Algorithms - Data Structure - Perfect Hashing - 完全散列
相关概念
散列表 hashtable 是一种实现字典操作的有效数据结构.
在散列表中,不是直接把关键字作为数组的下标,而是根据关键字计算出相应的下标. 散列函数 hashfunction'h'
除法散列法
通过取k除以m的余数,将关键k映射到m个slot中的某一个上.即散列函数为:h(k)=kmodm
比如:散列表的大小m=12,关键字k=100,则h(k)=100mod12=4,放到slot4中.
由于只需做一次除法,所以除法散列法速度非常快.
当选择除法散列法的时候,要避免选择m的某些值。例如,m不应为2的幂.因为如果m=2的p次幂.
则h(k)=就是k的p个最低位数字.
一个不太接近2的整数次幂的素数,常常是m的一个较好的选择.例如,假定我们要分配一个张散列表用链接
法解决冲突,表中大约要存放n=2000个字符串,其中每个字符串有8位.如果我们不介意一次不成功的查找
需要平均检查3个元素,这样分配散列表的大小为701.因为701是一个接近2000/3但是又不接近2的任何次幂的素数. 乘法散列法
乘法散列法包含两个步骤:第一:用关键字k乘上常数A(0<A<1),并提取kA的小数部分.
第二步,用m乘以这个值,再向下取整:h(k)=int(m(KAmod1))
乘法散列的一个优点是对m的选择不是特别关键,一般选m为2个某个次幂.m=2的p次幂. 开放寻址 openaddressing
开放寻址openaddressing中,所有元素都存放在散列表里.
每个表项或包含动态集合的一个元素,或包含NIL.当查找某个元素的时候,要系统的检查所有表项,直到找到所需的元素或最终找不到该元素. 有三种技术常用来计算开放寻址法中的probesequence探查序列:线性探查,二次探查和双重探查.
线性探查 linearprobing: 散列函数:h(k,i)=(h'(k)+i)modm
二次探查 quadraticprobing:散列函数:h(k,i)=(h'(k)+c1i+c2i*i)modm
双重散列 doublehashing:是用于开放寻址的最好方法,因为它所产生的排列具有随机选择排列的许多特性. 散列函数:h(k,i)=(h1(k)+i*h2(k)modm
为了能查找整个散列表,值h2(k)必须要与表的大小m互素.一种简单的方法确保这个条件成立,就是取m为2的幂.
并设计一个总产生奇数的h2.另一个方法是:取m为素数,并设计一个总是返回较m小的正整数的函数h2.
例如: h1(k) = k mod m, h2(k) = 1 + (k mod m') , 其中 m' 略小于 m, 比如 m' = m-1
Python program
Perfect hashing
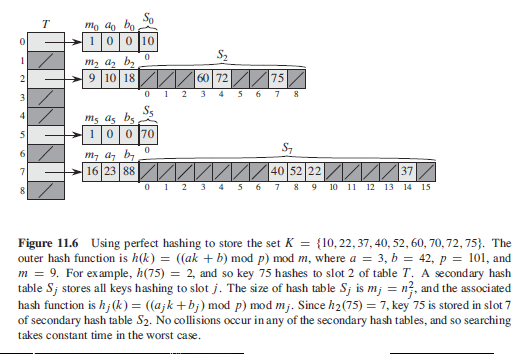
Using perfect hashing to store K=[10,22,37,40,52,60,70,72,75]
注: 下图中所示元素 40 的位置是不对的. 最后 T 为:
T = [[1,0,0,10], 'NIL', [9,10,18,'NIL','NIL','NIL',60,72,'NIL','NIL',75,'NIL'], \
'NIL', 'NIL', [1,0,0,70], 'NIL', [16,23,88,'NIL','NIL','NIL','NIL','NIL','NIL',\
40,52,22,'NIL','NIL','NIL','NIL',32,'NIL'], 'NIL']
def produce_t(T0):
import copy
T = copy.deepcopy(T0)
for i in range(len(T)):
if T[i] != 'NIL':
T[i] = T[i] + ['NIL' for x in range(T[i][0])]
return T def h(k, m=9, a=3, b=42, p=101,): # h function
# a = 3
# b = 42
# p = 101
# m = 9
return ((a*k + b) % p)%m def perfect_hash(T, k):
h1 = h(k)
h2 = h(k,T[h1][0],T[h1][1],T[h1][2])
T[h1][h2+3] = k
print(' h1 and h2 : ', h1,h2) if __name__ == '__main__':
#m = 9 K = [10, 22, 37, 40, 52, 60, 70, 72, 75]
# T = [[1,0,0,10], 'NIL', [9,10,18,'NIL','NIL','NIL',60,72,'NIL','NIL',75,'NIL'], \
# 'NIL', 'NIL', [1,0,0,70], 'NIL', [16,23,88,'NIL','NIL','NIL','NIL','NIL','NIL',\
# 40,52,22,'NIL','NIL','NIL','NIL',32,'NIL'], 'NIL'] T0 = [[1, 0, 0], 'NIL', [9, 10, 18], 'NIL', 'NIL', [1, 0, 0], 'NIL', [16, 23, 88], 'NIL'] print('Initializing T')
T = produce_t(T0)
