hadoop 3.x 配置日志聚集功能
打开$HADOOP_HOME/etc/hadoop/yarn-site.xml,增加以下配置(在此配置文件中尽量不要使用中文注释)
<!--logs-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- logs keep time -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
依次执行以下命令start-dfs.sh,start-yarn.sh.mr-jobhistory-daemon.sh start historyserver启动完毕后jps
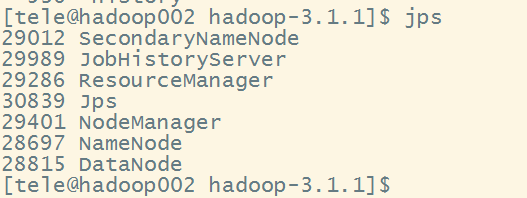
接下来执行MapReduce程序
hadoop fs -rm -r -f /usr/tele/hadoop/wcoutput
hadoop jar /opt/module/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /usr/tele/hadoop/wcinput /usr/tele/hadoop/wcoutput
执行完毕后打开mapreduce管理界面(8088),再打开history(19888),然后打开logs
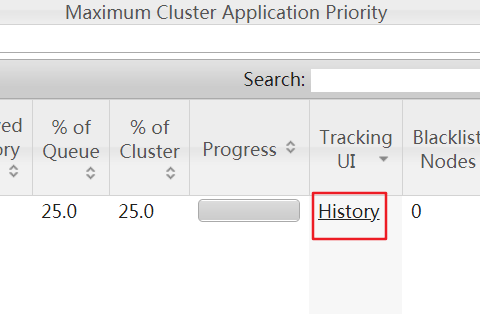
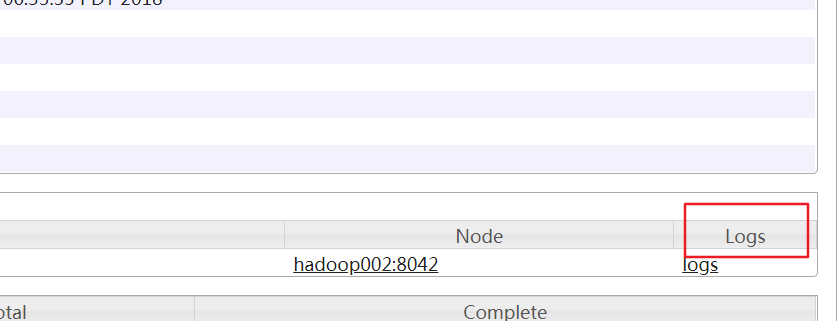
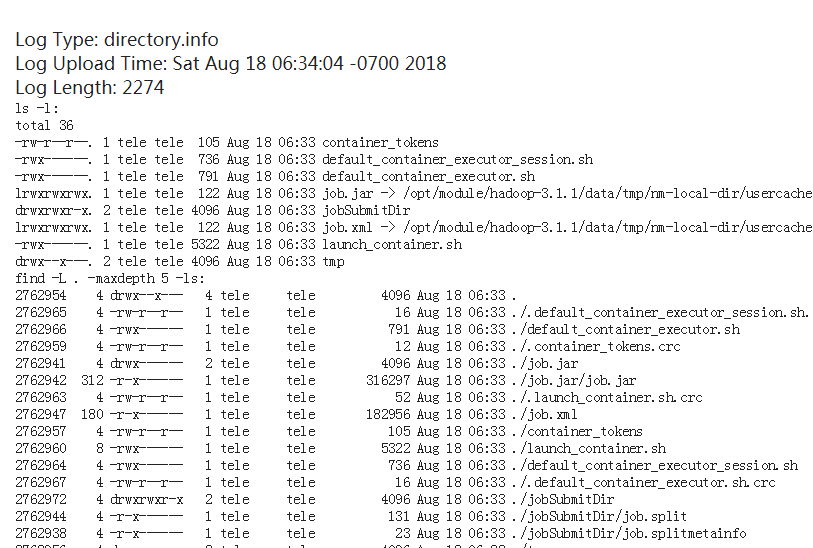
注意的是如果启用了日志聚集功能,那么在userlogs下生成的yarn的作业日志目录在被上传到hdfs上之后就会从linux上删除掉了,大概在执行完mapreduce程序的几秒后
history打不开的请参考https://www.cnblogs.com/tele-share/p/9498698.html
hadoop 3.x 配置日志聚集功能的更多相关文章
- Hadoop基础-完全分布式模式部署yarn日志聚集功能
Hadoop基础-完全分布式模式部署yarn日志聚集功能 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 其实我们不用配置也可以在服务器后台通过命令行的形式查看相应的日志,但为了更方 ...
