关于大数据T+1执行流程
关于大数据T+1执行流程
前提: 搭建好大数据环境(hadoop hive hbase sqoop zookeeper oozie hue)
1.将所有数据库的数据汇总到hive (这里有三种数据源 ORACLE MYSQL SEQSERVER)
全量数据抽取示例:
ORACLE(注意表名必须大写!!!)
sqoop import --connect jdbc:oracle:thin:@//10.11.22.33:1521/LPDR.china.com.hh --username root --password 1234 \
--table DATABASENAME.TABLENAME --hive-overwrite --hive-import --hive-database bgda_hw --hive-table lp_tablename \
--target-dir /user/hadouser_hw/tmp/lp_tablename --delete-target-dir \
--null-non-string '\\N' --null-string '\\N' \
--hive-drop-import-delims --verbose --m 1
MYSQL:
sqoop import --connect jdbc:mysql://10.33.44.55:3306/DATABASEBANE --username ROOT --password 1234 \
--query 'select * from DEMO t where t.DATE1 < current_date and $CONDITIONS' \
--hive-overwrite --hive-import --hive-database bgda_hw --hive-table DEMO \
--target-dir /user/hadouser_hw/tmp/DEMO --delete-target-dir \
--null-non-string '\\N' --null-string '\\N' \
--hive-drop-import-delims --verbose --m 1
SQLSERVER:
sqoop import --connect 'jdbc:sqlserver://10.55.66.15:1433;username=ROOT;password=ROOT;database=db_DD' \
--query 'select * from TABLE t where t.tasktime < convert(varchar(10),getdate(),120) and $CONDITIONS' \
--hive-overwrite --hive-import --hive-database bgda_hw --hive-table TABLENAME \
--target-dir /user/hadouser_hw/tmp/TABLENAME --delete-target-dir \
--null-non-string '\\N' --null-string '\\N' \
--hive-drop-import-delims --verbose --m 1
2. 编写hive脚本,对数据进行处理
说明:
data 存储T+1跑出来的数据信息,只存一天的数据量
data_bak : 存储所有的数据信息
(初始化脚本)
use bgda_hw;
set hive.auto.convert.join=false; drop table data_bak;
create table data_bak(
scanopt string
,scanoptname string
,statisdate string
