.NET 爬虫总结
前言
技术本身并无罪,罪恶本质在于人心,好比厨师手中的菜刀用来创造美味佳肴,而杀手手上的刀却用来创造无限的罪恶.
环境
win7 IIS 6.0 SQLserver2012 .NET 4.0 winform开发
工作原理
利用.Net自带HTTP请求定点访问指定地址,精确登录,精确下载(注意:只针对有下载功能)
目的
针对无开发能力或开发能力有限客户群体 通过该方式实现直连互通效果,但在开发之前需通知对方表明来意否则很容易被服务器认定为攻击行为(特别是测试阶段),开发过程中也会记录一些遇到的困难以及防范类似爬虫的方式
结构图
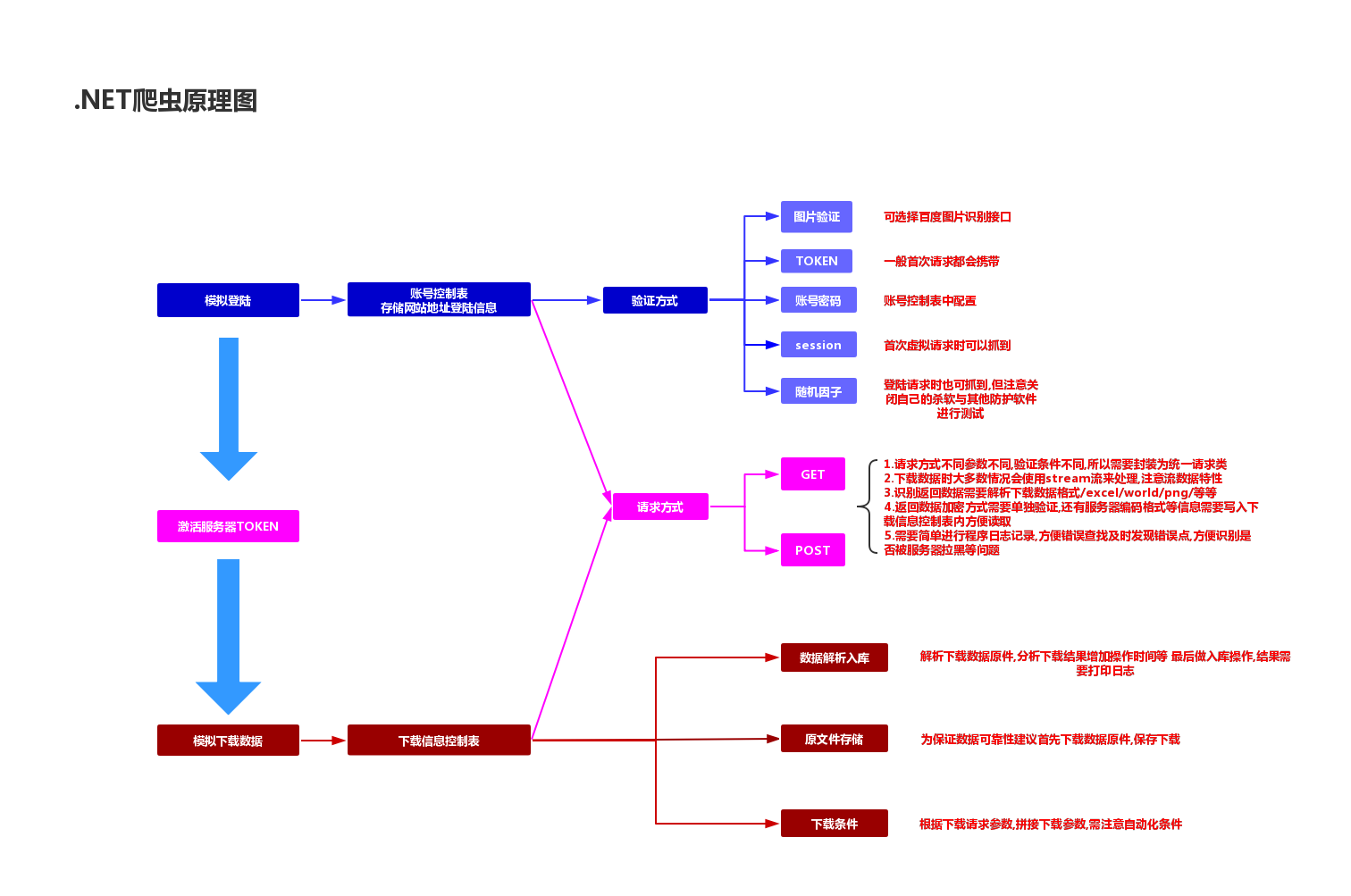
实现过程
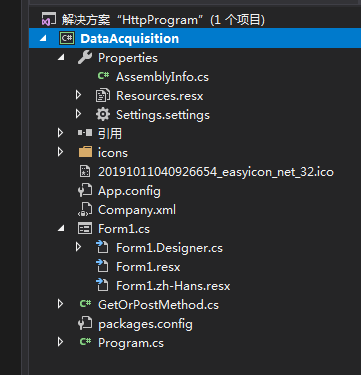
创建空白解决方案,创建winform程序,添加手动按钮 时间戳 等等,主要是textbox 用来记录程序执行过程方便精准定位错误以及实时报告获取进度

