flink on yarn模式下两种提交job方式
yarn集群搭建,参见hadoop 完全分布式集群搭建
通过yarn进行资源管理,flink的任务直接提交到hadoop集群
1、hadoop集群启动,yarn需要运行起来。确保配置HADOOP_HOME环境变量。
2、flink on yarn的交互图解
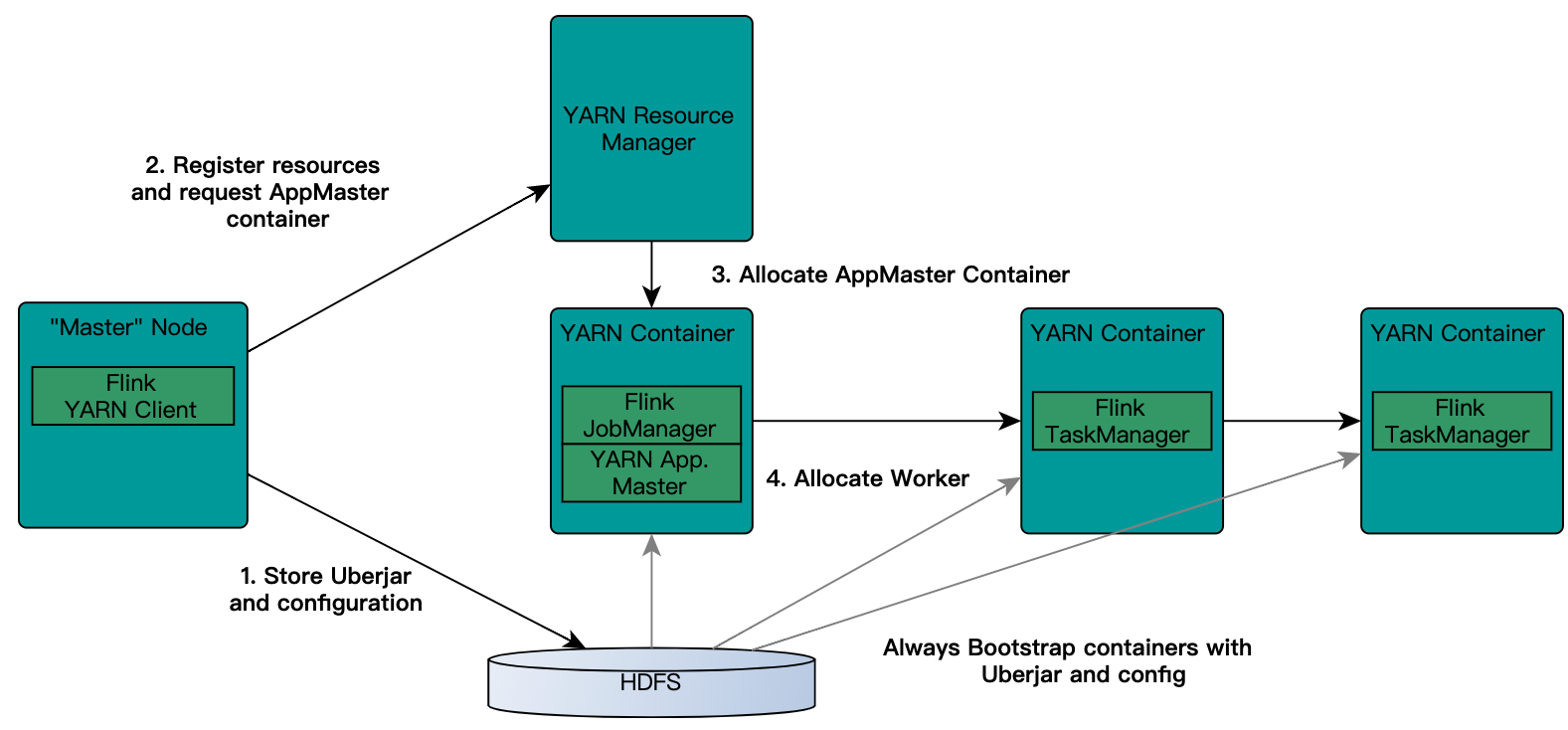
第一种yarn seesion(Start a long-running Flink cluster on YARN)这种方式需要先启动集群,然后在提交作业,接着会向yarn申请一块空间后,资源永远保持不变。
如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交.
