二叉堆 与 PriorityQueue
堆在存储器中的表示是数组,堆只是一个概念上的表示。堆的同一节点的左右子节点都没有规律。
堆适合优先级队列(默认排列顺序是升序排列,快速插入与删除最大/最小值)。
数组与堆
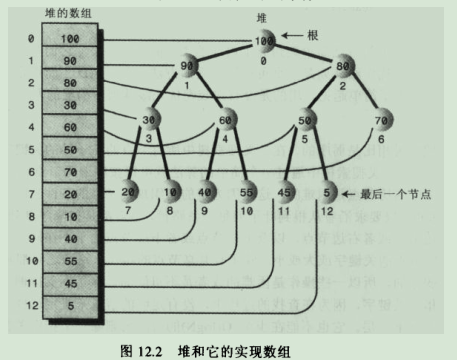
堆(完全二叉树)(构造大顶堆或者小顶堆的时间复杂度:O(logn))
堆实现的优先级队列虽然和数组实现相比删除慢了些,但插入的时间快的多了:
当速度很重要且有很多插入操作时,可以选择堆来实现优先级队列。
堆插入删除的效率:时间复杂度是:O(logn)。
小顶堆:父节点的值 <= 左右孩子节点的值
大顶堆:父节点的值 >= 左右孩子节点的值
堆的定义:n个关键字序列array[0,...,n-1]:
若array[0,...,n-1]表示一颗完全二叉树的顺序存储模式,则双亲节点指针和孩子结点指针之间的内在关系如下:
任意一节点指针 i(0 <= i <= (n-1)/2) : 父节点:i==0 ? null : (i-1)/2
左孩子:2*i + 1
右孩子:2*i + 2
① array[i] <= array[2*i + 1] 且 array[i] <= array[2*i + 2] : 称为小根堆
② array[i] >= array[2*i + 1] 且 array[i] >= array[2*i + 2] : 称为大根堆
堆的插入( add(e),offer(e) ):添加到末尾,由于可能破坏堆结构,需要调整(向上筛选)
插入使用向上筛选,向上筛选的算法比向下筛选的算法相对简单,因为它不需要比较两个子节点关键字值的大小
删除操作 ( remove(o) ):由于可能破坏堆结构,需要调整(向下筛选)
删除堆顶 ( poll() ):由于可能破坏堆结构,需要调整(向下筛选)
移除是指删掉关键字值最大的节点,即根节点。
在被筛选节点的每个暂时停留的位置,向下筛选的算法总是要检查哪一个子节点更大,然后目标节点和较大的子节点交换位置
堆排序(时间复杂度:O(nlogn))
堆排序是一种树形选择排序方法,它的特点是:
在排序的过程中,将array[0,...,n-1]看成是一颗完全二叉树的顺序存储结构,
利用完全二叉树中双亲节点和孩子结点之间的内在关系,在当前无序区中选择关键字最大(最小)的元素。
步骤:
构造堆
固定最大值再构造堆(将最大值元素(堆头)与堆尾元素交换,将其他数再构造成最大堆)
重复上述过程
堆(二叉堆)排序的时间复杂度,最好,最差,平均都是O(nlogn),空间复杂度O(1),是不稳定的排序。
PriorityQueue
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
private static final long serialVersionUID = -7720805057305804111L;
private static final int DEFAULT_INITIAL_CAPACITY = 11;
transient Object[] queue; // non-private to simplify nested class access
int size;
private final Comparator<? super E> comparator;
transient int modCount; // non-private to simplify nested class access
public PriorityQueue(Collection<? extends E> c) {} //使用已有集合构建二叉堆
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
}
//自定义比较器,降序排列
static Comparator<Integer> cmp = new Comparator<Integer>() {
public int compare(Integer e1, Integer e2) {
return e2 - e1;
}
};
在未排序的数组中找到第 k 个最大的元素
/**
* 示例 1:
* 输入: [3,2,1,5,5,4] 和 k = 2
* 输出: 5
*
* 时间复杂度 : O(Nlogk)。
* 空间复杂度 : O(k),用于存储堆元素。
*/
/**
* 小顶堆
*/
class Solution {
public int findKthLargest(int[] nums, int k) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
for (int i = 0; i < nums.length; i++) {
pq.add(nums[i]);
if(pq.size()>k)pq.poll();
}
return pq.poll();
}
}
找出动态有序列表的中位数
/**
* 中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
*
* 例如,
* [2,3,4] 的中位数是 3
* [2,3] 的中位数是 (2 + 3) / 2 = 2.5
*
* 方法:最大堆与最小堆。
* 思路:各存储一半,最大堆的堆顶比最小堆的堆顶小。
*
* 时间复杂度:O(logN),从堆里得到一个 “最值” 而其它元素无需排序
* 空间复杂度:O(N)
*/
class MedianFinder1 {
/**
* 当前大顶堆和小顶堆的元素个数之和
*/
private int count;
private PriorityQueue<Integer> maxheap;
private PriorityQueue<Integer> minheap;
/**
* initialize your data structure here.