增加时间戳控件后需要设置时间实时更新,双击控件 或右键<查看代码> 进行编辑 注意时间戳控件会在 designer 中创建对应事件 而需要做的只是吧当前时间赋值到这个框里,注意图一 是系统自动创建事件 在form1.designer文件中图二在form1.cs文件中,这样时间控件就准备好了,
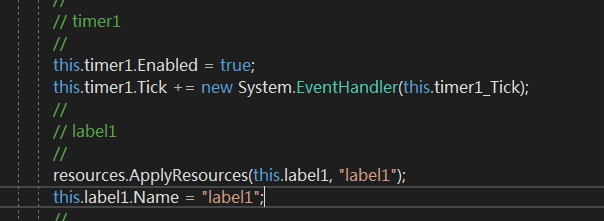
 .
.
当然日志相对来说简单多了,在textbox中增加行就可以了,但是在这里依然遇到很多问题例如,如果用listbox会更好看一点但是添加的时候很麻烦,所以放弃了.

准备工作就此结束,开始进入正题,首先使用xml表来创建网站基本信息(建议坐在数据库),为长远考虑 数据库存放最安全,这次仅做测试

创建好文件后首先编写核心调用工具类 get/post 请求 模拟请求所需参数都需要存入这个xml文件中 作为信息对象的一部分
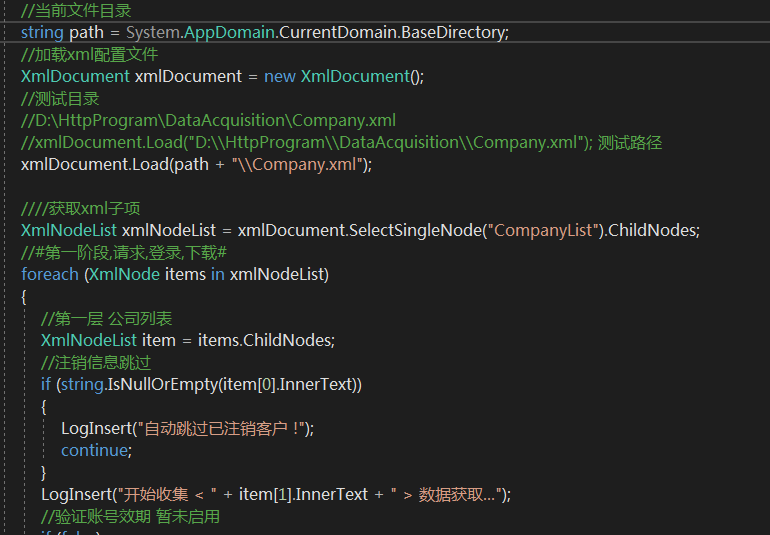
##第一步## 获取通行证