这种方式资源被限制在session中,不能超过,比较适合特定的运行环境或者测试环境。 第二种Flink run直接在YARN上提交运行Flink作业(Run a Flink job on YARN),这种方式的好处是一个任务会对应一个job,即没提交一个作业会根据自身的情况,向yarn申请资源,直到作业执行完成,并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。
一般生产环境是采用此种方式运行。这种方式就需要确保集群资源足够。
注意:Jobmanager和AM运行于同一个container。一旦创建成功,AM就知道了Jobmanager的地址。它会生成一个新的flink配置文件,这个配置文件是给将要启动的taskManager用的,该配置文件也会上传到hdfs。
另外,AM的container也提供了Flink的web接口。Yarn代码申请的端口都是临时端口,目的是为了让用户并行启动多个Flink YARN Session。
4、Flink yarn session部署
配置flink目录下conf/flink-conf.yaml
jobmanager.rpc.address: vmhome10.com
配置slaves
加入taskmanager节点ip或主机名
PS:这个步骤对yarn-session没有效果,配置会被覆盖。
4.1 客户端模式
直接执行bin/yarn-session.sh启动,其缺省配置是:
masterMemoryMB=1024
taskManagerMemoryMB=1024
numberTaskManagers=1
slotsPerTaskManager=1
yarn-session的参数
bin/yarn-session.sh –help Usage:
Required
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Address of the JobManager (master) to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration.
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
-nl,--nodeLabel <arg> Specify YARN node label for the YARN application
-nm,--name <arg> Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-sae,--shutdownOnAttachedExit If the job is submitted in attached mode, perform a best-effort cluster shutdown when the CLI is terminated abruptly, e.g., in response to a user interrupt, such
as typing Ctrl + C.
-st,--streaming Start Flink in streaming mode
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
启动一个session:1个taskmanager,jobmanager内存1G,taskmanager内存1G
yarn-session.sh -n 1 -jm 1024 -tm 1024

flink的管理页面在session启动后,最后会显示,也可以通过yarn的管理页面里applicationMaster链接进去。
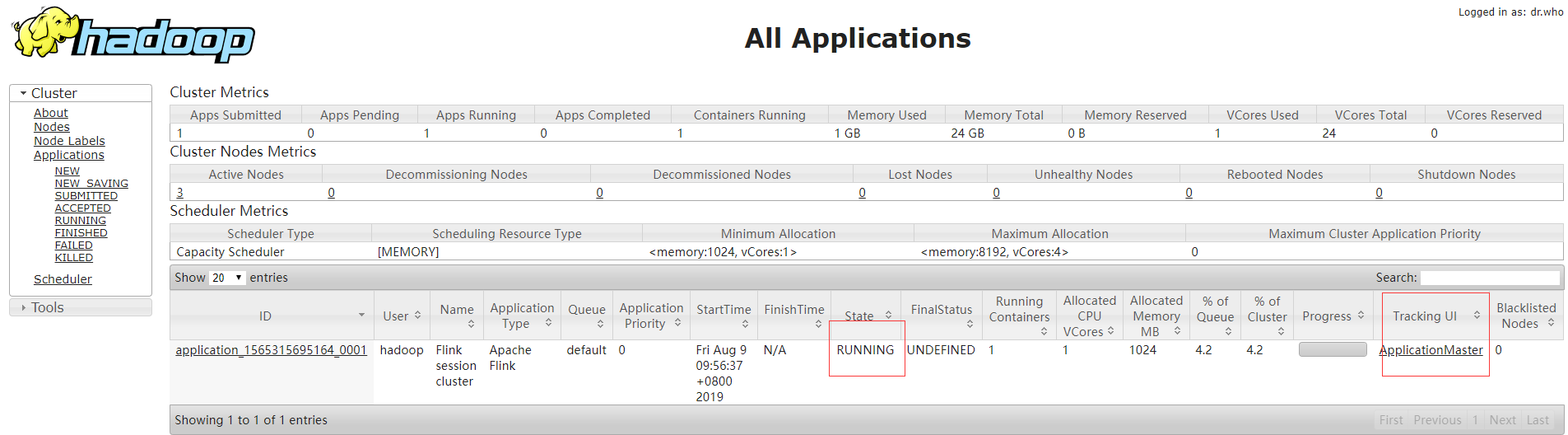
运行yarn-session的主机上会运行FlinkYarnSessionCli和YarnSessionClusterEntrypoint两个进程。
在yarn-session提交的主机上必然运行FlinkYarnSessionCli,这个进场代表本节点可以命令方式提交job,而且可以不用指定-m参数。
YarnSessionClusterEntrypoint进场代表yarn-session集群入口,实际就是jobmanager节点,也是yarn的ApplicationMaster节点。
这两个进程可能会出现在同一节点上。

系统默认使用con/flink-conf.yaml里的配置。
Flink on yarn将会覆盖掉几个参数:jobmanager.rpc.address因为jobmanager的在集群的运行位置并不是实现确定的,它就是am的地址;taskmanager.tmp.dirs使用yarn给定的临时目录;
parallelism.default也会被覆盖掉,如果在命令行里指定了slot数。
点击yarn页面里的ApplicationMaster可以直接链接到flink的管理页面
提交任务:
在提交yarn-session的这个主机上提交:
bin/flink run ~/flink-demo-wordcount.jar 注意:其他节点主机不能提交 可以在flink的web管理页面上提交
可以启动多个yarn session,一个yarn session模式对应一个JobManager,并按照需求提交作业,同一个Session中可以提交多个Flink作业。
