn12345/article/details/79523516 注意set的end ...
- V - Can you answer these queries? HDU - 4027 线段树 暴力
V - Can you answer these queries? HDU - 4027 这个题目开始没什么思路,因为不知道要怎么去区间更新这个开根号. 然后稍微看了一下题解,因为每一个数开根号最多开 ...
- 单元测试中使用Spring的ReflectionTestUtils更方便
1 简介 ReflectionUtils是Spring中一个常用的类,属于spring-core包:ReflectionTestUtils则属于spring-test包.两者功能有重叠的地方,而Ref ...
- SQL SERVER 函数举例
需求说明 将字符串按照指定的分隔符进行分割,并将结果按照从后往前的顺序倒序排列,拼接后的结果用‘/’符连接.(也可以按照指定符号分割为多个列,修改最后一部分即可) 创建测试表及数据 /* 创建一张测试 ...
- 面向开发者的Docker实践
show me the code and talk to me,做的出来更要说的明白 本文源码,请点击learnSpringboot 我是布尔bl,你的支持是我分享的动力! 一. 引入 有开发经验的都 ...
- 王颖奇 20171010129《面向对象程序设计(java)》第十一周学习总结
实验十一 集合 实验时间 2018-11-8 1.实验目的与要求 (1) 掌握Vetor.Stack.Hashtable三个类的用途及常用API: (2) 了解java集合框架体系组成: (3) ...
- Azkaban无法连接网页
出的问题如下图 首先我查看日志看到有一个 [ERROR] 2020/03/13 11:12:34.417 +0800 ERROR [PluginCheckerAndActionsLoader] [Az ...
- STM32 ADC多通道规则采样和注入采样
layout: post tags: [STM32] comments: true 文章目录 layout: post tags: [STM32] comments: true 什么是ADC? STM ...
- 从浅入深——理解JSONP的实现原理
由于浏览器的安全性限制,不允许AJAX访问 协议不同.域名不同.端口号不同的 数据接口,浏览器认为这种访问不安全: 可以通过动态创建script标签的形式,把script标签的src属性,指向数据接口 ...
- [hdu5400 Arithmetic Sequence]预处理,容斥
题意:http://acm.hdu.edu.cn/showproblem.php?pid=5400 思路:预处理出每个点向左和向右的最远边界,从左向右枚举中间点,把区间答案加到总答案里面.由与可能与前 ...