在进行发起流程之前首先需要访问想要登录的网站,也就是Get请求该网站获取网站放置本地的未激活sessionkey
需要注意sessionkey有很多方式存在浏览器中,有意防护会在浏览器中存储session或者加密信息作为识别用户的方式,注意!! 很有可能不是通过post或get请求返回的参数 而是服务器直接设置的参数!!!! 找到它!!! 给他存起来 这是一张未激活的通行证
一般情况下通行证是cookie,还有session啊以及回传一些密文等等,发送请求之前需要建立连接也就是打开浏览器后输入网址那一刻
这里需要注意http与https区别 对应版本是否一致 这里我采用的是.net httpwebrequest/httpwebresponse 简单实现get请求与post请求
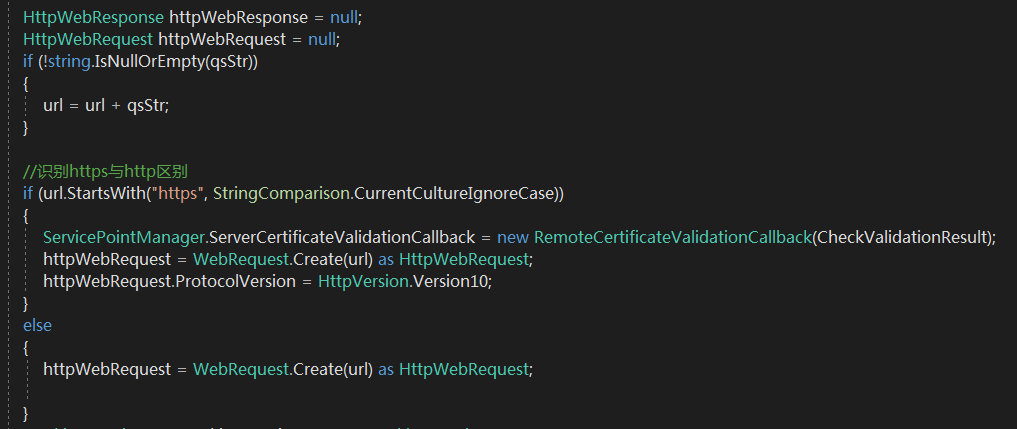
接下来就要给这个通行证盖章了,首先需要搞个萝卜章,分析post请求和get请求必要参数
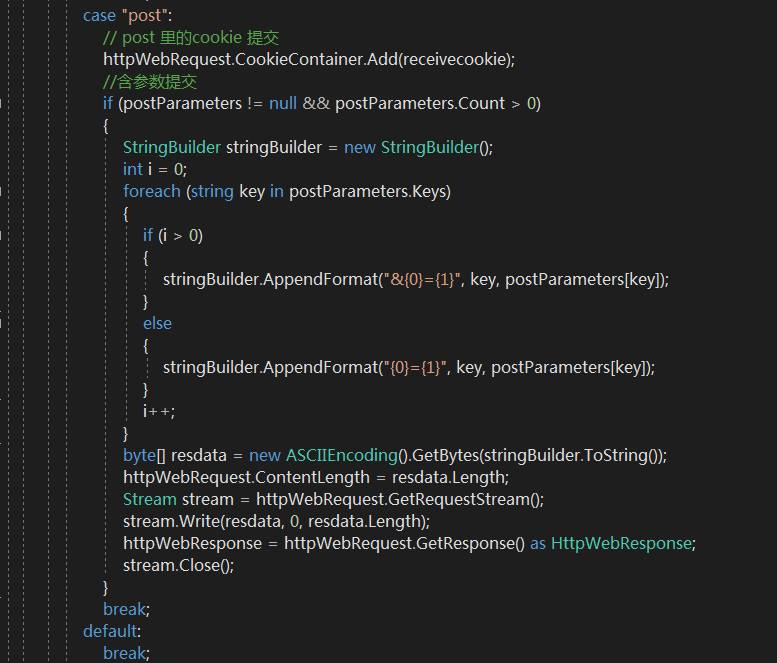
1.post 请求参数