) row format delimited fields terminated by '\001'; insert overwrite table data_bak
SELECT
a.scanopt
,x0.name as scanoptname
,to_date(a.scandate) as statisdate
from bgda_hw.scan a
left outer join bgda_hw.user x0 on x0.userid = a.scanopt
where 1=1
and datediff(a.scandate,'2019-01-01' )>=0
and datediff(a.scandate,'2019-09-20' )<0
GROUP BY a.scanopt,x0.name,a.scandate
order by a.scandate
;
(t+1脚本)
use bgda_hw;
set hive.auto.convert.join=false; drop table data;
create table data(
scanopt string
,scanoptname string
,statisdate string
) row format delimited fields terminated by '\001'; insert overwrite table data
SELECT
a.scanopt
,x0.name as scanoptname
,to_date(a.scandate) as statisdate
from bgda_hw.scan a
left outer join bgda_hw.user x0 on x0.userid = a.scanopt
where 1=1
and a.scandate<date_add(from_unixtime(unix_timestamp(),'yyyy-MM-dd'),0)
and a.scandate>=date_add(from_unixtime(unix_timestamp(),'yyyy-MM-dd'),-1)
GROUP BY a.scanopt,x0.name,a.scandate
order by a.scandate
; insert into table data_bak
select * from data
;
3.将结果数据抽取到结果库里
sqoop export \
--connect jdbc:mysql://10.6.11.11:3306/report \
--username root \
--password 1234 \
--table data \
--export-dir /user/hive/warehouse/bgda_hw.db/data \
--columns scanopt,scanoptname,statisdate \
--fields-terminated-by '\001' \
--lines-terminated-by '\n' \
--input-null-string '\\N' \
--input-null-non-string '\\N'
抽數腳本示例 (腳本中的insert.hql 則是上方定義的hive腳本信息)
#!/bin/bash export CDH_PARCEL=/var/opt/cloudera/parcels/CDH/bin/
export PATH=${PATH}:${CDH_PARCEL}
export PYTHON_EGG_CACHE=~/.python-eggs #kinit to user hadouser_hw
kinit -kt hadouser_hw.keytab hadouser@HADOOP-AD-ROOT.DC echo "$CDH_PARCEL: {CDH_PARCEL} "
