Spark-1.0.1 的make-distribution.sh编译、SBT编译、Maven编译 三种编译方法
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3775343.html
本文编译方法所支持的hadoop环境是Hadoop-2.2.0,YARN是2.2.0,JAVA版本为1.8.0_11,操作系统Ubuntu14.04
cd spark-1.0.1
./make-distribution.sh --hadoop 2.2.0 --with-yarn --tgz
--tgz: Additionally creates spark-$VERSION-bin.tar.gz
--hadoop VERSION: Builds against specified version of Hadoop.
--with-yarn: Enables support for Hadoop YARN.
--with-hive: Enable support for reading Hive tables.
--name: A moniker for the release target. Defaults to the Hadoop verison.
如果一切顺利,会在$SPARK_HOME/assembly/target/scala-2.10目录下生成目标文件
(好像Java版本1.8在这里有版本问题?默认在1.6环境下,但我居然编译成功了,呵呵)
(注:之前加了--with-tachyon 我总是编译成功,但生成tgz部署包失败,不知道为什么。今天我在JDK1.7.0_51环境(应该与JDK版本无关)下,去掉了--with-tachyon ,编译成功,并且生成了spark-1.0.1-
bin-2.2.0.tgz部署包)
编译结果:
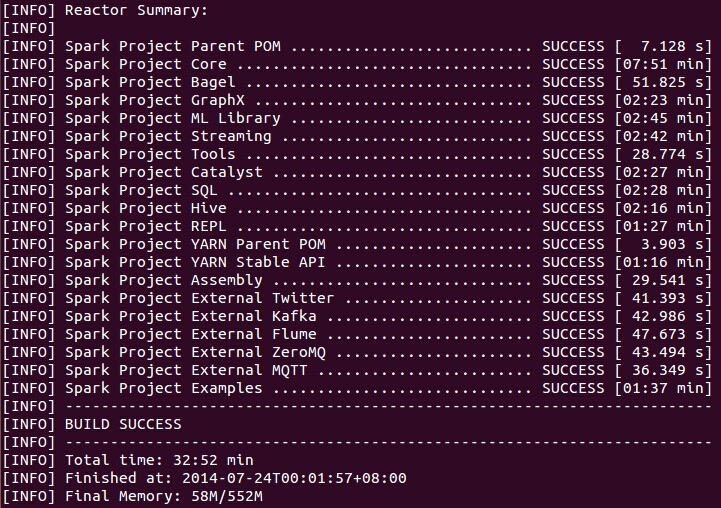
tar -zxvf spark-1.0.0.tar.gz
cd spark-1.0.1
SPARK_HADOOP_VERSION=2.2.0 SPARK_YARN=true ./sbt/sbt assembly
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
[INFO] Compiling Scala sources and Java sources to /Users/me/Development/spark/core/target/scala-2.10/classes...
[ERROR] PermGen space -> [Help ] [INFO] Compiling Scala sources and Java sources to /Users/me/Development/spark/core/target/scala-2.10/classes...
[ERROR] Java heap space -> [Help ]
2)指定Hadoop版本并编译
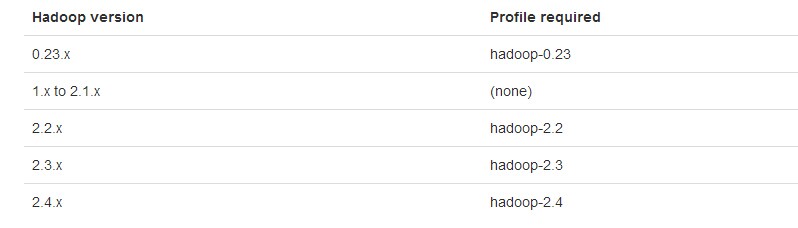
# Apache Hadoop 2.2.X
mvn -Pyarn -Phadoop-2.2 -Dhadoop.version=2.2.0 -DskipTests clean package
如果是其他版本的YARN和HDFS,则按下面编译:
# Different versions of HDFS and YARN.
mvn -Pyarn-alpha -Phadoop-2.3 -Dhadoop.version=2.3. -Dyarn.version=0.23. -DskipTests clean package
)
编译结果为:
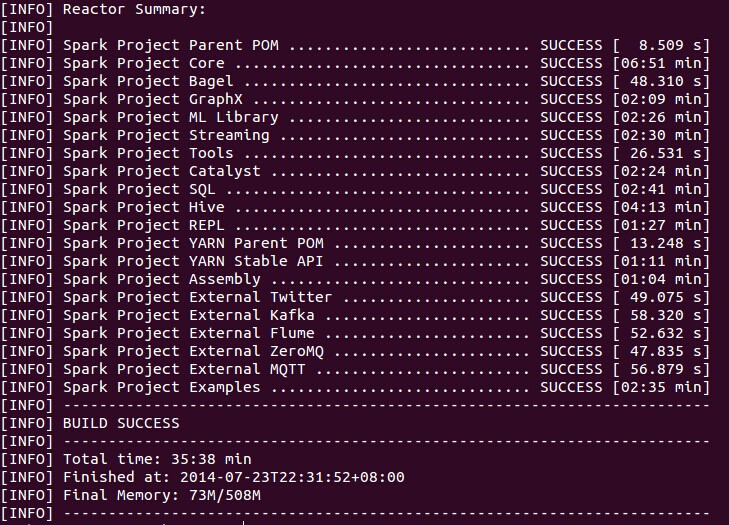
另外,这篇文章的编译讲得也很详细,也可以参考:http://mmicky.blog.163.com/blog/static/1502901542014312101657612/
以及文章 http://www.cnblogs.com/hseagle/p/3732492.html
Spark源码和编译后的源码、部署包我分享在: http://pan.baidu.com/s/1c0y7JKs 提取密码: ccvy
Spark-1.0.1 的make-distribution.sh编译、SBT编译、Maven编译 三种编译方法的更多相关文章
- spark提交任务的三种的方法
在学习Spark过程中,资料中介绍的提交Spark Job的方式主要有三种: 第一种: 通过命令行的方式提交Job,使用spark 自带的spark-submit工具提交,官网和大多数参考资料都是已这 ...