① 账号/密码 输入格式 参数名=参数 注意第一项参数需要加入'&'
② 其他参数与 账号密码格式相同
③ cookie 加载流程首先需要得到cookie 用于与服务器交互激活服务器session
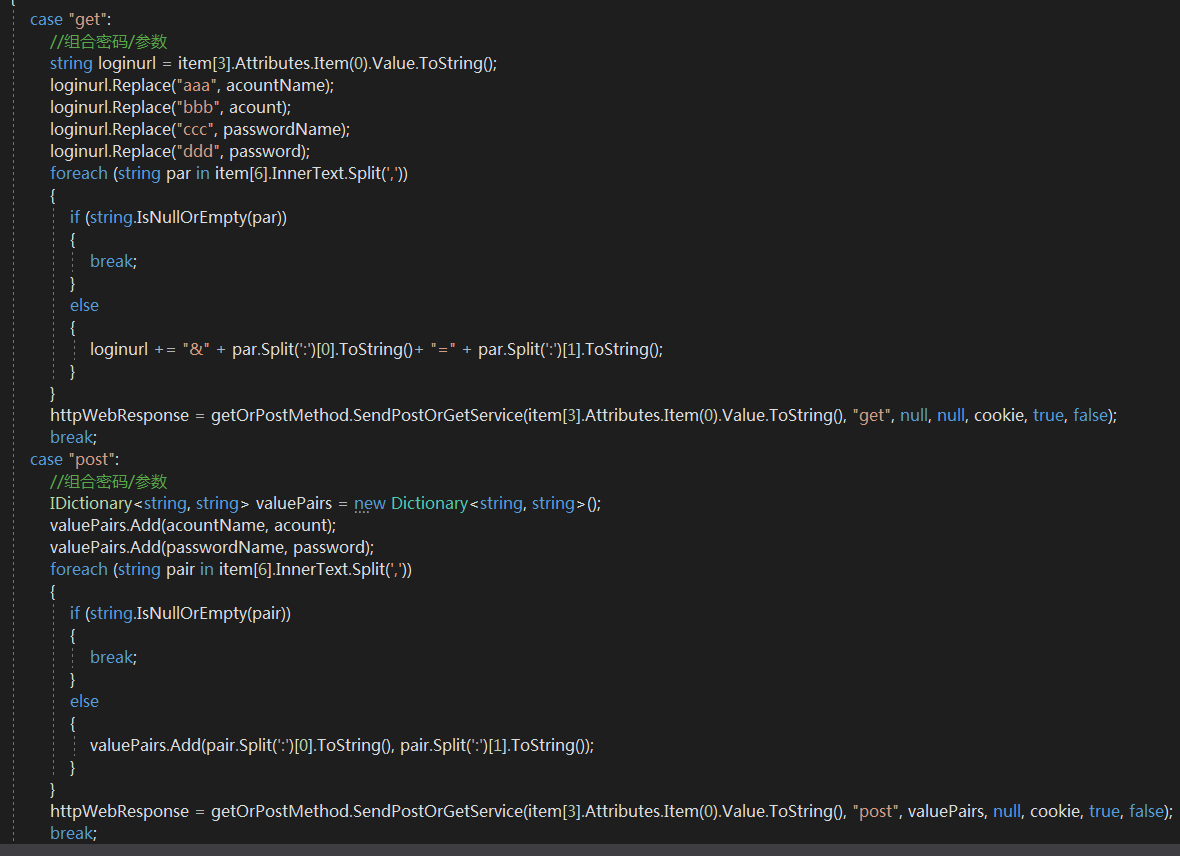
2.GET 请求参数
① 账号/密码/其他参数 在地址后面一顿拼接就好,必要情况下需要encode一下在进行拼接,注意encode时候特殊字符处理,时间/日期处理,尤其是get请求下载时要特别注意!!
② 模拟正常浏览器访问 主要是UA以及一些其他头部信息

如何跳过前端验证?
一般网站登录请求无非post/get ,他们最终提交方向都是服务器公开出来的接口或者地址,按照参数规则 提交该链接即可,所以说白了这种登录方式只不过是接口登录,接口操作网站而已.
拼接好参数请求时记得带上通行证,向服务器发送激活请求,一般情况下服务器会直接返回一些信息比如激活后的cookie,session 返回状态等等 或者是网页或者是一些简短的验证信息
图片验证如何实现?