echo "$PATH: {PATH} "
echo "$PYTHON_EGG_CACHE: {PYTHON_EGG_CACHE} " #sqoop import full data from mssql database to hdfs
set -x beeline -u "jdbc:hive2://10.20.33.44:10000/default;principal=hive/sssssss012@HADOOP-AD-ROOT.DC" -f insert.hql # 将数据抽取到mysql 结果数据 原数据
sqoop export \
--connect jdbc:mysql://10.6.11.15:3306/report \
--username root \
--password 1234 \
--table rs_kpitime_psdata \
--export-dir /user/hive/warehouse/bgda_hw_stg.db/rs_kpitime_psdata_bak \
--columns aplcustno,isapprv,statisdate,statisyear,statisquarter,statismonth,countdate \
--fields-terminated-by '\001' \
--lines-terminated-by '\n' \
--input-null-string '\\N' \
--input-null-non-string '\\N' ret=$?
set +x if [[ $ret -eq 0 ]];then
echo "insert table OK"
else
echo "insert table failed!!!Please check!!!"
exit $ret
fi
4.定义调度信息(oozie),每天定时跑出结果数据,自动抽取到结果库中
HUE的基本使用
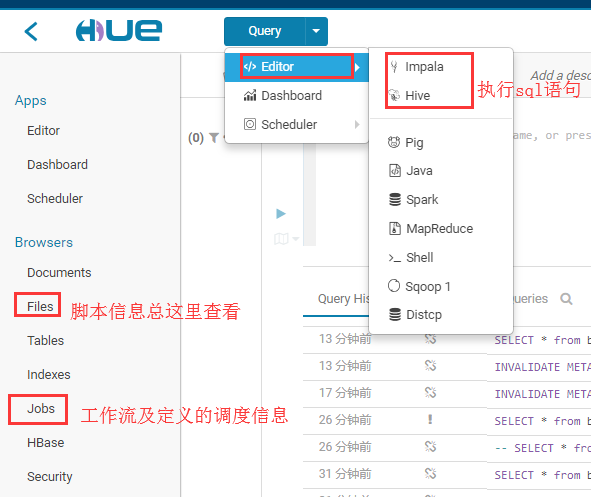
定义工作流信息
先进入workflow
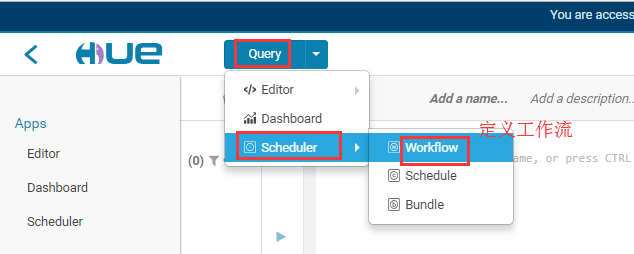
开始定义

选定要执行的脚本 (图片中提到的keytab 是一个认证文件)

定义定时任务
先进入定时任务页面
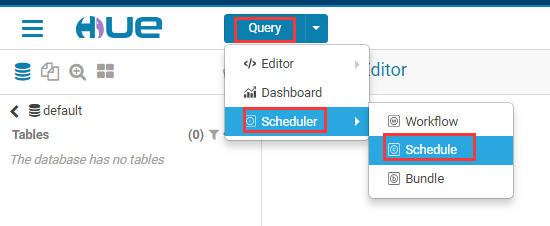
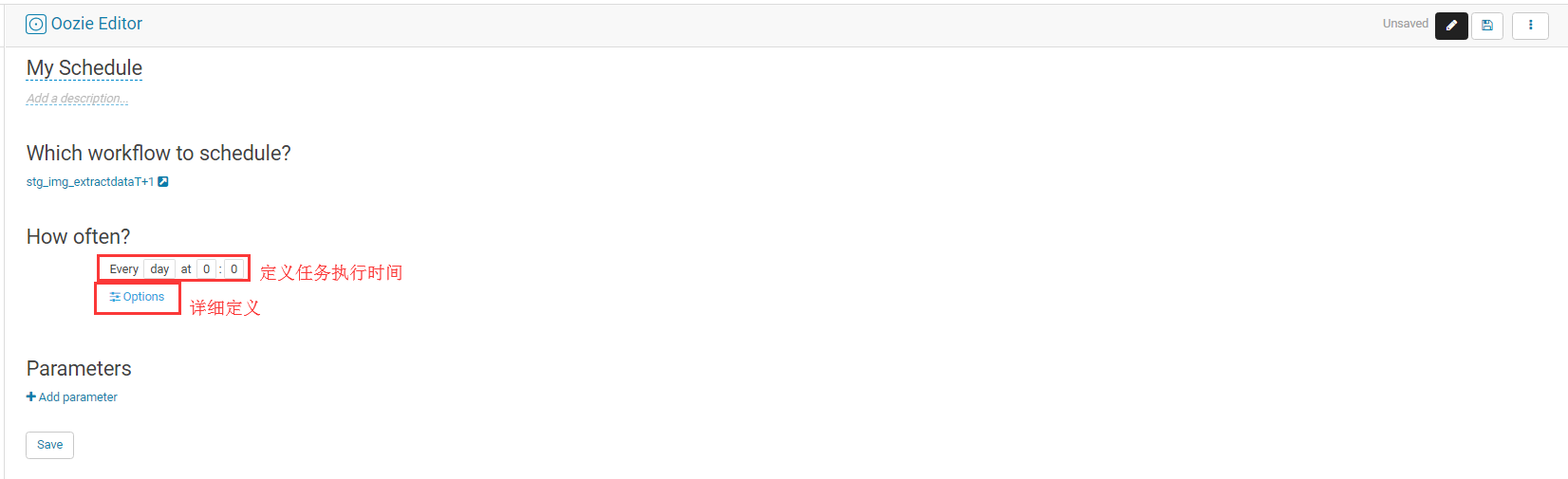
新建定时任务
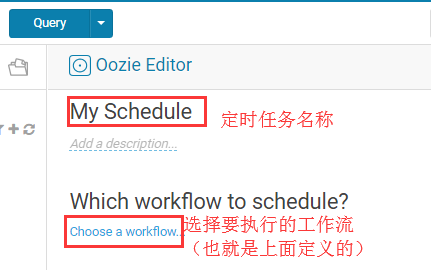
定时任务详细定义(点击Options ,选择ShangHai时区,然后定义任务执行时长(例如 从2019年到2099年,最后保存,保存好后记得点击执行!!!))
5.配置可视化组件展示数据 saiku
这部分详细教程请参考 https://www.cnblogs.com/DFX339/tag/saiku/
关于大数据T+1执行流程的更多相关文章
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 一个简单的使用Quartz和Oozie调度作业给大数据计算平台执行
一,介绍 Oozie是一个基于Hadoop的工作流调度器,它可以通过Oozie Client 以编程的形式提交不同类型的作业,如MapReduce作业和Spark作业给底层的计算平台(如 Cloude ...
- 迎战大数据-Oracle篇
来自:http://www.cnblogs.com/wenllsz/archive/2012/11/16/2774205.html 了解大数据带来的机遇: 透视架构与工具: 开源节流,获得竞争优势. ...