PS:如果需要在其他主机节点提交JOB,需要在命令行中用-m参数指定yarn-session启动后,系统自动分配的ApplicationMaster主机和节点和端口
如下图中yarn-session启动成功后,会提示一个主机和端口后,这个就是JobManager(也是ApplicationMaster)

使用-m参数可以在任意集群主机提交JOB。
bin/flink run -m vmhome10.com:43258 examples/batch/WordCount.jar
停止作业:
yarn application -kill命令 [hadoop@vmhome11 ~]$ yarn application -kill application_1565315695164_0001
19/08/09 11:55:24 INFO client.RMProxy: Connecting to ResourceManager at vmhome11.com/192.168.44.11:8032
Killing application application_1565315695164_0001
19/08/09 11:55:24 INFO impl.YarnClientImpl: Killed application application_1565315695164_0001

对于客户端模式而言,可以启动多个yarn session,一个yarn session模式对应一个JobManager,并按照需求提交作业,同一个Session中可以提交多个Flink作业。
4.2、分离模式运行yarn-session
yarn-session的参数介绍
-n : 指定TaskManager的数量;
-d: 以分离模式运行;
-id:指定yarn的任务ID;
-j:Flink jar文件的路径;
-jm:JobManager容器的内存(默认值:MB);
-nl:为YARN应用程序指定YARN节点标签;
-nm:在YARN上为应用程序设置自定义名称;
-q:显示可用的YARN资源(内存,内核);
-qu:指定YARN队列;
-s:指定TaskManager中slot的数量;
-st:以流模式启动Flink;
-tm:每个TaskManager容器的内存(默认值:MB);
-z:命名空间,用于为高可用性模式创建Zookeeper子路径;
对于分离式模式,并不像客户端那样可以启动多个yarn session,如果启动多个,会出现下面的session一直处在等待状态。JobManager的个数只能是一个,同一个Session中可以提交多个Flink作业。
如果想要停止Flink Yarn Application,需要通过yarn application -kill命令来停止。通过-d指定分离模式,即客户端在启动Flink Yarn Session后,就不再属于Yarn Cluster的一部分。
启动分离模式
yarn-session.sh -n 2 -s 6 -jm 1024 -tm 1024 -nm test -d
5、Flink run 方式提交(推荐模式)
yarn session需要先启动一个集群,然后在提交作业。
对于Flink run直接提交作业就相对比较简单,不需要额外的去启动一个集群,直接提交作业,即可完成Flink作业。
命令: bin/flink run -m yarn-cluster examples/batch/WordCount.jar,注意使用参数-m yarn-cluster提交到yarn集群。
[hadoop@vmhome12 flink-1.8.0]$ bin/flink run -m yarn-cluster examples/batch/WordCount.jar
2019-08-09 15:05:05,200 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at vmhome11.com/192.168.44.11:8032
2019-08-09 15:05:05,359 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2019-08-09 15:05:05,359 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2019-08-09 15:05:05,552 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to
be set to properly load the Hadoop configuration for accessing YARN.
2019-08-09 15:05:05,573 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification:
ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=1}
2019-08-09 15:05:06,147 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/opt/flink-1.8.0/conf') contains both LOG4J and Logback configuration files.