- Yarn 的日志聚集功能配置使用
需要 hadoop 的安装目录/etc/hadoop/yarn-site.xml 中进行配置 配置内容 <property> <name>yarn.log-aggregati ...
- hadoop配置历史服务器&&配置日志聚集
配置历史服务器 1.在mapred-site.xml中写入一下配置 <property> <name>mapreduce.jobhistory.address</name ...
- 开启spark日志聚集功能
spark监控应用方式: 1)在运行过程中可以通过web Ui:4040端口进行监控 2)任务运行完成想要监控spark,需要启动日志聚集功能 开启日志聚集功能方法: 编辑conf/spark-env ...
- 启用yarn日志聚集功能
在yarn-site.xml配置文件中添加如下内容: ##开启日志聚集功能 <property> <name>yarn.log-ag ...
- Hadoop 历史服务配置启动查看
历史服务配置启动查看 1)配置mapred-site.xml <property> <name>mapreduce.jobhistory.address</name> ...
- hadoop之 YARN配置参数剖析—RM与NM相关参数
参数均需要在yarn-site.xml中配置: 1. ResourceManager相关配置参数 (1) yarn.resourcemanager.address 参数解释:ResourceManag ...
- yarn配置日志聚合
[原文地址] 日志聚集是YARN提供的日志中央化管理功能,它能将运行完成的Container/任务日志上传到HDFS上,从而减轻NodeManager负载,且提供一个中央化存储和分析机制.默认情况下, ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
随机推荐
- (转)Windows Server 2012 R2虚拟机自激活(AVMA)技术
转自: 老丁的技术博客 相信Hyper-v管理员都有这样的经历,安装多台虚拟机后,都要一台一台手工激活,如果虚拟机足够多的话,这是一项很繁琐的工作,但从Windows Server 2012 R2开始 ...
- Day1:变量
一.变量用来干嘛的 用来存东西的,方便后面调用 二.如何定义变量 name = "Hiuhung Wan" 变量名 = 值,一个等号是赋值号,右边的值赋值给左边 三.变量的一些用法 ...
- Loadrunner--运行场景报Socket descriptor not found错误
今天早上在使用LoadRunner时,报了如下的错误,开始并未看错误以为是录制问题引起,就重新录制了一遍,简单施压看看错误是否还有,结果错误仍然有,如下所示: Error: Socket descri ...
- 【Codeforces Round #299 (Div. 2) A】 Tavas and Nafas
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 模拟题 [代码] #include <bits/stdc++.h> using namespace std; map & ...
- struts2_7_Action类中方法的动态调用
(一)直接调用方法(不推荐使用) 1)Action类: private String savePath; public String getSavePath() { return savePath; ...
- 使用PHP实现双向队列
使用PHP实现双向队列 一.总结 就是几个array函数 push pop shift unshift n. 移动:变化:手段:轮班 vi. 移动:转变:转换 vt. 转移:改变:替换 二.使用PHP ...
- Android java.lang.IllegalArgumentException: Object returned from onCreateLoader must not be a non-static inn
AsyncTaskLoader: http://developer.Android.com/intl/zh-CN/reference/android/content/AsyncTaskLoader.h ...
- vivado中basic memory生成
vivado中basic memory生成
- [Nuxt] Add CSS Libraries to Nuxt
You can easily add CSS libraries to Nuxt using yarn or npm to install them, then simply adding them ...
- 页面中如何引用外部的HTML(四种方法)
页面中如何引用外部的HTML(四种方法) 一.总结 一句话总结:a.iframe标签 b.ajax引入代码片段 c.link import的方法导入 d.re ...