Python爬虫大作业
一、题目:
获取并保存目标网站的下图所示的所有英文名,网页转换通过点击more names刷新名字并将各个英文名子目录下,去获取并保存每一个英文名的名字、性别、寓意、简介如下图所示内容红色标记框内的内容:

二、爬取步骤:
1.数据服务
爬取步骤:
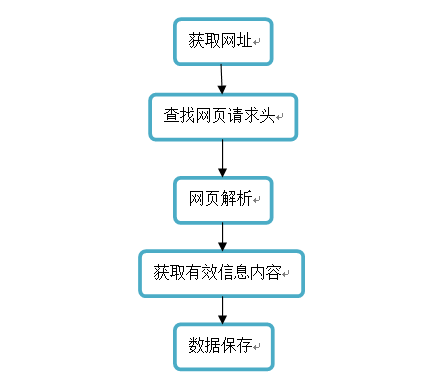
(1)爬取整个动态网页信息内容;
(2)解析网页内容,利用正则表达式获取有效信息;
(3)把爬取下来的信息采用csv进行存储;
(4)进行必要的手动的数据清理和美化。
2.解析服务
解析步骤:
(1)利用headers直接访问网页内容;
(2)爬取页面信息;
(3)解析页面;
(4)形成text数据。
(5)实时获得网站的英文名、性别、寓意、简介等内容。
流程图:
三、源代码:
按步骤要求一步一步将数据爬取并保存。
import requests#请求库
import re#表达式解析库
import csv
def html_save(s):#爬取内容保存函数
with open('save3.csv','a', newline='')as f:#以追加的方式存数据newline控制文本模式之下,一行的结束字符
writer = csv.writer(f)#将数据写入csv文件
writer.writerow(s) def get_url(n):#保存网址
urls=[]
for i in range(1,101):#测试得出网址范围
urls.append('http://www.nymbler.com/nymbler/more/%s'%i)
return urls
pass def get_detail(url):#对网页内容进行解析获取
headers = {'Cookie':"heroku-session-affinity=AECDaANoA24IAaj0sYj+//8HYgAH2hNiAAsB42EDbAAAAANtAAAABXdlYi4zbQAAAAV3ZWIuMm0AAAAFd2ViLjFqTiF9lGfQyz4HBcluZEIivsLibgo_; PLAY_SESSION=e625836109d6e09af14be41657c35e808ca31e72-session_id=240bcff7-ebb5-49ee-8fa4-ffcc5ba32e48; _ga=GA1.2.408125030.1575511582; _gid=GA1.2.1377013858.1575511582; td_cookie=18446744071831041204; _gat_gtag_UA_1763772_1=1"}#反爬虫请求头
response = requests.post(url)#解析网页
docx=(response.text)#得到解析文本
name=re.findall(r'"name":"([^"]+)"',docx)#正则匹配name的value
gender=re.findall(r'"gender":"([^"]+)"',docx) #正则匹配gender的value
info=re.findall(r'"info":"([^"]+)"',docx)
meaning=re.findall(r'"meaning":"([^"]+)"',docx)
for i in range(len(meaning)):#将获取的信息进行有序处理
tmp=[]
tmp.append(name[i])
tmp.append(gender[i])
tmp.append(meaning[i])
tmp.append(info[i])
html_save(tmp)#对信息进行保存
return tmp
pass def get_all(n):#获取所有网页的信息
alldata=[]
for url in get_url(n):
alldata.extend(get_detail(url))#将get_url(n)内的所有网页一一进行解析保存
return alldata
pass get_all(100)#函数调用