当前程序并未实现,但是可以通过百度图片识别接口传递图片到识别接口随后返回验证码正确即可实现图片验证码识别,不过该方法只适用于简单图片识别复杂图片依旧需要求助Python来进行识别
滑块识别与短信识别以及字符识别未进行研究
##第二步## 登录
成功登陆后服务器session激活,这章通行证已经为真实有效可交互通行证了,确定服务器无返回错误后存储session
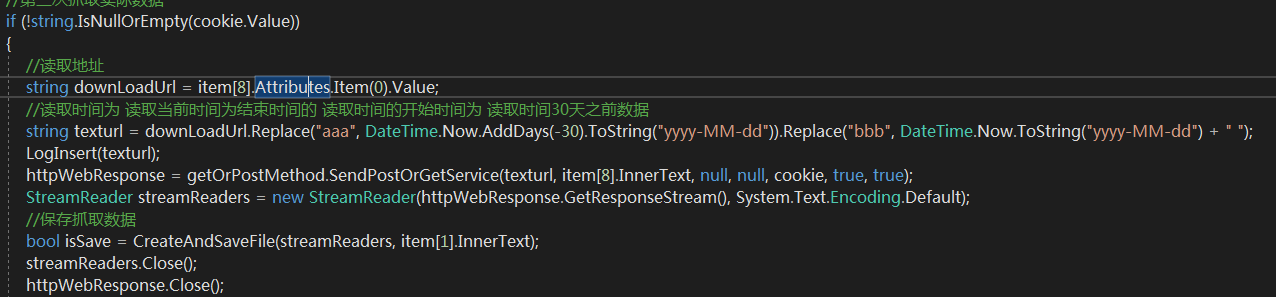
##第三步## 下载数据
找到需要下载目标解析下载地址以及传递参数,模仿类似登陆操作 传递参数/以及其他信息并加载通行证cookie或者session 回传服务器 换取数据
##第四步## 保存原下载数据
一般会用stream流来进行数据传输,不过要注意下编码格式以及数据格式 ,问题点多发生在服务器输出excel上,例如对面服务器使用java.poi输出excel切记直接操作流复制流数据到文件中即可
这种情况下流文件使用stream.readend 读出来是乱码 所以无法确认是否有效 只能复制到文件中 在做有效性判断,当然也有部分导出方式是可以查看到的只要编码正确就可以完整读取,这里判断有效性可以根据数据量多少