Please delete or rename one of them.
2019-08-09 15:05:07,858 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1565315695164_0005
2019-08-09 15:05:07,875 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1565315695164_0005
2019-08-09 15:05:07,875 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
2019-08-09 15:05:07,877 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2019-08-09 15:05:12,915 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
Starting execution of program
在yarn的web监控页面上可以看到:
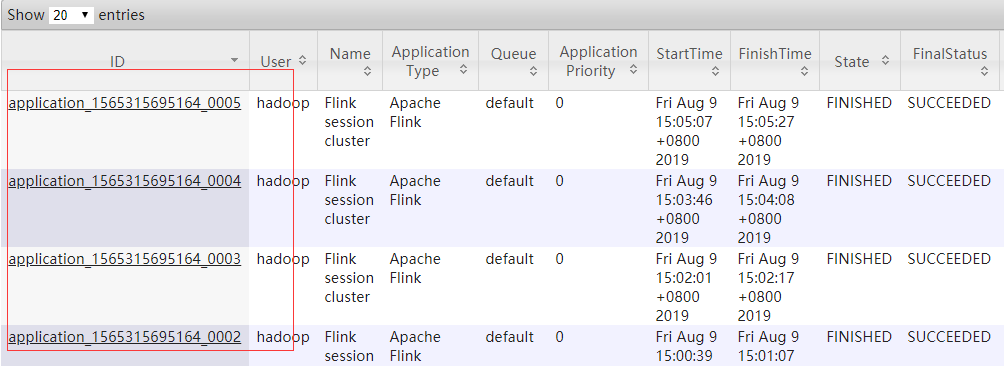
6、附加到某个yarn-session上(运行到指定的yarn session)
可以指定 -yid,--yarnapplicationId <arg> Attach to running YARN session来附加到到特定的yarn session上运行
先启动一个yarn-session
[hadoop@vmhome10 flink-1.8.0]$ bin/yarn-session.sh -nm vmhome10_test
2019-08-09 15:21:06,690 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, 192.168.44.10
2019-08-09 15:21:06,691 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 6123
2019-08-09 15:21:06,691 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m
2019-08-09 15:21:06,691 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.heap.size, 1024m
2019-08-09 15:21:06,691 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots, 1
2019-08-09 15:21:06,692 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 1
2019-08-09 15:21:07,252 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2019-08-09 15:21:07,416 INFO org.apache.flink.runtime.security.modules.HadoopModule - Hadoop user set to hadoop (auth:SIMPLE)
2019-08-09 15:21:07,502 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at vmhome11.com/192.168.44.11:8032
2019-08-09 15:21:07,756 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.
The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2019-08-09 15:21:07,780 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification:
ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=1}
2019-08-09 15:21:08,157 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/opt/flink-1.8.0/conf') contains both LOG4J and Logback configuration files.
Please delete or rename one of them.
2019-08-09 15:21:09,717 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1565315695164_0006
2019-08-09 15:21:09,738 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1565315695164_0006
2019-08-09 15:21:09,739 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
2019-08-09 15:21:09,746 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2019-08-09 15:21:14,603 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
2019-08-09 15:21:15,004 INFO org.apache.flink.runtime.rest.RestClient - Rest client endpoint started.
Flink JobManager is now running on vmhome11.com:37392 with leader id 00000000-0000-0000-0000-000000000000.
JobManager Web Interface: http://vmhome11.com:37392

附加到0006这个application id上运行job
[hadoop@vmhome12 flink-1.8.0]$ bin/flink run -yid
7、关于启动yarn-session或者flink run -m yarn-cluster报错
如果报错信息有如下内容,并且其他报错信息中还包含内存或者虚拟内存不足的情况:
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143 这个报错是因为yarn强制检查虚拟内存是否符合配置导致的,当我们的服务器或者虚拟机的内存达不到配置要求,可能就会报这个错误
在测试环境可以关闭虚拟内存的强制检查。在生产环境我们需要分析配置文件以及服务器真实虚拟内存具体情况。
解决办法:
在etc/hadoop/yarn-site.xml文件中,修改检查虚拟内存的属性为false,如下: <property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
YarnSessionClusterEntrypoint
flink on yarn模式下两种提交job方式的更多相关文章
- 【Spark篇】---Spark中yarn模式两种提交任务方式
一.前述 Spark可以和Yarn整合,将Application提交到Yarn上运行,和StandAlone提交模式一样,Yarn也有两种提交任务的方式. 二.具体 1.yarn-clien ...