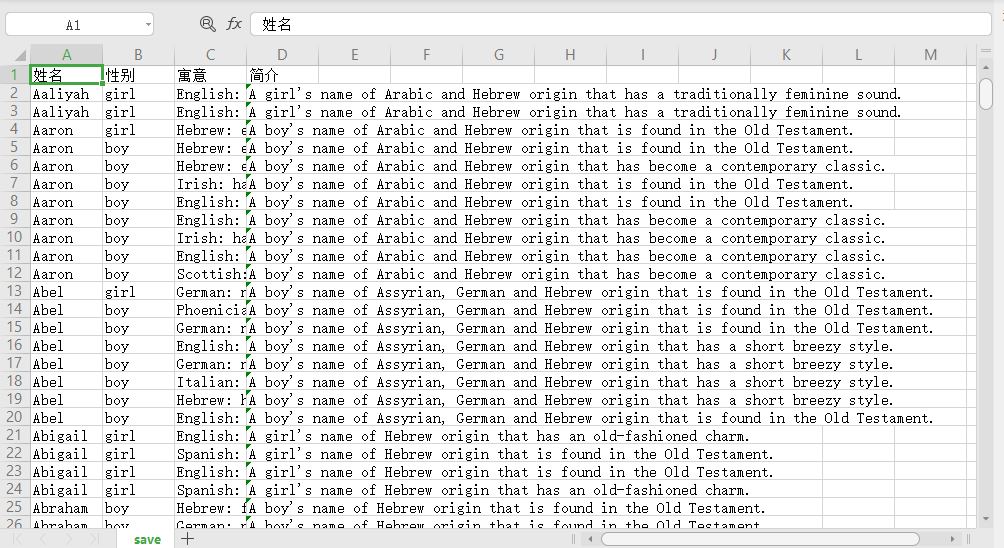
四、运行结果:
部分结果展示:
Python爬虫大作业的更多相关文章
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- python ATM大作业之alex思路
一 ATM alex想了一个思路,就是定义一个函数,这个函数可以实现所有的atm的功能:取款,转账,消费等等. 为了实现这个想法,alex构建了一个两级字典,厉害了.我发现,厉害的人都喜欢用字典.这里 ...
- python之大作业
一.题目要求 获得网页中A-Z所有名字并且爬取名字详情页中的信息,如姓名,性别,,说明等,并存放到csv中(网址:http://www.thinkbabynames.com/start/0/A) 现在 ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 【大数据应用技术】作业十二|Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 前言 本次作业是在<爬虫大作业>的基础上进行的 ...
- 作业——12 hadoop大作业
作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 1.以下是爬虫大作业产生的csv文件 ...
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
随机推荐
- ABAP分享四 选择屏幕下拉菜单简单实现示例
PARAMETERS p_carri2 LIKE spfli-carrid AS LISTBOX VISIBLE LENGTH 20 ...
- C lang: The caracter reverse
Ax_Code #include<stdio.h> int main(void) { int i; char string[7] = {"mrsoft"}; char ...
- 发送RCS成功的消息log_1
//12-02 16:39:00.869323 24174 27394 I CarrierServices: [1172] cpb.x: Send INVITE//12-02 16:39:00.920 ...
- cobbler无人值守
一.背景介绍 作为运维,在公司经常遇到一些机械性重复工作要做,例如:为新机器装系统,一台两台机器装系统,可以用光盘.U盘等介质安装,1小时也完成了,但是如果有成百台的服务器还要用光盘.U盘去安装, ...
- 阻止保存要求重新创建表的更改-只需设置SQLServer的一个设置
- 连接查询 变量、if else、while
连接查询 变量.if else.while 一.连接查询:通过连接运算符可以实现多个表查询. 连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志. 常用的两个链接运算符: ...
- Linux系统学习 十、DHCP服务器—介绍和原理
介绍: DHCP服务作用(动态主机配置协议) 为大量客户机自动分配地址.提供几种管理 减轻管理和维护成本.提高网络配置效率 可分配的地址信息主要包括: 网卡的IP地址.子网掩码 对应的网路地址.广播地 ...
- VS 2017 中取消自动补全花括号
输入 "{", VS 会很智能的给你补全,得到 “{}”, 如果不想享受这个服务,可以按以下设置取消: Tools -> Options -> Text Editor ...
- R-5 相关分析-卡方分析
本节内容: 1:相关分析 2:卡方分析 一.相关分析 相关系数: 皮尔逊相关系数:一般用来计算两个连续型变量的相关系数. 肯德尔相关系数:一个连续一个分类(最好是定序变量) 斯皮尔曼相关系数:2个变量 ...
- 第04组 Beta冲刺(2/4)
队名:斗地组 组长博客:地址 作业博客:Beta冲刺(2/4) 各组员情况 林涛(组长) 过去两天完成了哪些任务: 1.分配展示任务 2.收集各个组员的进度 3.写博客 展示GitHub当日代码/文档 ...