或者是字节数来判断
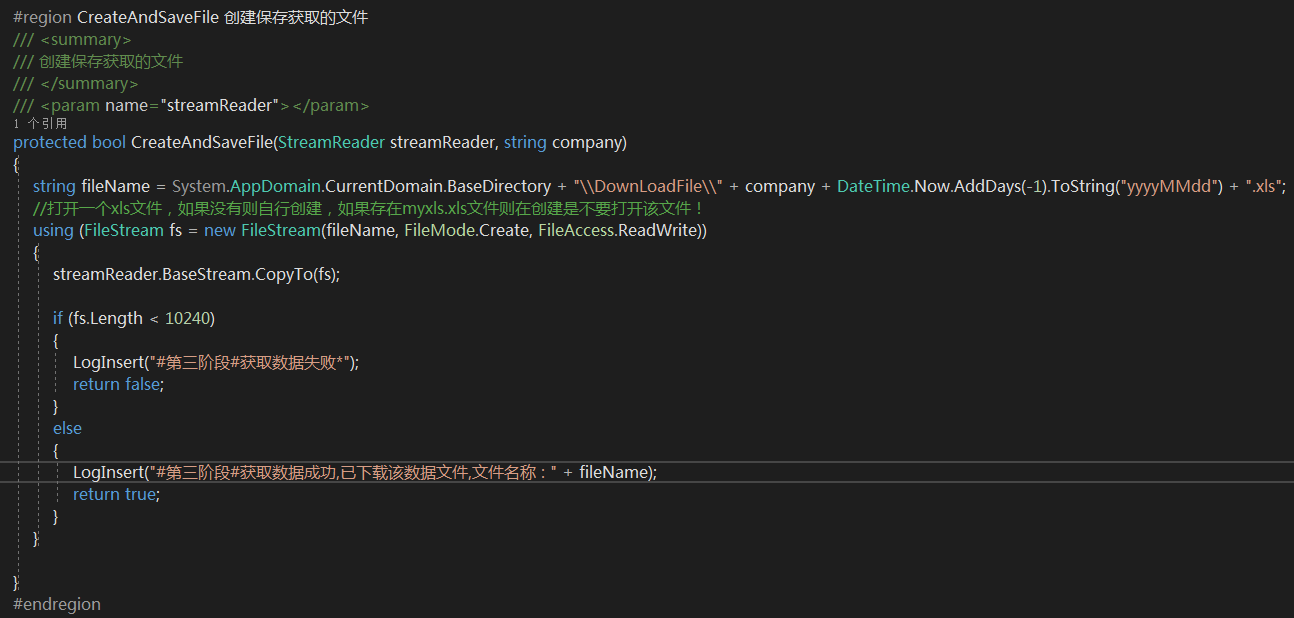
##第五步## 读取已导出原数据解析并入库
解析excel数据转换为database数据写入数据库,这里我写的不好使用的字符拼接,效率低速度慢有待改进,但在这之前想着重记录下excel读取中遇到的问题
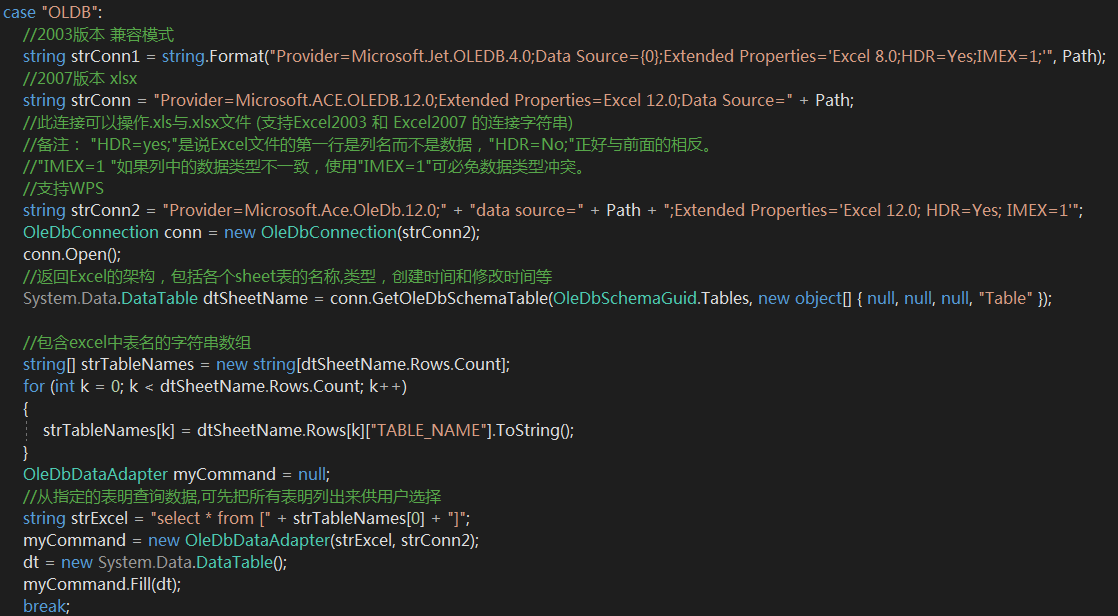
首先,读取工具 NPOI /OLDB
OLDB是比较常见的EXCEL读取方式,可以识别大多数的excel但他需要以下几点支持
① 微软的 office 服务支持,若无该服务 oldb无法运行
② 读取文件需要识别文件的版本 例如2003兼容版 2007标准版等等问题,参数多设置过程略显复杂

③ 最重要一点,错误提示不明确!! 不管是版本不兼容 还是解析不出来 他所报错误大都是 '不是有效文件' '内部指令错误' 这种模糊提示,他不会说明那里不对,反正就是不对不认识....F**K!