- android环境下两种md5加密方式
在平时开发过程中,MD5加密是一个比较常用的算法,最常见的使用场景就是在帐号注册时,用户输入的密码经md5加密后,传输至服务器保存起来.虽然md5加密经常用,但是md5的加密原理我还真说不上来,对md ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
- 【Spark篇】--Spark中Standalone的两种提交模式
一.前述 Spark中Standalone有两种提交模式,一个是Standalone-client模式,一个是Standalone-master模式. 二.具体 1.Standalon ...
- spark 在yarn模式下提交作业
1.spark在yarn模式下提交作业需要启动hdfs集群和yarn,具体操作参照:hadoop 完全分布式集群搭建 2.spark需要配置yarn和hadoop的参数目录 将spark/conf/目 ...
- 小记--------spark的两种提交模式
spark的两种提交模式:yarn-cluster . yarn-client 图解
- spark on yarn模式下内存资源管理(笔记1)
问题:1. spark中yarn集群资源管理器,container资源容器与集群各节点node,spark应用(application),spark作业(job),阶段(stage),任务(task) ...
- 探究Repository模式的两种写法与疑惑
现如今DDD越来越流行,园子里漫天都是介绍关于它的文章.说到DDD就不能不提Repository模式了,有的地方也叫它仓储模式. 很多时候我们对Repository都还停留在Copy然后使用的阶段, ...
- bridged(桥接模式)、NAT(网络地址转换模式)和host-only(主机模式)-VMware下三种网络配置方式
VMWare提供了三种工作模式,它们是bridged(桥接模式).NAT(网络地址转换模式)和host-only(主机模式).要想在网络管理和维护中合理应用它们,你就应该先了解一下这三种工作模式. 1 ...
随机推荐
- SpringBoot+MyBatisPlus整合时提示:Invalid bound statement(not found):**.dao.UserDao.queryById
场景 在使用SpringBoot+MyBatisPlus搭建后台启动项目时,使用EasyCode自动生成代码. 在访问后台接口时提示: Invilid bound statement (not fou ...
- JQuery Ztree 树插件配置与应用小结
JQuery Ztree 树插件配置与应用小结 by:授客 QQ:1033553122 测试环境 Win7 jquery-3.2.1.min.js 下载地址: https://gitee.com/is ...
- 利用Azure虚拟机安装Dynamics 365 Customer Engagement之七:安装前端服务器及部署管理器
我是微软Dynamics 365 & Power Platform方面的工程师罗勇,也是2015年7月到2018年6月连续三年Dynamics CRM/Business Solutions方面 ...
- kali安装vmtool后依旧无法拖拽文件,复制粘贴,解决办法
本文链接:https://blog.csdn.net/Key_book/article/details/80310235命令行下 执行 apt-get install open-vm-tools-de ...
- Springboot 整合 MyBatis(一):跑起来
0x1 环境 1. 系统:Windows 10 2. IDE:IntelliJ IDEA 2018.3 x64 0x2 创建项目 1.创建一个SpringBoot项目 选择Spring Initail ...
- 【入门级】Docker基础介绍(一)
Docker发展 Docker目前有两个版本: 1.Docker EE:企业版 2.Docker CE:社区版 Open Container Initiative倡议,包含两个规范, 1.运行时规范: ...
- linux 命令之touch
转自:http://www.maomao365.com/?p=2037 一.touch命令简介touch的命令功能说明: 1 可以通过touch新建一个文件; 2 可以修改文件的时间戳; 3 可以批量 ...
- Docker 运行一个Web应用
使用 docker 构建一个 web 应用程序. 我们将在docker容器中运行一个 Python Flask 应用来运行一个web应用 参数说明: -d:让容器在后台运行. -P:将容器内部使用的网 ...
- 前端JSON请求转换Date问题
目的:记录使用SpringMVC中前端JSON数据中的日期转换成Date数据类型时区产生的问题 记录下遇到过的问题 在使用SpringMVC框架中,使用@RequestBody注解将前端的json数据 ...
- Day2 - Python基础2 列表、字符串、字典、集合、文件、字符编码
本节内容 列表.元组操作 数字操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 1. 列表.元组操作 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 ...