#print(T0)
print('T: ', T) print('example of the element 75')
print('h result of 75')
print(h(75))
print('Hashing of 75')
perfect_hash(T, 75)
print('T: ', T) print('Hashing of list K')
for i in K:
print('Hashing of : ', i)
perfect_hash(T,i)
print('T: ', T) 结果打印:
Initializing T
T: [[1, 0, 0, 'NIL'], 'NIL', [9, 10, 18, 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL'],
'NIL', 'NIL', [1, 0, 0, 'NIL'], 'NIL',
[16, 23, 88, 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL'], 'NIL']
example of the element 75
h result of 75
2
Hashing of 75
h1 and h2 : 2 7
T: [[1, 0, 0, 'NIL'], 'NIL', [9, 10, 18, 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 75, 'NIL'],
'NIL', 'NIL', [1, 0, 0, 'NIL'], 'NIL',
[16, 23, 88, 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL', 'NIL'], 'NIL']
Hashing of list K
Hashing of : 10
h1 and h2 : 0 0
Hashing of : 22
h1 and h2 : 7 9
Hashing of : 37
h1 and h2 : 7 14
Hashing of : 40
h1 and h2 : 7 3
Hashing of : 52
h1 and h2 : 7 8
Hashing of : 60
h1 and h2 : 2 3
Hashing of : 70
h1 and h2 : 5 0
Hashing of : 72
h1 and h2 : 2 4
Hashing of : 75
h1 and h2 : 2 7
T: [[1, 0, 0, 10], 'NIL', [9, 10, 18, 'NIL', 'NIL', 'NIL', 60, 72, 'NIL', 'NIL', 75, 'NIL'],
'NIL', 'NIL', [1, 0, 0, 70], 'NIL',
[16, 23, 88, 'NIL', 'NIL', 'NIL', 40, 'NIL', 'NIL', 'NIL', 'NIL', 52, 22, 'NIL', 'NIL', 'NIL', 'NIL', 37, 'NIL'], 'NIL']
Reference
1. Introduction to algorithms
Algorithms - Data Structure - Perfect Hashing - 完全散列的更多相关文章
- 【Java集合学习】HashMap源码之“拉链法”散列冲突的解决
1.HashMap的概念 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射. HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io ...
- Hashing散列注意事项
Hashing散列注意事项 Numba支持内置功能hash(),只需__hash__()在提供的参数上调用成员函数即可 .这使得添加对新类型的哈希支持变得微不足道,这是因为扩展APIoverload_ ...
- PAT A1145 Hashing - Average Search Time (25 分)——hash 散列的平方探查法
The task of this problem is simple: insert a sequence of distinct positive integers into a hash tabl ...
- [Algorithms] Tree Data Structure in JavaScript
In a tree, nodes have a single parent node and may have many children nodes. They never have more th ...