NPOI 比较简单 ,相对来说更适合源文件下载之后未打开过这种情况下读取
① 不依赖微软的office核心,有无核心均可运行 随时随地无限制读取
② 版本区分 没有多种的版本区分目前我知道的只有两种 'xls' 和 'xlsx' 分别对应 HSSFworkBook 和 XSSFWorkBook
③ 拆分之后需要重新读取数据到datatable中,当前程序需要检查excel内容 所以解析excel必不可少 正合我意

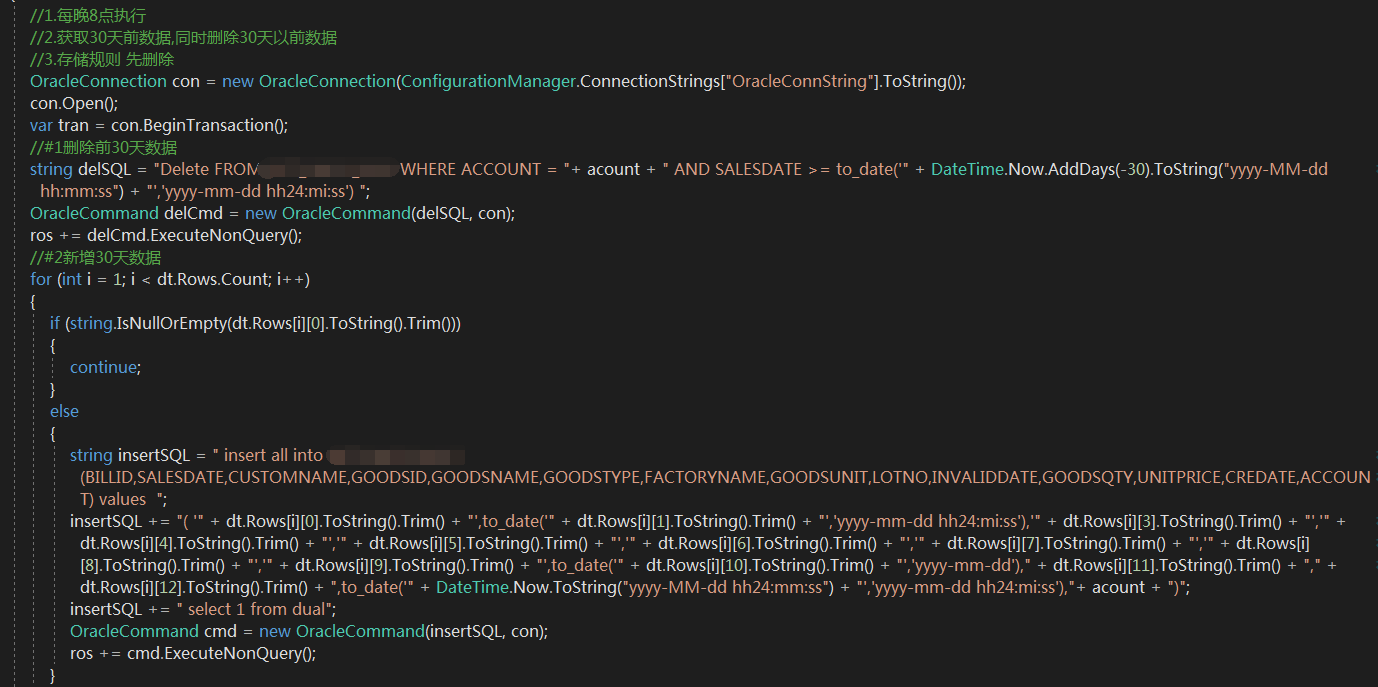
##第六步## 入库
数据读取完成后需要进入数据库,首先配置文件中添加数据库连接字符串账号密码地址等信息,直接读取后轮询解析数据直接入库,下面是oracle数据入库,注意特别不赞成使用一下方式存储数据!!! 效率低 速度慢!! 尽量使用正规批量插入方式
而且这里并没有体现出来多个网站同时抓取的方式,缺乏工具思想
程序设置为 每日自动执行,运行在win 2008 server 服务器上 添加了定时任务 每日进行自动更新
如有其它优化建议 以及疑问敬请留言~
.NET 爬虫总结的更多相关文章
- 设计爬虫Hawk背后的故事
本文写于圣诞节北京下午慵懒的午后.本文偏技术向,不过应该大部分人能看懂. 五年之痒 2016年,能记入个人年终总结的事情没几件,其中一个便是开源了Hawk.我花不少时间优化和推广它,得到的评价还算比较 ...