- Spark 1.0.0 横空出世 Spark on Yarn 部署(Hadoop 2.4)
就在昨天,北京时间5月30日20点多.Spark 1.0.0最终公布了:Spark 1.0.0 released 依据官网描写叙述,Spark 1.0.0支持SQL编写:Spark SQL Progr ...
- spark 2.0.0集群安装与hive on spark配置
1. 环境准备: JDK1.8 hive 2.3.4 hadoop 2.7.3 hbase 1.3.3 scala 2.11.12 mysql5.7 2. 下载spark2.0.0 cd /home/ ...
- [b0006] Spark 2.0.1 伪分布式搭建练手
环境: 已经安装好: hadoop 2.6.4 yarn 参考: [b0001] 伪分布式 hadoop 2.6.4 准备: spark-2.0.1-bin-hadoop2.6.tgz 下载地址: ...
- hive on spark (spark2.0.0 hive2.3.3)
hive on spark真的很折腾人啊!!!!!!! 一.软件准备阶段 maven3.3.9 spark2.0.0 hive2.3.3 hadoop2.7.6 二.下载源码spark2.0.0,编译 ...
- Spark 2.0
Apache Spark 2.0: Faster, Easier, and Smarter http://blog.madhukaraphatak.com/categories/spark-two/ ...
- Spark 1.0 开发环境构建:maven/sbt/idea
因为我原来对maven和sbt都不熟悉,因此使用两种方法都编译了一下.下面记录一下编译时候遇到的问题.然后介绍一下如果使用IntelliJ IDEA 13.1构建开发环境. 首先准备java环境和sc ...
- APACHE SPARK 2.0 API IMPROVEMENTS: RDD, DATAFRAME, DATASET AND SQL
What’s New, What’s Changed and How to get Started. Are you ready for Apache Spark 2.0? If you are ju ...
- Apache Spark 3.0 将内置支持 GPU 调度
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU.FPGA 或 TPU 来加速计算.在 Apache Hadoop 3.1 版本里面 ...
随机推荐
- js事件处理机制
一.事件处理程序 a. DOM0级事件处理程序,被认为是元素的方法. var btn=document.getElementById('myBtn'); btn.onclick=functio ...
- php部分--session的三种用法
一.在不同页面之间显示用户的信息 二.控制登录 1.登录页面 <body> <form action="loginchuli.php" method=" ...
- 几个排序算法的python实现
几个排序算法 几个排序算法 几个排序算法 冒泡排序 选择排序 插入排序 快速排序 quick sort 冒泡排序 冒泡排序是比较简单的排序方法,它的思路是重复的走过要排序的序列,一次比较两个元 ...
- Mac下Nginx环境配置
环境信息: Mac OS X 10.11.1 Homebrew 0.9.5 正文 一.安装 Nginx 终端执行: brew search nginx brew install nginx 当前版本 ...
- latch: cache buffers chains故障处理总结(转载)
一大早就接到开发商的电话,说数据库的CPU使用率为100%,应用相应迟缓.急匆匆的赶到现场发现进行了基本的检查后发现是latch: cache buffers chains 作祟,处理过程还算顺利,当 ...
- ASP.NET Web API 学习【转】
转自:http://www.cnblogs.com/babycool/p/3922738.html 来看看对于一般前台页面发起的get和post请求,我们在Web API中要如何来处理. 这里我使用J ...
- iOS中如何让TextView和TextField控件支持return键收起输入法
TextView和TextField控件是iOS中负责接收用户输入的控件,那当用户输入完成时怎么收起面板呢? 1.TextView和TextField控件获得焦点之后的第一反应就是弹出输入法面板: 2 ...
- 【支付专区】之对字符串数据进行Base64位加密,解密
加密,解密 String pwd="测试"; byte[] bytes = pwd.getBytes("UTF-8"); //加密 String pwdNew= ...
- src与href属性的区别
src和href之间存在区别,能混淆使用.src用于替换当前元素,href用于在当前文档和引用资源之间确立联系. src是source的缩写,指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在 ...
- 剑指offer习题集2
1.把数组排成最小的数 class Solution { public: static bool compare(const string& s1, const string& s2) ...