- [No0000132]正确使用密码加盐散列[译]
如果你是一个 web 开发工程师,可能你已经建立了一个用户账户系统.一个用户账户系统最重要的部分是如何保护密码.用户账户数据库经常被黑,如果你的网站曾经被攻击过,你绝对必须做点什么来保护你的用户的密码 ...
- 散列(Hash)表入门
一.概述 以 Key-Value 的形式进行数据存取的映射(map)结构 简单理解:用最基本的向量(数组)作为底层物理存储结构,通过适当的散列函数在词条的关键码与向量单元的秩(下标)之间建立映射关系 ...
- 【数据结构与算法Python版学习笔记】查找与排序——散列、散列函数、区块链
散列 Hasing 前言 如果数据项之间是按照大小排好序的话,就可以利用二分查找来降低算法复杂度. 现在我们进一步来构造一个新的数据结构, 能使得查找算法的复杂度降到O(1), 这种概念称为" ...
- Java 消息摘要 散列 MD5 SHA
package xxx.common.util; import java.math.BigInteger; import java.security.MessageDigest; import jav ...
- 个人理解c#对称加密 非对称加密 散列算法的应用场景
c#类库默认实现了一系列加密算法在System.Security.Cryptography; 命名空间下 对称加密 通过同一密匙进行加密和解密.往往应用在内部数据传输情况下.比如公司a程序 和B程序 ...
随机推荐
- CSS常用遮罩层
为什么80%的码农都做不了架构师?>>> CSS常用遮罩层 应用场景: 上传了一张图片,鼠标移入到图片上的时候显示遮罩层,并且提示点击删除. 通过改变遮罩层的透明度来实现显示隐藏 ...
- 发布AI芯片昆仑和百度大脑3.0、L4自动驾驶巴士量产下线,这是百度All in AI一年后的最新答卷...
机器之心报道,作者:李泽南. 去年的 7 月 5 日,百度在北京国际会议中心开办了首届「AI 开发者大会」.在会上,百度首次喊出了「All in AI」的口号.一年的时间过去了,今天在同样地点举行的第 ...
- 写代码?程序猿?你不能不懂的八大排序算法的Python实现
信息获取后通常需要进行处理,处理后的信息其目的是便于人们的应用.信息处理方法有多种,通常由数据的排序,查找,插入,删除等操作.本章介绍几种简单的数据排序算法和高效的排序算法. 本章主要涉及到的知识点有 ...
- CodeForces - 260C
CodeForces - 260C Little Vasya had n boxes with balls in the room. The boxes stood in a row and were ...
- UVA352 The Seasonal War
本文为UserUnknown原创 题目本身不难理解,就是深搜(或广搜,有可能以后会加在这里). 但是洛谷的题目中没有截到输入输出的格式,下面是我从UVA复制下来的样例: Sample input 6 ...
- 题解 CF1286A 【Garland】
updata on 2020.3.19 往博客园搬的时候看了看自己以前写的blog 其实没多久,才两个多月,感觉自己之前写的东西好罗嗦啊.. 但也是最近写的blog才开始多起来 当然现在也没好到哪去. ...
- LeetCode 25. K 个一组翻转链表 | Python
25. K 个一组翻转链表 题目来源:https://leetcode-cn.com/problems/reverse-nodes-in-k-group 题目 给你一个链表,每 k 个节点一组进行翻转 ...
- shell之路 shell核心语法【第一篇】shell初识
shell简介 1.Shell是Unix的脚本语言,是与 Unix/Linux 交互的工具,shell使用的熟练程度反映了用户对Unix/Linux使用的熟练程度 2.Shell是系统命令+程序逻辑的 ...
- B - Housewife Wind POJ - 2763 树剖+边权转化成点权
B - Housewife Wind POJ - 2763 因为树剖+线段树只能解决点权问题,所以这种题目给了边权的一般要转化成点权. 知道这个以后这个题目就很简单了. 怎么转化呢,就把这个边权转化为 ...
- 网络流 + 欧拉回路 = B - Sightseeing tour POJ - 1637
B - Sightseeing tour POJ - 1637 https://blog.csdn.net/qq_36551189/article/details/80905345 首先要了解一下欧拉 ...