- BigData:值得了解的十大数据发展趋势
当今,世界无时无刻不在发生着变化.对于技术领域而言,普遍存在的一个巨大变化就是为大数据(Big data)打开了大门,并应用大数据技相关技术来改善各行业的业务并促进经济的发展.目前,大数据的作用已经上 ...
- AI时代,还不了解大数据?
如果要问最近几年,IT行业哪个技术方向最火?一定属于ABC,即AI + Big Data + Cloud,也就是人工智能.大数据和云计算. 这几年,随着互联网大潮走向低谷,同时传统企业纷纷进行数字化转 ...
- 大数据 --> 大数据关键技术
大数据关键技术 大数据环境下数据来源非常丰富且数据类型多样,存储和分析挖掘的数据量庞大,对数据展现的要求较高,并且很看重数据处理的高效性和可用性. 传统数据处理方法的不足 传统的数据采集来源单一,且存 ...
- 什么是SQL Server2019大数据群集?
从SQL Server 2019(15.x)开始,SQL Server大数据群集允许您部署在Kubernetes上运行的SQL Server,Spark和HDFS容器的可伸缩群集.这些组件并排运行,使 ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
随机推荐
- web漏洞-命令执行、文件上传、XSS
一.命令执行 1:什么是命令执行? 命令执行漏洞是指攻击者可以随意执行系统命令.属于高危漏洞之一任何脚本语言都可以调用操作系统命令. 应用有时需要调用一些执行系统命令的函数,举个例子如:PHP中的 ...
- 5G 调制与解调
调制,就是将原始信号转换为适合在信道中传输的形式的一种过程,在无线通信中,调制一般均指载波调制,而解调则是调制的逆过程,即将原始信号从已调信号中恢复出来. 进行载波调制,主要为实现以下目标: 1)在无 ...
- angular实现draggable拖拽
前言:最近项目要实现一个拖拽功能,我在网上开始了各类搜寻,虽然后面因为数据原因舍弃了拖拽的这一需求,但是为了不辜负最近的研究,还是来记录一下. 场景需求:面试预约选时间节点,候选人之间是可以相互交换的 ...
- eclipse 代码问题总结
隐藏控件,在xml文件中写属性 android:visibility="gone"
- java设计模式(二)单例模式,一生只爱一人,只争一朝一夕
单例模式:保证一个类在内存中的对象唯一,有且仅能实例化一次.(如多个代码块需要读取配置文件,or开启事务,orjdbc读取数据源就是个经典例子)参考:吟啸且徐行 实现步骤: 私有构造方法.保证唯一的 ...
- MVC模式与Servlet执行流程
##Servlet生命周期 五个部分,从加载到卸载,如同人类的出生到死亡 加载:Servlet容器自动处理 初始化:init方法 该方法会在Servlet被加载并实例化后执行 服务:service抽象 ...
- 在.NET Core控制台中使用依赖注入
本文介绍如何在控制台应用程序中使用微软提供的依赖注入功能,掌握控制台中的用法后,可以扩展到构建windows服务中. 创建控制台应用程序 添加DependencyInjection的引用 Instal ...
- js问题记录(一) -- 关于for in, sort(), 及prototype
1.关于for in for in : 遍历对象中的可枚举的属性 例子1:for in 遍历对象的键为String类型,所以调用时用Object[key]形式,而不用Object.key形式 < ...
- webpack 插件 ProvidePlugin 的使用方法和 eslint 配置
ProvidePlugin:自动加载模块,而不必到处 import 或 require .(点击查看官方文档) 使用方法: 配置 webpack.config.js文件里 plugins 属性 new ...
- EtreCheck是否修复恶意软件和广告软件?为什么EtreCheck无法制作截图?
EtreCheck for Mac是一款Mac上的软件,有很对人对这款软件并不熟系,今天小编就来给大家介绍一下这款软件最常出现的问题—EtreCheck是否修复恶意软件和广告软件?为什么EtreChe ...