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- scrapy爬虫docker部署
spider_docker 接我上篇博客,为爬虫引用创建container,包括的模块:scrapy, mongo, celery, rabbitmq,连接https://github.com/Liu ...
- scrapy 知乎用户信息爬虫
zhihu_spider 此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧.代码地 ...
- 120项改进:开源超级爬虫Hawk 2.0 重磅发布!
沙漠君在历时半年,修改无数bug,更新一票新功能后,在今天隆重推出最新改进的超级爬虫Hawk 2.0! 啥?你不知道Hawk干吗用的? 这是采集数据的挖掘机,网络猎杀的重狙!半年多以前,沙漠君写了一篇 ...
- Python爬虫小白入门(四)PhatomJS+Selenium第一篇
一.前言 在上一篇博文中,我们的爬虫面临着一个问题,在爬取Unsplash网站的时候,由于网站是下拉刷新,并没有分页.所以不能够通过页码获取页面的url来分别发送网络请求.我也尝试了其他方式,比如下拉 ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- QQ空间动态爬虫
作者:虚静 链接:https://zhuanlan.zhihu.com/p/24656161 来源:知乎 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 先说明几件事: 题目的意 ...
- 让你从零开始学会写爬虫的5个教程(Python)
写爬虫总是非常吸引IT学习者,毕竟光听起来就很酷炫极客,我也知道很多人学完基础知识之后,第一个项目开发就是自己写一个爬虫玩玩. 其实懂了之后,写个爬虫脚本是很简单的,但是对于新手来说却并不是那么容易. ...
随机推荐
- 开源规则引擎 Drools 学习笔记 之 -- 1 cannot be cast to org.drools.compiler.kie.builder.impl.InternalKieModule
直接进入正题 我们在使用开源规则引擎 Drools 的时候, 启动的时候可能会抛出如下异常: Caused by: java.lang.ClassCastException: cn.com.cheng ...
- SQL Server中用户账号在数据库中的安全性,可以控制用户的权限
今天在公司SQL Server数据库中,查到一个SQL Server用户账号"DemoUser": "DemoUser"不在数据库服务器的sysadmin角色中 ...
- Java自学-接口与继承 super
Java的super关键字 步骤 1 : 准备一个显式提供无参构造方法的父类 准备显式提供无参构造方法的父类 在实例化Hero对象的时候,其构造方法会打印 "Hero的构造方法 " ...
- Matlab备忘录模式
备忘录模式(Memento)用于保存一个对象的某个状态,以便在适当的时候恢复对象.备忘录模式属于行为型模式,主要包括源发器,备忘录以及负责人.源发器:普通类,可以创建备忘录,也可以使用备忘录恢复状态. ...
- 常用模块 - logging模块
一.简介 logging模块定义的函数和类为应用程序和库的开发实现了一个灵活的事件日志系统.logging模块是Python的一个标准库模块,由标准库模块提供日志记录API的关键好处是所有Python ...
- OpenFire后台插件上传获取webshell及免密码登录linux服务器
1.目标获取 (1)fofa.so网站使用搜索body="Openfire, 版本: " && country=JP,可以获取日本存在的Openfire服务器.如图 ...
- mysql修改密码策略
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/Hello_World_QWP/arti ...
- C#8.0——异步流(AsyncStream)
异步流(AsyncStream) 原文地址:https://github.com/dotnet/roslyn/blob/master/docs/features/async-streams.md 注意 ...
- prometheus学习系列二: Prometheus安装
下载 在prometheus的官网的download页面,可以找到prometheus的下载二进制包. [root@node00 src]# cd /usr/src/ [root@node00 src ...
- find 和grep的区别
find(以文件属性为查找条件) grep(以文件内容为查找条件) grep works /usr/local/apache/htdocs/index.html 1.将/etc/passwd,有出现 ...