*/
public MedianFinder1() {
count = 0;
maxheap = new PriorityQueue<>((x, y) -> y - x); //大顶堆
minheap = new PriorityQueue<>(); //小顶堆
}
public void addNum(int num) {
count += 1;
maxheap.offer(num);
minheap.add(maxheap.poll());
// 如果两个堆合起来的元素个数是奇数,小顶堆要拿出堆顶元素给大顶堆
if ((count & 1) != 0) {
maxheap.add(minheap.poll());
}
}
public double findMedian() {
if ((count & 1) == 0) {
// 如果两个堆合起来的元素个数是偶数,数据流的中位数就是各自堆顶元素的平均值
return (double) (maxheap.peek() + minheap.peek()) / 2;
} else {
// 如果两个堆合起来的元素个数是奇数,数据流的中位数大顶堆的堆顶元素
return (double) maxheap.peek();
}
}
}
最强堆排序文章
https://blog.csdn.net/u010452388/article/details/81283998
二叉堆 与 PriorityQueue的更多相关文章
- D&F学数据结构系列——二叉堆
二叉堆(binary heap) 二叉堆数据结构是一种数组对象,它可以被视为一棵完全二叉树.同二叉查找树一样,堆也有两个性质,即结构性和堆序性.对于数组中任意位置i上的元素,其左儿子在位置2i上,右儿 ...
- python下实现二叉堆以及堆排序
python下实现二叉堆以及堆排序 堆是一种特殊的树形结构, 堆中的数据存储满足一定的堆序.堆排序是一种选择排序, 其算法复杂度, 时间复杂度相对于其他的排序算法都有很大的优势. 堆分为大头堆和小头堆 ...
- 优先队列之二叉堆与d-堆
二叉堆简介 平时所说的堆,若没加任何修饰,一般就是指二叉堆.同二叉树一样,堆也有两个性质,即结构性和堆序性.正如AVL树一样,对堆的以此操作可能破坏者两个性质中的一个,因此,堆的操作必须要到堆的所有性 ...
- 《数据结构与算法分析:C语言描述》复习——第五章“堆”——二叉堆
2014.06.15 22:14 简介: 堆是一种非常实用的数据结构,其中以二叉堆最为常用.二叉堆可以看作一棵完全二叉树,每个节点的键值都大于(小于)其子节点,但左右孩子之间不需要有序.我们关心的通常 ...
- 二叉堆(binary heap)—— 优先队列的实现
二叉堆因为对应着一棵完全二叉树,因而可以通过线性数组的方式实现. 注意,数组第 0 个位置上的元素,作为根,还是第 1 个位置上的元素作为根? 本文给出的实现,以数组第 1 个位置上的元素作为根,则其 ...
- 纯数据结构Java实现(6/11)(二叉堆&优先队列)
堆其实也是树结构(或者说基于树结构),一般可以用堆实现优先队列. 二叉堆 堆可以用于实现其他高层数据结构,比如优先队列 而要实现一个堆,可以借助二叉树,其实现称为: 二叉堆 (使用二叉树表示的堆). ...
- 【nodejs原理&源码杂记(8)】Timer模块与基于二叉堆的定时器
[摘要] timers模块部分源码和定时器原理 示例代码托管在:http://www.github.com/dashnowords/blogs 一.概述 Timer模块相关的逻辑较为复杂,不仅包含Ja ...
- 【nodejs原理&源码杂记(8)】Timer模块与基于二叉堆的定时器
目录 一.概述 二. 数据结构 2.1 链表 2.2 二叉堆 三. 从setTimeout理解Timer模块源码 3.1 timers.js中的定义 3.2 Timeout类定义 3.3 active ...
- 二叉堆的BuildHeap操作
优先队列(二叉堆)BuildHeap操作 \(BuildHeap(H)\)操作把\(N\)个关键字作为输入并把它们放入空堆中.显然,这可以使用\(N\)个相继的\(Insert\)操作来完成.由于每个 ...
随机推荐
- ECUST_Algorithm_2019_3
简要题意及解析 1001 给出一个\(n\times m\)连连看的局面,下面有\(q\)次询问:两个位置的块能否消去,即两个位置的连线是否能少于两次转折,回答\(YES/NO\).与一般的连连看不同 ...
- oracle trim无效?
这里说说如果是全角空格怎么去除 方法一 trim(TO_SINGLE_BYTE('aaa')) 方法二 SELECT TRIM(replace('aaa',' ','')) FROM dual
- 07-图5 Saving James Bond - Hard Version(30 分)
This time let us consider the situation in the movie "Live and Let Die" in which James Bon ...
- POJ 2387 Til the Cows Come Home (dijkstra模板题)
Description Bessie is out in the field and wants to get back to the barn to get as much sleep as pos ...
- RealsenseD415/D435深度相机常用资料汇总
1.Realsense SDK 2.0 Ubuntu 16.04 安装指导网址https://github.com/IntelRealSense/librealsense/blob/master/do ...
- 巴厘岛的雕塑(sculptures)
巴厘岛的雕塑(sculptures) 印尼巴厘岛的公路上有许多的雕塑,我们来关注它的一条主干道. 在这条主干道上一共有 N 座雕塑,为方便起见,我们把这些雕塑从 1 到 N 连续地进行标号,其中第 i ...
- jq动画效果慢慢滚动到固定位置
function contentTop(top){ $('body,html').animate({ scrollTop: top }, 500 ); } 获取元素top传入即可 contentTop ...
- Hive 时间操作函数(转)
1.日期函数UNIX时间戳转日期函数: from_unixtime 语法: from_unixtime(bigint unixtime[, string format]) 返回值: string ...
- appium 环境搭建(不推荐安装此版本appium,推荐安装appium desktop)
一:安装node.js 1.双击这个软件 2.一键安装,全都下一步,不要私自更改安装路径 3.打开cmd,输入npm,出现如下截图表示成功 二:安装appium 1.双击appium-installe ...
- 运维01 VMware与Centos系统安装
VMware与Centos系统安装 今日任务 1.Linux发行版的选择 2.vmware创建一个虚拟机(centos) 3.安装配置centos7 4.xshell配置连接虚拟机(centos) ...